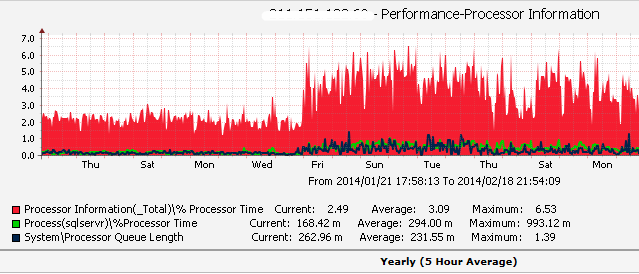
對兩個表進行信息同步時,有三步操作要進行。首先要處理任何需要插入目標數據表的新行。其次是處理需要更新的已存在的行。最後要刪除不再使用的舊行。這個過程中需要維護大量重復的邏輯,並可能導致微妙的錯誤。
Bob Beauchemin討論了MERGE語句,這個語句將上述的多個操作步驟合並成單一語句。他給出了如下的例子:
以下是引用的片斷:
merge [target] t
using [source] s on t.id = s.id
when matched then update t.name = s.name, t.age = s.age -- use "rowset1"
when not matched then insert values(id,name,age) -- use "rowset2"
when source not matched then delete; -- use "rowset3"
如你所見,具體操作是根據後面的聯合(join)的解析結果來確定的。在這個例子中,如果目標和源數據表有匹配的行,就實行更新操作。如果沒有,就實行插入或者刪除操作來使目標數據表和源數據表保持一致。
這個新句法的一個美妙之處是它在處理更新時的確定性。在使用標准的UPDATE句法和聯合時,可能有超過一個源行跟目標行匹配。在這種情況下,無法預料更新操作會采用哪個源行的數據。
而當使用MERGE句法時,如果存在多處匹配,它會拋出一個錯誤。這就提醒了開發者,要達到預想的目標,當前的聯合條件還不夠明確。