說明:以下數據庫操作基於SQL Server 2000
問題出現:
假設一個新聞系統,你需要獲取最近一周的熱點文章,一定會使用類似下面的SQL語句:
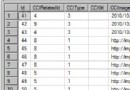
select top 50 newsID, newsTitle, newsRead from newstable where datediff("d", newsTime, getdate())<7 order by newsRead desc只要對newsID,newsRead,newsTime都有索引,用查詢分析器分析成本發現成本非常小,在newstable數據量小的情況下,訪問速度非常快。可是最近發現,當newstable到達200萬條記錄的時候,這條看似簡單的語句執行居然要1分鐘以上。
解決問題:
這個問題排查比較簡單,去掉order by一樣很慢,只能斷定是datediff造成的。我們嘗試把上面的語句分成2段:
第一條語句:select min(newsID) from newstable where datediff("d", newsTime, getdate())<7其中[minID]是第一條語句的結果,我們發現:第二條語句執行非常快,關鍵是第一條慢。newsID和newsTime均有索引,這是為什麼呢?
第二條語句:select top 50 newsID, newsTitle, newsRead from newstable where newsID>[minID] order by newsRead desc
換一個思路,第一條語句基本等價為
第三條語句:select max(newsID) from newstable where datediff("d", newsTime, getdate())>=7奇怪了,第三條語句執行起來飛快,雖然問題是曲線解決了,可這又是為什麼?難道和索引的排序次序有關?歡迎大家討論。