關於數據庫的邏輯設計,是一個很廣泛的問題。本文主要針對開發應用中遇到在MS SQL Server上進行表設計時,對表的主鍵設計應注意的問題以及相應的解決辦法。
主鍵設計現狀和問題
關於數據庫表的主鍵設計,一般而言,是根據業務需求情況,以業務邏輯為基礎,形成主鍵。
比如,銷售時要記錄銷售情況,一般需要兩個表,一個是銷售單的概要描述,記錄諸如銷售單號、總金額一類的情況,另外一個表記錄每種商品的數量和金額。對於第一個表(主表),通常我們以單據號為主鍵;對於商品銷售的明細表(從表),我們就需要將主表的單據號也放入到商品的明細表中,使其關聯起來形成主從關系。同時該單據號與商品的編碼一起,形成明細表的聯合主鍵。這只是一般情況,我們稍微將這個問題延伸一下:假如在明細中,我們每種商品又可能以不同的價格方式銷售。有部分按折扣價格銷售,有部分按正常價格銷售。要記錄這些情況,那麼我們就需要第三個表。而這第三個表的主鍵就需要第一個表的單據號以及第二個表的商品號再加上自身需要的信息一起構成聯合主鍵;又或者其他情況,在第一個主表中,本身就是以聯合方式構成聯合主鍵,那麼也需要在從表中將主表的多個字段添加進來聯合在一起形成自己的主鍵。
數據冗余存儲:隨著這種主從關系的延伸,數據庫中需要重復存儲的數據將變得越來越龐大。或者當主表本身就是聯合主鍵時,就必須在從表中將所有的字段重新存儲一次。
SQL復雜度增加:當存在多個字段的聯合主鍵時,我們需要將主表的多個字段與子表的多個字段關聯以獲取滿足某些條件的所有詳細情況記錄。
程序復雜度增加:可能需要傳遞多個參數。
效率降低:數據庫系統需要判斷更多的條件,SQL語句長度增加。同時,聯合主鍵自動生成聯合索引
WEB分頁困難:由於是聯合主鍵方式(對於多數的子表),那麼在WEB頁面上要進行分頁處理時,在自關聯時,難於處理。
解決方案
從上面,我們已經看到現有結構存在著相當多的弊端,主要是導致程序復雜、效率降低並且不利於分頁。
為解決上述問題,本文提出:當應用系統後台數據庫表間存在主從關系時,數據庫表額外增加一非業務字段作為主鍵,該字段為數值型;或者當該表需要在應用中進行分頁查詢時,也應考慮如此設計。一般地,我們也可以幾乎為任何表增加一個與業務邏輯無關的字段作為該表的主鍵字段。
由於該字段要作為表的主鍵,那麼其首要條件是要保證在該表中要具有唯一性。同時,結合SQL Server數據庫自身的特性,可以為其建立一個自增列:
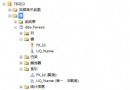
create TABLE T_PK_DEMO
(
U_ID BIGINT NOT NULL IDENTITY(1,1),
–唯一標識記錄的ID
COL_OTHER VARchar(20) NOT NULL ,
–其他列
CONSTRAINT PK_T_PK_DEMO PRIMARY KEY NONCLUSTERED
(U_ID)–定義為主鍵
)
但是,SQL Server中的自增列卻存在一個比較尴尬的事實,那就是該字段一旦定義和使用,用戶無法直接干預該字段的值,完全由數據庫系統自身控制:
完全數據庫系統控制,用戶無法修改值
在數據庫的發布和訂閱時,使用自增列會比較麻煩
恢復部分數據時,使用自增列會比較麻煩
該列的值必須在插入數據後才能獲取
鑒於此,建議不以自增列的方式來定義,而是參考Oracle數據庫系統中序列,在SQL Server系統中實現類似Oracle數據庫系統序列功能。這個具體在下面的小節中介紹。我們只需要按照普通字段的定義方式修改表定義為:
create TABLE T_PK_DEMO
(
U_ID BIGINT NOT NULL ,–唯一標識記錄的ID
COL_OTHER VARchar(20) NOT NULL ,–其他列
CONSTRAINT PK_T_PK_DEMO PRIMARY KEY NONCLUSTERED (U_ID)–定義為主鍵
)
參照Oracle序列的功能,我們需要在SQL Server數據庫中創建一個新表,以管理序列值:
create TABLE T_DB_SEQ
應用系統為需要創建自增列的表創建一個序列名稱,在表“T_DB_SEQ”中反映為數據庫中的一行。
第一,需要為需要建立序列的表創建一個序列。采用方法:F_create_SEQ(序列名)。該函數傳入序列的名稱,在表“T_DB_SEQ”插入一行。序列的所有者,采用系統變量SYSTEM_USER。
第二,獲取下一個值。采用方法:F_GET_NEXT_SEQ_VAL(序列名)。該函數根據序列名獲取該序列的下一個值,根據當前值與增長步長得到。同時,該函數保證在同時獲取同一個序列時,應保證並發一致性。
第三、將返回值返回到應用使用。
此外,為保證應用的完整性,可能還需要提供一些方法的重載方法,同時提供一些其他方法:
獲取序列當前值:F_GET_SEQ_CUR_VAL(序列名)
設置序列值:F_SET_SEQ_VAL(序列名)
刪除序列:F_DEL_SEQ(序列名)
判斷序列是否存在:F_SEQ_exists(序列名)
在主從關系的表設計中,子表也使用序列字段作為唯一主鍵,將父表的序列字段作為外鍵關聯:
create TABLE T_PK_DEMO_C
使用序列的問題及解決辦法
由於系統使用一個額外增加一個字段作為主鍵,因此沒有為業務邏輯建立主鍵約束。比如在企業用戶信息表中,要求企業中用戶登錄名必須唯一。一般在創建表時,以登錄名作為主鍵,這個時候在數據庫層自然的創建另一個主鍵唯一性約束。而現在沒有使用登錄名作為主鍵,那麼就沒有這個約束。解決辦法:
一是在數據庫層解決。可以為該表創建一個唯一(UNIQUE)約束或者唯一索引。如:
alter TABLE T_PK_DEMO ADD CONSTRAINT C_T_PK_DEMO UNIQUE NONCLUSTERED(COL_OTHER)-唯一約束
create UNIQUE INDEX IX_T_PK_DEMO ON T_PK_DEMO(COL_OTHER) – 唯一索引
二是在應用端解決。也就是在應用中判斷該列是否有重復值,然後根據判斷結果來保證唯一性。
我們注意到,在之前的例子中,主鍵采用了NONCLUSTERED(非聚蔟)的索引方式。關於如何設計索引,不是本文的重點,在這裡僅提供一個建立索引時采用聚蔟方式還是非聚蔟方式的一個一般原則:
作為非業務字段的主鍵列,是一個沒有重復值的、基本不進行更新操作的列。並且,在SQL Server數據庫中,聚蔟索引在一個表中只能有一個。因此,聚蔟索引非常重要,需要留給更重要的字段來使用。因此,對照上表和根據聚蔟索引的重要程度,在此處采用非聚蔟方式創建其索引。
具體應用
采用這種主鍵設計方式,有諸多好處,這已經在前文說明。現在就以一個具體的應用來說明如何使用這個主鍵。
當前的應用系統基本上都已經采用B/S方式,盡管現在的網絡速度已經有大幅度的提高,但是由於在WEB應用上用戶數量眾多、同時基本上所有的運算都集中在WEB應用服務器上,所以在WEB設計上更要考慮到性能的優化,以減少網絡流量和對服務器的壓力。最常見的一個應用就是列表方式展現時的分頁方式。一般的,在數據量小的情況下,一般不會怎麼注意這個問題,通常采用將數據完全取出,然後在WEB服務器上進行分頁。但是,當數據量龐大時,這種方式就會導致速度降低,甚至根本不可用。所以,一般采用存儲過程,在數據庫端進行分頁。