游標、臨時表、觸發器、COLLATE等等...
無可厚非、這些都是好東西
我為什麼今天要花時間來寫這些東西呢?
是因為我發現慢慢的很多人用久了這些東西之後會形成一種習慣,不管解決什麼問題動不動都會把它們搬出來
由此我看到了很多漂亮的代碼在性能效率面前卻顯得不那麼優秀
好了廢話不多說開始進入正題吧
今天的案例
場景:
需要通過用戶輸入的姓名關鍵字來搜索用戶。用戶輸入關鍵字'x'來搜索用戶(數據來源於表[Name字段中]或內存[List<UserInfo>]中)
要求:
得到的結果排序應為:
x
xia
xiao
yx
即:
各位大俠能否給出一套c#與SQL Server(2008)的解決方案?
補充:
如果能一起解決中文問題最好,如搜索'x'
得到的結果排序應為:
x
xiani
夏榮
肖小笑
楊星
即將漢字的拼音首字母納入在內,不知sqlserver是否支持這一特性的搜索?
感謝[學習的腳步]這位網友提出來的問題
其實要解決這個問題不難,無非就是漢字轉拼音首字母
---------------------------------------------------------------------------------------------
先給出解決方案一

 代碼
代碼
---------------------准備工作 開始-------------------------------
if object_id('zhuisuos')is not null
drop table zhuisuos
go
create table zhuisuos
(
name varchar(100)
)
insert into zhuisuos values('追索')
insert into zhuisuos values('追索2')
insert into zhuisuos values('xia')
insert into zhuisuos values('dxc')
insert into zhuisuos values('x')
insert into zhuisuos values('xx')
insert into zhuisuos values('xiani')
insert into zhuisuos values('yx')
insert into zhuisuos values('夏榮')
insert into zhuisuos values('肖小笑')
insert into zhuisuos values('楊星')
go
-------------------------------------------------------------------------------
--建立漢字轉拼音首字母函數
if object_id('fn_getpy1')is not null
drop function fn_getpy1
go
GO
create function [dbo].fn_getpy1
(@str nvarchar(4000))
returns nvarchar(4000)
as
begin
declare @str_len int,@result nvarchar(4000)
declare @zhuisuo table
(firstspell nchar(1) collate Chinese_PRC_CI_AS,
letter nchar(1))
set @str_len=len(@str)
set @result= ' '
insert into @zhuisuo
(firstspell,letter)
select '吖 ', 'A ' union all select '八 ', 'B ' union all
select '嚓 ', 'C ' union all select '咑 ', 'D ' union all
select '妸 ', 'E ' union all select '發 ', 'F ' union all
select '旮 ', 'G ' union all select '铪 ', 'H ' union all
select '丌 ', 'J ' union all select '咔 ', 'K ' union all
select '垃 ', 'L ' union all select '嘸 ', 'M ' union all
select '拏 ', 'N ' union all select '噢 ', 'O ' union all
select '妑 ', 'P ' union all select '七 ', 'Q ' union all
select '呥 ', 'R ' union all select '仨 ', 'S ' union all
select '他 ', 'T ' union all select '屲 ', 'W ' union all
select '夕 ', 'X ' union all select '丫 ', 'Y ' union all
select '帀 ', 'Z '
while @str_len> 0
begin
select top 1 @result=letter+@result,@str_len=@str_len-1
from @zhuisuo
where firstspell <=substring(@str,@str_len,1)
order by firstspell desc
if @@rowcount=0
select @result=substring(@str,@str_len,1)+@result,@str_len=@str_len-1
end
return(@result)
end
---------------------准備工作 結束-------------------------------
--正式查詢
declare @str varchar(10)
set @str='x'
create table #result
(name varchar(100) null,id int null,lens int null)
insert into #result
select name,1,len(name) from zhuisuos
where name like @str+'%'
insert into #result
select name,2,len(name) from zhuisuos
where name like '%'+@str+'%' and name not like @str+'%'
insert into #result
select name,3,len(name) from zhuisuos
where dbo.fn_getpy1 (name) like @str+'%' and name not like @str+'%' and name not like '%'+@str+'%'
insert into #result
select name,4,len(name) from zhuisuos
where dbo.fn_getpy1 (name) like '%'+@str+'%' and dbo.fn_getpy1 (name) not like @str+'%'
and name not like @str+'%' and name not like '%'+@str+'%'
select name from #result
order by id,lens
drop table #result
這個解決方案已經滿足查詢要求
其它都不管 我們重點來看看這次寫的這個函數
象這樣的漢字轉拼音函數在網上一搜一大把 今天我就要舉例幾個方案讓大家對優化及開銷有個清楚的概念
解決方案一寫的函數實在是太糟糕了(以上及接下來舉出的案例並無冒犯任何雷同及原創代碼之意,還請多多包涵)
為什麼這麼說呢
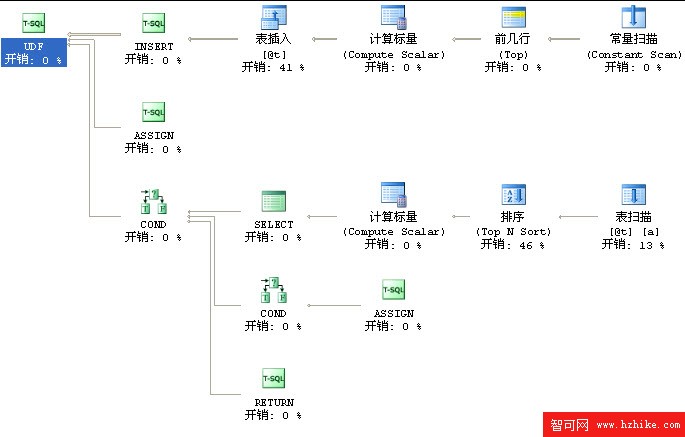
這是它的執行計劃
它用了臨時表並且排序
表插入開銷0.01 表掃描開銷0.003 表排序0.011
估計總開銷0.0246
實際執行:我拿1萬行數據調用此函數花了我20幾秒、一個查詢操作你願意等20多秒嗎
所以看到這樣的執行計劃實在很抱歉
解決方案二
代碼
create function [dbo].[fn_getpy2](@Str varchar(500)='')
returns varchar(500)
as
begin
declare @strlen int,@return varchar(500),@ii int
declare @n int,@c char(1),@chn nchar(1)
select @strlen=len(@str),@return='',@ii=0
set @ii=0
while @ii<@strlen
begin
select @ii=@ii+1,@n=63,@chn=substring(@str,@ii,1)
if @chn>'z'
select @n = @n +1
,@c = case chn when @chn then char(@n) else @c end
from(
select top 27 * from (
select chn = '吖'
union all select '八'
union all select '嚓'
union all select '咑'
union all select '妸'
union all select '發'
union all select '旮'
union all select '铪'
union all select '丌' --because have no 'i'
union all select '丌'
union all select '咔'
union all select '垃'
union all select '嘸'
union all select '拏'
union all select '噢'
union all select '妑'
union all select '七'
union all select '呥'
union all select '仨'
union all select '他'
union all select '屲' --no 'u'
union all select '屲' --no 'v'
union all select '屲'
union all select '夕'
union all select '丫'
union all select '帀'
union all select @chn) as a
order by chn COLLATE Chinese_PRC_CI_AS
) as b
else set @c=@chn
set @return=@return+@c
end
return(@return)
end
這是很聰明的一個解決方案,它巧妙的運用了排序使其利用序號位置int ASCII 代碼轉換為字母
這個方案能很漂亮的將漢字轉為拼音
那麼我們來看看它的執行計劃是怎樣的
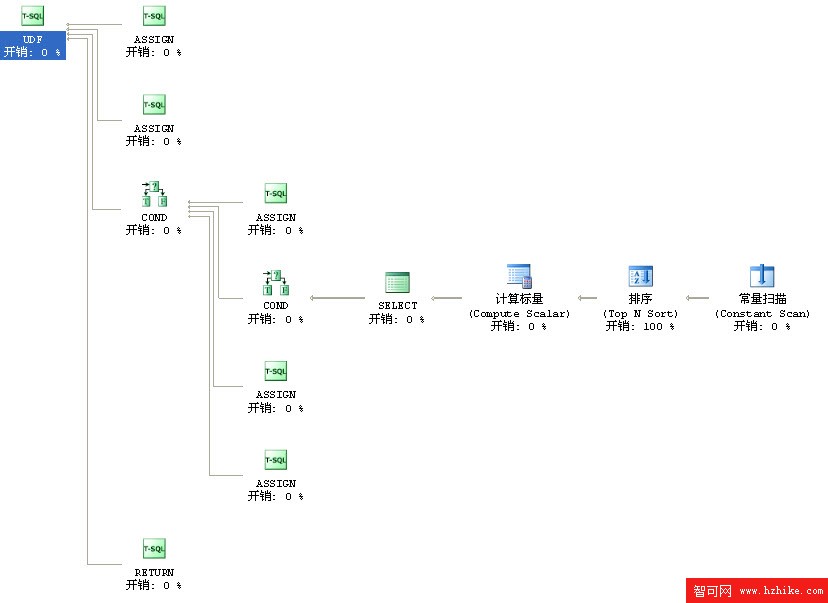
看完之後也不得不為這個漂亮之舉感到惋惜
排序開銷0.01156
總估計開銷大概0.01159
實際執行:我拿1萬行數據調用此函數花了10幾秒
當然它比解決方案一效率要高出一倍之多
解決方案三
既然解決方案一大部分開銷花在表插入及排序上面那麼我們把裡面的臨時表拿出來新建一個物理表並且建上主鍵讓它聚集索引會怎樣呢
代碼
create function [dbo].[fn_getpy3]
(@str nvarchar(4000))
returns nvarchar(4000)
as
begin
declare @str_len int,@result nvarchar(4000)
set @str_len=len(@str)
set @result= ' '
while @str_len> 0
begin
select top 1 @result=letter+@result,@str_len=@str_len-1
from transition_spell
where firstspell <=substring(@str,@str_len,1)
order by firstspell desc
if @@rowcount=0
select @result=substring(@str,@str_len,1)+@result,@str_len=@str_len-1
end
return(@result)
end
物理建表代碼我就沒有提供了 直接參考解決方案一臨時表
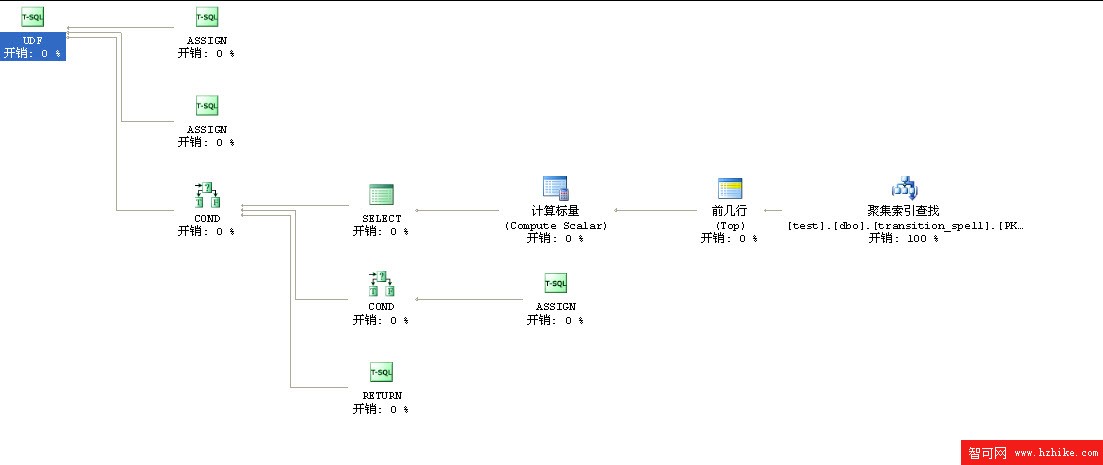
果然,此方案總開銷只花了0.003
實際執行:我拿1萬行數據調用此函數花了4~5秒左右
沒有了臨時表,沒有了插入,沒有了排序這個簡單的方法比漂亮的解決方案二效率更高
---------------------------------------------------------------------------------------------------------------
現在仔細想想 有沒有什麼方法能讓它連聚集索引都不需要呢 這樣豈不連0.003的開銷都沒有了?
剛才寫出了解決方案四就實現了這一點
代碼
create function [dbo].[fn_getpy4]
(@str nvarchar(4000))
returns nvarchar(4000)
as
begin
declare @str_len int,@result nvarchar(4000) ,@crs nvarchar(1)
set @str_len=len(@str)
set @result= ' '
while @str_len> 0
begin
set @crs=substring(@str,@str_len,1)
-- @result=b+@result
select @str_len=@str_len-1,@result=
case when @crs>='吖' and @crs<'八'then 'A'
when @crs>='八' and @crs<'嚓' then 'B'
when @crs>='嚓' and @crs<'咑' then 'C'
when @crs>='咑' and @crs<'妸' then 'D'
when @crs>='妸' and @crs<'發' then 'E'
when @crs>='發' and @crs<'旮' then 'F'
when @crs>='旮' and @crs<'铪' then 'G'
when @crs>='铪' and @crs<'丌' then 'H'
when @crs>='丌' and @crs<'咔' then 'J'
when @crs>='咔' and @crs<'垃' then 'K'
when @crs>='垃' and @crs<'嘸' then 'L'
when @crs>='嘸' and @crs<'拏' then 'M'
when @crs>='拏' and @crs<'噢' then 'N'
when @crs>='噢' and @crs<'妑' then 'O'
when @crs>='妑' and @crs<'七' then 'P'
when @crs>='七' and @crs<'呥' then 'Q'
when @crs>='呥' and @crs<'仨' then 'R'
when @crs>='仨' and @crs<'他' then 'S'
when @crs>='他' and @crs<'屲' then 'T'
when @crs>='屲' and @crs<'夕' then 'W'
when @crs>='夕' and @crs<'丫' then 'X'
when @crs>='丫' and @crs<'帀' then 'Y'
when @crs>='帀' then 'Z'
else @crs end+@result
end
return(@result)
end
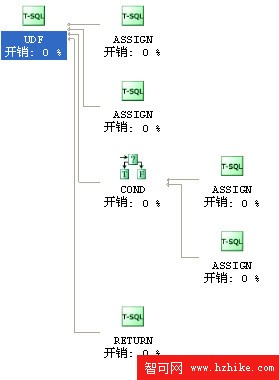
估計運算開銷 0
實際執行:1萬行數據調用此函數只花了1~2秒
這樣就滿足了?
其實解決方案四還有優化的空間、不過這次僅僅只是代碼及邏輯上的優化
解決方案五
代碼
create function [dbo].[fn_getpy5]
(@str nvarchar(4000))
returns nvarchar(4000)
as
begin
declare @str_len int,@result nvarchar(4000) ,@crs nvarchar(1)
set @str_len=len(@str)
set @result= ' '
while @str_len> 0
begin
set @crs=substring(@str,@str_len,1)
select @str_len=@str_len-1,@result=
case
when @crs>='帀' then 'Z'
when @crs>='丫' then 'Y'
when @crs>='夕' then 'X'
when @crs>='屲' then 'W'
when @crs>='他' then 'T'
when @crs>='仨' then 'S'
when @crs>='呥' then 'R'
when @crs>='七' then 'Q'
when @crs>='妑' then 'P'
when @crs>='噢' then 'O'
when @crs>='拏' then 'N'
when @crs>='嘸' then 'M'
when @crs>='垃' then 'L'
when @crs>='咔' then 'K'
when @crs>='丌' then 'J'
when @crs>='铪' then 'H'
when @crs>='旮' then 'G'
when @crs>='發' then 'F'
when @crs>='妸' then 'E'
when @crs>='咑' then 'D'
when @crs>='嚓' then 'C'
when @crs>='八' then 'B'
when @crs>='吖' then 'A'
else @crs end+@result
end
return(@result)
end
估計運算開銷 0
實際執行:1萬行數據調用此函數0~1秒
----------------------------------------------------------------------------------------------------------
好了,這些方案我都寫完了、簡單的總結一下
其實不管你寫了多少年的SQL 有的時候不要養成一種先入為主、自作聰明的觀念
一個優秀的解決方案也許只需最簡單的代碼就能達到理想的效果。
所以謹以此篇文章來希望讓更多的人看到,其實我們生活當中經常所遇到的問題往往都是我們無限的把它復雜化,嚴重化了
退一步海闊天空、換個角度想想吧