Ranking函數

 測試表和測試數據
測試表和測試數據
1 CREATETABLE[Test]下面是四個排序函數統一的示例和結果,可以做一比較。下面的小節來會逐一據此描述每個函數。
2 (
3 [StudentID][bigint]NOTNULL,
4 [ClassID][bigint]NOTNULL,
5 [TestScore][decimal](4, 1) NOTNULL
6 ) ON[PRIMARY]
7 GO
8
9 INSERTINTO[Test]
10 VALUES (100001,100,90),
11 (100002,100,85.5),
12 (100003,100,80),
13 (100004,100,80),
14 (100005,100,74),
15 (101001,101,94),
16 (101002,101,85.5),
17 (101003,101,85.5)
18 GO
19
Ranking示例
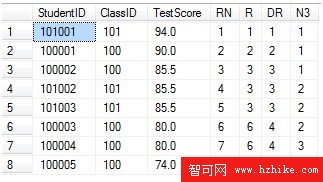
1 SELECT*,
2 ROW_NUMBER() OVER (ORDERBY TestScore DESC) as RN,
3 RANK() OVER (ORDERBY TestScore DESC) as R,
4 DENSE_RANK() OVER (ORDERBY TestScore DESC) as DR,
5 NTILE(3) OVER (ORDERBY TestScore DESC) as N3
6 FROM[TEST]
7 GO
8
 ROW_NUMBER
行號函數。用來生成數據行在結果集中的序號
語法:
ROW_NUMBER( ) OVER ([<partition_by_clause>] <order_by_clause>)
可以利用ROW_NUMBER函數非常便利的實現分頁功能,例如:
ROW_NUMBER
行號函數。用來生成數據行在結果集中的序號
語法:
ROW_NUMBER( ) OVER ([<partition_by_clause>] <order_by_clause>)
可以利用ROW_NUMBER函數非常便利的實現分頁功能,例如:
1 SELECT*, ROW_NUMBER() OVER (ORDERBY TestScore DESC) as RNRANK 排序函數。必須配合over函數,且排序字段值相同的行號一樣,同時隱藏行號會占位。 語法: RANK() OVER ([<partition_by_clause>] <order_by_clause>) 還可以利用partition進行分組排序,例如對每個班級分別按成績排序:
2 FROM[TEST]
3 WHERE RN BETWEEN6AND10
4
 DENSE_RANK
緊湊排序函數。與RANK函數不同的是,當排序字段值相同導致行號一樣時,同時隱藏行號不占位。
語法:
DENSE_RANK ( ) OVER ([<partition_by_clause>] <order_by_clause>)
DENSE_RANK
緊湊排序函數。與RANK函數不同的是,當排序字段值相同導致行號一樣時,同時隱藏行號不占位。
語法:
DENSE_RANK ( ) OVER ([<partition_by_clause>] <order_by_clause>)
從第一個結果集中可以看到,DENSE_RANK得到的行號是3,3,3,4,4,5,而RANK函數得到的3,3,3,6,6,8。 NTILE 分區排序函數。NTILE函數需要一個參數N,這個參數支持bigint。這個函數將結果集等分成N個區,並按排序字段將已排序的記錄依次輪流放入各個區內。最後每個區內會從1開始編號,NTILE函數返回這個編號。 語法: NTILE (integer_expression) OVER ([<partition_by_clause>]< order_by_clause>)
這個函數可以用來按權值均分記錄。 從第一個結果集可以看到被分成了3個區,因為8條記錄不能被平分,所以第3個區只有2條記錄。排序的記錄被依次按第1->2->3->1區的順序分配,最終函數的返回是每個區內記錄的序號。
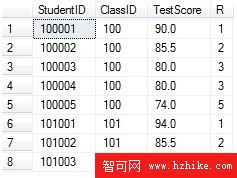
1 SELECT*, RANK() OVER (PARTITION BY ClassID ORDERBY TestScore DESC) as R
2 FROM[Test]
3
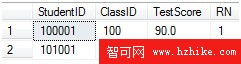
1 ;WITH Test_RN
2 AS
3 (
4 SELECT StudentID, ClassID, TestScore,RANK() OVER (PARTITION BY ClassID ORDERBY TestScore DESC) as RN
5 From Test
6 )
7 Select*FROM Test_RN WHERE RN=1
8
 需要特別提出的是CTE更為強大的一個功能,可以在遞歸中使用。
遞歸 CTE 定義至少必須包含兩個 CTE 查詢定義,一個定位點成員(只能調用一次),一個遞歸成員(可以反復調用,直到查詢不再返回行),使用 UNION ALL連接成一個單獨的CTE。
我們舉一個示例,有一張部門表:
測試表和測試數據
需要特別提出的是CTE更為強大的一個功能,可以在遞歸中使用。
遞歸 CTE 定義至少必須包含兩個 CTE 查詢定義,一個定位點成員(只能調用一次),一個遞歸成員(可以反復調用,直到查詢不再返回行),使用 UNION ALL連接成一個單獨的CTE。
我們舉一個示例,有一張部門表:
測試表和測試數據
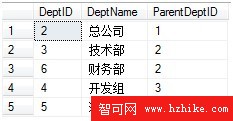
1 CREATETABLE[Dept]我們需要獲取“總公司”下所有部門的信息:
2 (
3 [DeptID][bigint]NOTNULL,
4 [DeptName][nvarchar](50) NOTNULL,
5 [ParentDeptID][bigint]NOTNULL
6 ) ON[PRIMARY]
7 GO
8
9 INSERTINTO[SSIP-SSO].[dbo].[Dept]
10 VALUES
11 (1, '集團', 0),
12 (2, '總公司', 1),
13 (3, '技術部', 2),
14 (4, '開發組', 3),
15 (5, '測試部', 3),
16 (6, '財務部', 2),
17 (7, '分公司', 1),
18 (8, '工程部', 7),
19 (9, '設備組', 8),
20 (10, '客服部', 7)
21 GO
22
遞歸CTE示例
1 ;WITH Dept_Head
2 AS
3 (
4 SELECT DeptID, DeptName, ParentDeptID
5 FROM Dept
6 WHERE DeptName ='總公司'
7 UNIONALL
8 SELECT Dept.DeptID, Dept.DeptName, Dept.ParentDeptID
9 FROM Dept, Dept_Head
10 WHERE Dept.ParentDeptID = Dept_Head.DeptID
11 )
12 Select*FROM Dept_Head
13
 測試表和測試數據
測試表和測試數據
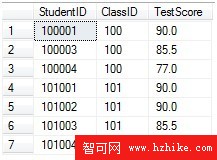
1 CREATETABLE[NewTest]比較源表和目標表發現,有的記錄兩表中一致;有的兩表中部分一致;有的只存在源表中;有的只存在目標表中。我們需要以源表為標准來更新目標表。
2 (
3 [StudentID][bigint]NOTNULL,
4 [TestScore][decimal](4, 1) NOTNULL
5 ) ON[PRIMARY]
6 GO
7
8 INSERTINTO[NewTest]
9 VALUES (100001,90),
10 (100003,85.5),
11 (100004,77),
12 (101001,90),
13 (101002,90),
14 (101003,85.5),
15 (101004,88)
16 GO
17
Merge示例
1 MERGE Test
2 USING NewTest
3 ON Test.StudentID = NewTest.StudentID
4 WHEN MATCHED --記錄兩表匹配
5 THENUPDATESET Test.TestScore = NewTest.TestScore
6 WHENNOT MATCHED --記錄在目標表不存在
7 THENINSERTVALUES (NewTest.StudentID,NewTest.StudentID/1000, NewTest.TestScore)
8 WHENNOT MATCHED BY SOURCE --記錄在源表中不存在
9 THENDELETE
10 ;
11
 還可以帶OUTPUT命令同時獲得MERGE命令中更新的記錄。
OUTPUT $action, Deleted.*, Inserted.*
還可以帶OUTPUT命令同時獲得MERGE命令中更新的記錄。
OUTPUT $action, Deleted.*, Inserted.*