Alter修改表結構對數據存儲的影響
每當我們發現表的結構不正確的話,一般都會使用alter語句對表的結構進行修改,但是alter表結構,會引起一些開銷,但這些開銷,我們很可能就會忽視。但是這些開銷在某些情況下,會給我們的數據庫帶來很大的影響,例如:對於數據的存儲空間,有可能會引起數據庫存儲空間的急劇膨脹。這個有沒有聳人聽聞呢?下面就用例子來說明這一點。
基本的思路與要求:
1、 首先清楚數據行在sql 中是如何存儲的。可以參見:
http://blog.csdn.Net/HEROWANG/archive/2009/11/04/4769430.ASPx
2、在驗證的過程中會使用到兩個命令:
DBCC IND、DBCC PAGE
一、問題:
Use test
go
if object_id('tb') is not null
drop table tb
go
create table tb(id int identity(1,1), col char(985))
insert into [tb]
select 'aaaa' union all
select 'bbbb' union all
select 'cccc' union all
select 'dddd' union all
select 'eeee' union all
select 'ffff' union all
select 'gggg' union all
select 'hhhh' union all
select 'iiii' union all
select 'jjjj'
exec sp_spaceused 'tb'
name
rows
reserved
data
index_size
unused
tb
10
24 KB
16 KB
8 KB
0 KB
所占用的數據頁為2頁,16K,按照數據行在頁面中的存儲方式可以計算出來:
存儲一行數據需用的空間:(7+4+985+2)=998B,
1一個數據頁可以存儲的行數為:8096/998=8.1,所以需要兩個頁面來進行存儲。
下面修改表的結構:
alter table tb
alter column col char(1000)
exec sp_spaceused 'tb'
name
rows
Reserved
data
index_size
unused
tb
10
32 KB
24 KB
8 KB
0 KB
按照數據行在頁面中的存儲方式來計算:
修改後每一行的數據的空間應該為:(7+4+1000+2)=1013B
1一個數據頁可以存儲的行數為:8096/1013=7.99,所以似乎需要兩個頁面來進行存儲,但是實際上修改後占用了3個頁面。那麼問題出在什麼地方呢?原因在於當我們對表的結構進行修改的時候,對數據的存儲產生了很大影響。
二、建立測試環境
Use test
go
if object_id('tb') is not null
drop table tb
go
create table tb(id int identity(1,1), col char(985))
insert into [tb]
select 'aaaa' union all
select 'bbbb' union all
select 'cccc' union all
select 'dddd' union all
select 'eeee' union all
select 'ffff' union all
select 'gggg' union all
select 'hhhh' union all
select 'iiii' union all
select 'jjjj'
三、DBCC IND、DBCC PAGE
1、DBCC IND
DBCC IND
(
['dbname'|dbid], -- 數據庫名或ID
tbname, -- 表名
Printopt|noclustered index_id [, --輸出選項
Partition_num] –-指定分區號,主要兼容2000
)
Printopt : --輸出選項(常用的)
-- noclustered index_id 所有IAM、數據及指定索引的分頁信息
-- -2 所有IAM頁面
-- -1 所有的數據、索引、IAM、行溢出及LOB頁面
-- 0 行內數據、行內數據的IAM頁面
-- 1 聚集索引及所有數據、IAM、LOB頁面
例:DBCC IND(test,tb,0)

注:因為輸出列數比較多,只截取了一部分圖。在這裡主要關注最後一列 pagetype
Pagetype為1,說明該頁為數據頁。
2、DBCC PAGE
DBCC TRACEON(3604)
-- 必須先打開跟蹤3604來讓DBCC PAGE的結果輸出給客戶端。
DBCC PAGE(test,1,114,1)
--1為上圖的pagefid,114為pagepid,
--1為輸出方式,對每記錄行分別輸出緩沖及頁面報頭,行偏離表
結果:(只關注一些在這裡要用到的數據)
PAGE: (1:114)--查看的是數據頁
BUFFER: -- 當前頁面調入內存時,要為了便於管理內存中這個頁面生成的一種結構
PAGE HEADER:--96個字節頁頭部結構
DATA: --數據部分
Slot 0, Offset 0x60, Length 996, DumpStyle BYTE
/**************
Offset 0x60:第一行的偏移量,為前面的96個頭部結構,0x60=96
Length 996:數據的長度:996=7(存儲每行數據需要的空間)+4(第一列的int長度)+985(第二例char的長度)
*************/
00000000: 1000e103 01000000 61616161 20202020
……省略
000003E0: 200200fc
0200:該表有兩列
Slot 1, Offset 0x444, Length 996, DumpStyle BYTE
/**************
Offset 0x444:第二行的偏移量,0x444=1092=996(第一行的長度)+96(頭部結構)
*************/
…… 省略
OFFSET TABLE:/*每一行的偏移量*/
Row - Offset
7 (0x7) - 7068 (0x1b9c)
6 (0x6) - 6072 (0x17b8)
5 (0x5) - 5076 (0x13d4)
4 (0x4) - 4080 (0xff0)
3 (0x3) - 3084 (0xc0c)
2 (0x2) - 2088 (0x828)
1 (0x1) - 1092 (0x444)
0 (0x0) - 96 (0x60)
四、查看修改表結構後的頁面數據
alter table tb
alter column col char(1000)
DBCC IND(test,tb,0)

DBCC TRACEON(3604)
DBCC PAGE(test,1,114,1)
結果:(只關注這裡要用到的數據)
DATA:
Slot 0, Offset 0x60, Length 9, DumpStyle BYTE
00000000: 04af0000 00010002 00 –第一行的數據
Slot 1, Offset 0x69, Length 1996, DumpStyle BYTE
00000000: 1000c907 02000000 62626262 20202020 †........bbbb
……
000003E0: 20626262 62202020 20202020 20202020 † bbbb
……
000007C0: 20202020 20202020 200300f8
觀察這裡的數據,我們會發現這麼兩個問題:
1、第一行數據slot 0 去哪兒了?怎麼只剩下9個字節?
2、第二行數據slot 1,長度 length 為什麼是1996,而不是上面計算的1013呢?
仔細看下第二行的數據,就會發現bbbb出現了兩次,所以1996是在原來的基礎上,再加了1000,即當我們修改表的時候,並不是修改列的空間,而是在每一行後面增加新的一列。所以1996=7+4+985+1000。而倒數第三個字節也說明了這一點:0300 說明該表現在有三列,而不是原來的兩列。
第一個問題暫時保留,接著往下看,就會發現答案
DBCC PAGE(test,1,175,1)(第二個數據頁)
結果:
DATA:
Slot 0, Offset 0x1014, Length 1996, DumpStyle BYTE
1000c907 09000000 69696969 20202020 †........iiii
……
20202020 20202020 200300f8
Slot 1, Offset 0x17e0, Length 1996, DumpStyle BYTE
1000c907 0a000000 6a6a6a6a 20202020 †........jjjj
……
20202020 20202020 200300f8
Slot 2, Offset 0x60, Length 2010, DumpStyle BYTE
3200c907 01000000 61616161 20202020 †2.......aaaa
……
20202020 20202020 200300f8 0100da87 † .......
00047200 00000100 0000
Slot 3, Offset 0x83a, Length 2010, DumpStyle BYTE
3200c907 03000000 63636363 20202020 †2.......cccc
20202020 20202020 200300f8 0100da87
00047200 00000100 0200
OFFSET TABLE:(第二頁的行偏移)
Row - Offset
3 (0x3) - 2106 (0x83a)
2 (0x2) - 96 (0x60)
1 (0x1) - 6112 (0x17e0)
0 (0x0) - 4116 (0x1014)
觀察這裡的數據:上面的第一個問題視乎找到了答案。
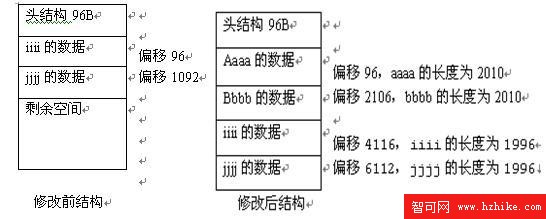
1、 因為第一頁的數據需要分頁,所以就把第一行的數據和第三行數據,放到了第二個頁。
而第一頁的其他兩行數據因為第二頁放不下,所以放在第三頁中。
2、 第三行也就是slot2,存儲的恰好就是從第一頁分出來的aaaa這一行的數據,但是為什麼它的偏移是96,也就是說在第二數據頁的第一行存儲的是aaaa,而不是原來的iiii。
原因:當我們修改表的結構,會把原來的數據向後移動,這樣原來的空間就空出來。這個時候,把從第一頁分離出來的數據,就寫到第二頁裡面,這樣,aaaa恰好寫在第一頁,所以他的偏移為96,而原來的iiii和jjjj反而不在原來的地方。
如下圖所示:
接著往下看:
DBCC PAGE(test,1,45,1)
DATA:
Slot 0, Offset 0x452, Length 2010, DumpStyle BYTE
00000000: 3200c907 05000000 65656565 20202020 .......eeee
……
000007C0: 20202020 20202020 200300f8 0100da87
000007D0: 00047200 00000100 0400
Slot 1, Offset 0x101e, Length 2010, DumpStyle BYTE
00000000: 3200c907 07000000 67676767 20202020.......gggg
……
000007C0: 20202020 20202020 200300f8 0100da87
000007D0: 00047200 00000100 0600
……
OFFSET TABLE:
Row - Offset (第二頁的行偏移)
1 (0x1) - 4126 (0x101e)
0 (0x0) - 1106 (0x452)
最後的幾個問題:
1、綜合觀察上面的數據,有些行的長度為1996,而有些行的長度為2010。而長度為2010的行,恰好都是從第一頁分出來的數據。然後結合上面的二進制數據,似乎可以得到這個結果:
1)、沒有分離的數據,那麼在後面加上一個新列,長度為修改後的列的長度
1996=7+4+985+1000;
2)、而被分離的數據,除了加上新列,還有在後面加上一個長度為14字節的數據,至於這14個字節做什麼,還尚不清楚。但是其中最後字節數據很有趣:
0000 aaaa
0200 cccc
0400 eeee
0600 ffff
恰好是該數據在原來表中行數,巧合還是有一定意義?
五、總結:
1、修改表的時候,並不是擴充原來列的存儲空間,而是在表的後面增加一個新的列
2、增加了新列後,可能會引起數據的分頁。如果原來的數據不分頁的話,那麼數據就整體向後移動。如果要分頁的話,那麼最後一頁的數據,向後移動後,前面就留有空間,先向最後一頁的空閒空間寫數據,如果寫不下,則分配新的數據頁,來存儲數據。
3、如果數據進行分頁後,對於沒有分離的數據,那麼在後面增加一個新列;對於分離的數據,除了增加一個新列外,還額外增加14字節的數據
這樣,我們基本上就能估算出,修改表,需要的存儲空間上的開銷了(只能是大概的,因為對於分離的數據,在原來的數據頁上還會保留9個字節空間,對於分頁後的數據後面還有14個字節的空間),修改表結構後,存儲每行數據需要的空間為:7+4+1985+2=1998B
這樣每頁最多只能存儲4行數據。
如果該表的數據量很大的話,這個開銷就會很大,我們是不能忽視這個開銷的。
六、解決方法:
上有政策,下有對策。本方法實際的實際可行性,沒有驗證。(沒有生產環境,不好測試)。
1、 新建一張表,當然是修改結構後的表
2、 Insert into tb2 Select * from tb1
3、 重命名tb2為tb1
七、尚存的問題:
1、分頁的行,在原來數據頁中保留的九個字節的作用?
2、分頁的數據,最後加的14個字節的作用
3、最後一頁的行偏移是怎麼偏移的。
4、在前面,我們已經看到,修改表的結構其實是在表的後面增加一個新的列,那麼SQL Server如何知道從哪塊開始讀取該列的數據呢?
要來解答這三個問題,需要從上面的DBCC中取出如下的數據,然後進行分析,就可以知道第一個和第二個問題的答案了。
原來數據的九個字節
分頁後數據的14個字節
04af0000 00010002 00
0100da87 00047200 00000100 0000
04af0000 00010003 00
0100da87 00047200 00000100 0200
042d0000 00010000 00
0100da87 00047200 00000100 0400
042d0000 00010001 00
0100da87 00047200 00000100 0600
1、分頁的行,在原來數據頁中保留的九個字節的作用?
數據分頁以後,在原來的位置會有一個長度為9個字節的數據,這個數據的作用是:給出了數據轉移到什麼位置。第一個字節 04為狀態位;下面四個字節af0000 00為頁面id,轉換為十進制為175,恰好就是aaaa數據轉移後所在的頁面號;下面的兩個字節0100為文件號;最後的兩個字節為數據轉移後的所在數據頁面的slot號。
2、分頁的數據,最後加的14個字節的作用
分頁後數據的14個字節:前面六個字節0100da870004 ,暫時只發現只要轉移過,都是這個值,具體含義尚不清楚。後面的8個字節的左右是:給出了這個數據原來的位置。
第七個到第十個字節7200 0000(轉換為十進制為144)為數據原來的數據頁。下面的兩個字節0100為文件號;最後的兩個字節為數據轉移前的所在數據頁面的slot號。
3、最後一頁的行偏移是怎麼偏移的。
1)、當數據少於8個頁面時使用混合類型的區
2)、SQLSERVER對頁面原使用原則在磁盤空間不足時才考慮回收 ,當一個歷史頁面被使用後刪除數據時是不會觸動數據的,所以混合區給調用後直接根據頁面上的freeData跳至指定區寫入數據
3)、因為我們都是在堆表上進行的