1.ALTER DATABASE 兼容級別設置
某些數據庫行為與 SQL Server 版本有關,通過 ALTER DATABASE 下面新增的語法,可以設置數據庫兼容級別,它取代了以前版本中的 sp_dbcmptlevel 過程。
ALTER DATABASE database_name
SET COMPATIBILITY_LEVEL = { 80 | 90 | 100 }
可用的設置值80、90、100分別代表 SQL Server 2000、2005和2008。
2.復合運算符
SQL Server 2008 現在支持如下復合運算符,可執行操作並將變量設置為結果。
運算符 操作 += 將原始值加上一定的量,並將原始值設置為結果 -= 將原始值減去一定的量,並將原始值設置為結果 *= 將原始值乘上一定的量,並將原始值設置為結果 /= 將原始值除以一定的量,並將原始值設置為結果 %= 將原始值除以一定的量,並將原始值設置為余數 &= 對原始值執行位與運算,並將原始值設置為結果 ^= 對原始值執行位異或運算,並將原始值設置為結果 |= 對原始值執行位或運算,並將原始值設置為結果
如:
DECLARE @x1 int = 27;
SET @x1 += 2 ;
SELECT @x1 -- 返回29
3.CONVERT 函數
CONVERT 函數現在允許在二進制和字符十六進制值之間進行轉換。函數語法格式如下:
CONVERT ( data_type [ ( length ) ] , expression [ , style ] )
expression 是被轉換的有效的表達式,data_type 目標數據類型(不能使用別名數據類型),length 指定目標數據類型長度的可選整數,style 指定 CONVERT 函數如何轉換 expression 的整數表達式。
如果 expression 為 binary(n)、varbinary(n)、char(n) 或 varchar(n),則 style 可以為下表中顯示的值之一。
值 輸出 0(默認值) 將 ASCII 字符轉換為二進制字節,或者將二進制字節轉換為 ASCII 字符。每個字符或字節按照 1:1 進行轉換。
如果 data_type 為二進制類型,則會在結果左側添加字符 0x。
1, 2 對於 style 1,將在轉換後的結果左側添加字符 0x。作為要轉換的二進制表達式,字符 0x 必須為表達式中的前兩個字符。在style為2的情況下,生成的二進制值不會包含字符 0x。作為要轉換的二進制表達式,也不需要在字符前面包含字符 0x。
如果 data_type 為二進制類型,則表達式必須為字符表達式。
如果轉換後的表達式長度大於 data_type 長度,則會在右側截斷結果。
如果固定長度 data_types 大於轉換後的結果,則會在結果右側添加零。
如果 data_type 為字符類型,則表達式必須為二進制表達式。每個二進制字符均轉換為兩個十六進制字符。如果轉換後的表達式長度大於 data_type 長度,則會在右側截斷結果。
如果 data_type 為固定大小的字符類型,並且轉換後的結果長度小於其 data_type 長度,則會在轉換後的表達式右側添加空格,以使十六進制數字的個數保持為偶數。
參考下面的示例代碼:
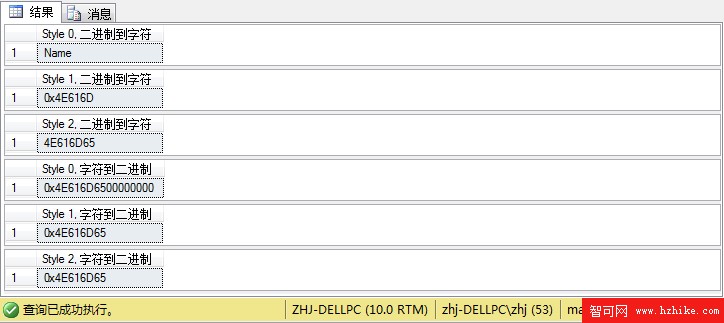
--轉換二進制值 0x4E616d65 到一個字符值
SELECT CONVERT(char(8), 0x4E616d65, 0) AS 'Style 0, 二進制到字符'
--下面的示例演示了 Style 為 1 的情況下,如何強行截斷結果值。
--產生的結果值由於包含字符 0x ,所以被截斷
SELECT CONVERT(char(8), 0x4E616d65, 1) AS 'Style 1, 二進制到字符'
--下面的示例演示了 Style 為 2 的情況下,沒有截斷結果值。
--這是因為 0x 字符未包含在結果中
SELECT CONVERT(char(8), 0x4E616d65, 2) AS 'Style 2, 二進制到字符'
--轉換字符值 Name 到一個二進制值
SELECT CONVERT(binary(8), 'Name', 0) AS 'Style 0, 字符到二進制'
SELECT CONVERT(binary(4), '0x4E616D65', 1) AS 'Style 1, 字符到二進制'
SELECT CONVERT(binary(4), '4E616D65', 2) AS 'Style 2, 字符到二進制'
結果如下:
4.日期和時間功能
DATEPART ( datepart , date )函數用於返回 date中的指定 datepart 的整數。如:
SELECT DATEPART(YEAR,'2007-05-10') --返回2007
SQL Server 2008 包含對 ISO 周-日期系統的支持,即周的編號系統。每周都與該周內星期四所在的年份關聯。例如,2004 年第 1 周 (2004W01) 從 2003 年 12 月 29 日星期一到 2004 年 1 月 4 日星期天。一年中最大的周數可能為 52 或 53。這種編號方式通常用於歐洲國家,但其他國家/地區很少用到。
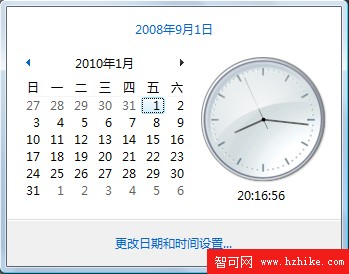
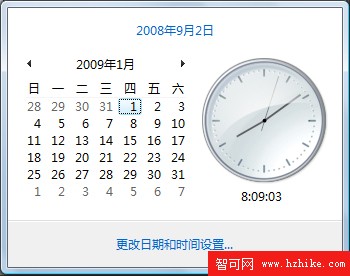
下面分別是2010年和2009年1月份的日歷。由於2010年第一個星期中的星期四是2010-1-7日,所以2010-1-3日及之前的日期會作為2009年的第53個星期,而不是2010年的第一個星期。而對於2009年1月份的日歷,由於星期四是2009-1-1,所以該星期會作為2009年的第一個星期。當然,該星期也包含了2008-12-28至31的4天。
參考下面的代碼:
SELECT DATEPART(ISO_WEEK,'2010-1-3') --返回53
SELECT DATEPART(ISO_WEEK,'2010-1-4') --返回1
SELECT DATEPART(ISO_WEEK,'2009-1-1') --返回1
5.ROLLUP、CUBE 和GROUPING SETS
在SQL Server 2008之前,進行分組統計匯總,可以在GROUP BY子句中使用WITH ROLLUP和WITH CUBE參數。ROLLUP指定在結果集內不僅包含由GROUP BY提供的行,還包含匯總行。按層次結構順序,從組內的最低級別到最高級別匯總組。而CUBE參數則在使用ROLLUP參數所返回結果集的基礎上,再將每個可能的組和子組組合在結果集內返回。
例如,假設dbo.T1表中存在下列數據:
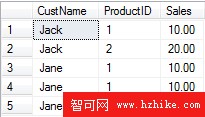
執行下面的查詢語句:
SELECT CustName,ProductID,SUM(Sales) AS 'SalesTotal'
FROM dbo.T1
GROUP BY CustName,ProductID
WITH CUBE
ORDER BY CustName,ProductID;
SELECT CustName,ProductID,SUM(Sales) AS 'SalesTotal'
FROM dbo.T1
GROUP BY CustName,ProductID
WITH ROLLUP
ORDER BY CustName,ProductID;
得到下面的結果集合,可以看出,使用WITH CUBE多出了對子組ProductID的兩行匯總。
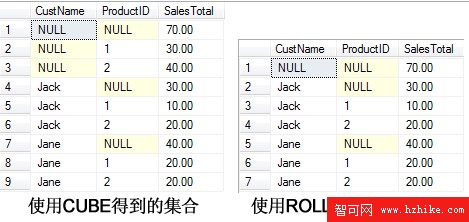
而在SQL Server 2008中,GROUPING SETS、ROLLUP 和 CUBE 運算符已添加到 GROUP BY 子句中。不再推薦使用不符合 ISO 的 WITH ROLLUP、WITH CUBE 和 ALL 語法。在SQL Server 2008中,可以將上面的WITH CUBE語句改寫為如下的形式:
SELECT CustName,ProductID,SUM(Sales) AS 'SalesTotal'
FROM dbo.T1
GROUP BY CUBE(CustName,ProductID)
ORDER BY CustName,ProductID;
如果不需要獲得由完備的 ROLLUP 或 CUBE 運算符生成的全部分組,則可以使用 GROUPING SETS 僅指定所需的分組。例如,下面的語句將得到分別按CustName和ProductID分組匯總結果集的並集。
SELECT CustName,ProductID,SUM(Sales) AS 'SalesTotal'
FROM dbo.T1
GROUP BY GROUPING SETS(CustName,ProductID)
ORDER BY CustName,ProductID;
結果集如下:
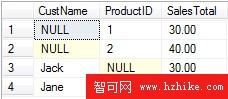
上面的語句等同於下面的UNION ALL語句:
SELECT CustName,NULL AS ProductID,SUM(Sales) AS 'SalesTotal'
FROM dbo.T1
GROUP BY CustName
UNION ALL
SELECT NULL AS CustName,ProductID,SUM(Sales) AS 'SalesTotal'
FROM dbo.T1
GROUP BY ProductID
6.MERGE 語句
在 SQL Server 2008 中,可以使用 MERGE 語句在一條語句中根據與源表聯接的結果對目標表執行 INSERT、UPDATE 或 DELETE 操作。如:使用一個語句有條件地在單個目標表中插入或更新行,如果目標表中存在相應行,則更新一個或多個列;否則,會將數據插入新行。使用該語句還可以同步兩個表,根據與源數據的差別在目標表中插入、更新或刪除行。
MERGE 語法包括如下五個主要子句:
MERGE 子句用於指定作為插入、更新或刪除操作目標的表或視圖。
USING 子句用於指定要與目標聯接的數據源。
ON 子句用於指定決定目標與源的匹配位置的聯接條件。
WHEN 子句用於根據 ON 子句的結果指定要執行的操作。
OUTPUT 子句針對更新、插入或刪除的目標對象中的每一行返回一行。
其完整的語法格式如下:
[ WITH <common_table_expression> [,...n] ]
MERGE
[ TOP ( expression ) [ PERCENT ] ]
[ INTO ] target_table [ WITH ( <merge_hint> ) ] [ [ AS ] table_alias ]
USING <table_source>
ON <merge_search_condition>
[ WHEN MATCHED [ AND <clause_search_condition> ]
THEN <merge_matched> ]
[ WHEN NOT MATCHED [ BY TARGET ] [ AND <clause_search_condition> ]
THEN <merge_not_matched> ]
[ WHEN NOT MATCHED BY SOURCE [ AND <clause_search_condition> ]
THEN <merge_matched> ]
[ <output_clause> ]
[ OPTION ( <query_hint> [ ,...n ] ) ]
使用下面的語句創建兩個表:
USE AdventureWorks;
GO
IF OBJECT_ID (N'dbo.Purchases', N'U') IS NOT NULL
DROP TABLE dbo.Purchases;
GO
CREATE TABLE dbo.Purchases (
ProductID int, CustomerID int, PurchaseDate datetime,
CONSTRAINT PK_PurchProdID PRIMARY KEY(ProductID,CustomerID));
GO
INSERT INTO dbo.Purchases VALUES(707, 11794, '20060821'),
(707, 15160, '20060825'),(708, 18529, '20060821'),
(712, 19072, '20060821'),(870, 15160, '20060823'),
(870, 11927, '20060824'),(870, 18749, '20060825');
GO
IF OBJECT_ID (N'dbo.FactBuyingHabits', N'U') IS NOT NULL
DROP TABLE dbo.FactBuyingHabits;
GO
CREATE TABLE dbo.FactBuyingHabits (
ProductID int, CustomerID int, LastPurchaseDate datetime,
CONSTRAINT PK_FactProdID PRIMARY KEY(ProductID,CustomerID));
GO
INSERT INTO dbo.FactBuyingHabits VALUES(707, 11794, '20060814'),
(707, 18178, '20060818'),(864, 14114, '20060818'),
(870, 17151, '20060818'),(870, 15160, '20060817'),
(871, 21717, '20060817'),(871, 21163, '20060815'),
(871, 13350, '20060815'),(873, 23381, '20060815');
GO
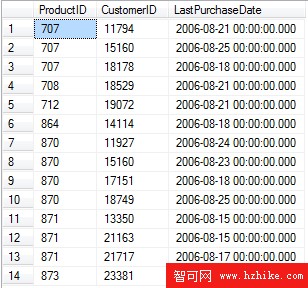
兩個表中的數據如下圖所示:
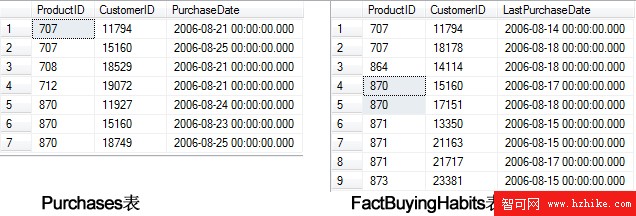
請注意,這兩個表中有兩個共有的產品-客戶行:客戶 11794 購買了產品 707,客戶 15160 購買了產品 870。對於這些行,可以使用 WHEN MATCHED THEN 子句利用 Purchases 中這些購買記錄的日期來更新 FactBuyingHabits。我們可以使用 WHEN NOT MATCHED THEN 子句將所有其他行插入 FactBuyingHabits。參考下面的語句:
MERGE dbo.FactBuyingHabits AS Target
USING (SELECT CustomerID, ProductID, PurchaseDate FROM dbo.Purchases) AS Source
ON (Target.ProductID = Source.ProductID AND Target.CustomerID = Source.CustomerID)
WHEN MATCHED THEN
UPDATE SET Target.LastPurchaseDate = Source.PurchaseDate
WHEN NOT MATCHED BY TARGET THEN
INSERT (CustomerID, ProductID, LastPurchaseDate)
VALUES (Source.CustomerID, Source.ProductID, Source.PurchaseDate)
OUTPUT $action, Inserted.*, Deleted.*;
$action用於在 OUTPUT 子句中指定一個 nvarchar(10) 類型的列,列的值是代表所執行操作的INSERT、UPDATE或DELETE。Inserted.*和Deleted.*分別用於指定返回所有插入行的列和刪除行的列。如果要指定具體的列,可以使用Inserted.ProductID這樣的命名方式。
上面語句的輸出結果如下:
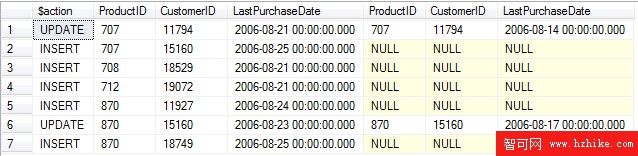
再查詢FactBuyingHabits表,可以看到被更新和插入後的結果,如下所示:
7.SQL 依賴關系報告
SQL Server 2008 引入了新的目錄視圖和系統函數用以提供一致可靠的 SQL 依賴關系報告。所謂依賴關系,通俗的講:存儲過程1需要使用存儲過程2提供的結果,它們之間就是一種依賴關系。可以使用 sys.sql_expression_dependencies、sys.dm_sql_referencing_entities 和 sys.dm_sql_referenced_entitIEs 來報告架構綁定和非架構綁定對象的跨服務器、跨數據庫和數據庫 SQL 依賴關系。
下例將創建一個表、一個視圖和三個存儲過程。這些對象將用在後面的查詢中以演示如何報告依賴關系信息。可看到 MyView 和 MyProc3 均引用 Mytable。MyProc1 引用 MyVIEw,而 MyProc2 引用 MyProc1。
USE AdventureWorks;
GO
-- Create entitIEs
CREATE TABLE dbo.MyTable (c1 int, c2 varchar(32));
GO
CREATE VIEW dbo.MyVIEw
AS SELECT c1, c2 FROM dbo.MyTable;
GO
CREATE PROC dbo.MyProc1
AS SELECT c1 FROM dbo.MyVIEw;
GO
CREATE PROC dbo.MyProc2
AS EXEC dbo.MyProc1;
GO
CREATE PROC dbo.MyProc3
AS SELECT * FROM AdventureWorks.dbo.MyTable;
EXEC dbo.MyProc2;
GO
下面的示例查詢 sys.sql_expression_dependencIEs 目錄視圖以返回由 MyProc3 引用的實體。
USE AdventureWorks;
GO
SELECT OBJECT_NAME(referencing_id) AS referencing_entity_name
,referenced_server_name AS server_name
,referenced_database_name AS database_name
,referenced_schema_name AS schema_name
, referenced_entity_name
FROM sys.sql_expression_dependencIEs
WHERE referencing_id = OBJECT_ID(N'dbo.MyProc3');
GO
下面是結果集:
referencing_entity server_name database_name schema_name referenced_entity
------------------ ----------- ------------- ----------- -- ---------------
MyProc3 NULL NULL dbo MyProc2
MyProc3 NULL AdventureWorks dbo MyTable
上面的查詢返回了兩個在 MyProc3 定義中按名稱引用的實體。服務器名稱為 NULL,因為被引用實體沒有使用有效的由四部分組成的名稱指定。返回的結果中顯示了 MyTable 的數據庫名稱,因為在存儲過程中是使用由三部分組成的有效名稱定義此實體的。
8.表值參數
數據庫引擎引入了可以引用用戶定義表類型的新參數類型。表值參數可以將多個數據行發送到 SQL Server 語句或例程(比如存儲過程或函數),而不用創建臨時表。表值參數具有更高的靈活性,在某些情況下,可比臨時表或其他傳遞參數列表的方法提供更好的性能。表值參數具有以下優勢:
首次從客戶端填充數據時,不獲取鎖。
提供簡單的編程模型。
允許在單個例程中包括復雜的業務邏輯。
減少到服務器的往返。
可以具有不同基數的表結構。
是強類型。
使客戶端可以指定排序順序和唯一鍵。
與其他參數一樣,表值參數的作用域也是存儲過程、函數或動態 Transact-SQL 文本。同樣,表類型變量也與使用 DECLARE 語句創建的其他任何局部變量一樣具有作用域。
與BULK INSERT操作相比,頻繁使用表值參數將比大型數據集要快。大容量操作的啟動開銷比表值參數大,與之相比,表值參數在插入數目少於 1000 的行時具有很好的執行性能。
下面是SQL Server幫助中的示例,演示了如何執行以下操作:創建表值參數類型,聲明變量來引用它,填充參數列表,然後將值傳遞到存儲過程。
USE AdventureWorks;
GO
/* 創建一個table類型 */
CREATE TYPE LocationTableType AS TABLE
( LocationName VARCHAR(50)
, CostRate INT );
GO
/* 創建一個存儲過程,用於從表值參數接收數據 */
CREATE PROCEDURE usp_InsertProductionLocation
@TVP LocationTableType READONLY
AS
SET NOCOUNT ON
INSERT INTO [AdventureWorks].[Production].[Location]
([Name]
,[CostRate]
,[Availability]
,[ModifIEdDate])
SELECT *, 0, GETDATE()
FROM @TVP;
GO
/* 定義一個引用表值類型的變量 */
DECLARE @LocationTVP
AS LocationTableType;
/* 添加數據到表值變量 */
INSERT INTO @LocationTVP (LocationName, CostRate)
SELECT [Name], 0.00
FROM
[AdventureWorks].[Person].[StateProvince];
/* 傳遞表值變量數據給存儲過程 */
EXEC usp_InsertProductionLocation @LocationTVP;
GO
9.Transact-SQL 行構造函數
增強後的 Transact-SQL 可以允許將多個值插入單個 INSERT 語句中,語法比較簡單。參考下面的代碼:
/* 創建一個表 */
CREATE TABLE dbo.T1(
CustName char(20) ,
ProductID int ,
MadeFrom char(20) ,
Sales numeric(20, 2)
)
/* 插入2行數據 */
INSERT INTO dbo.T1
VALUES ('Jane',1,'China',20.00),
('Jack',2,'USA',10.00)