SQL Server所謂的分布式查詢(Distributed Query)是能夠訪問存放在同一部計算機或不同計算機上的SQL Server或不同種類的數據源, 從概念上來說分布式查詢與普通查詢區別 它需要連接多個MSSQL服務器也就是具有多了數據源。實現在服務器跨域或跨服務器訪問。 而這些查詢是否被使用完全看使用的需要。
本篇將演示利用SQL ServerExpress鏈接遠程SQL Server來獲取數據方式來詳細說明分布式查詢需要注意細節。先看一下系統架構數據查詢基本處理:
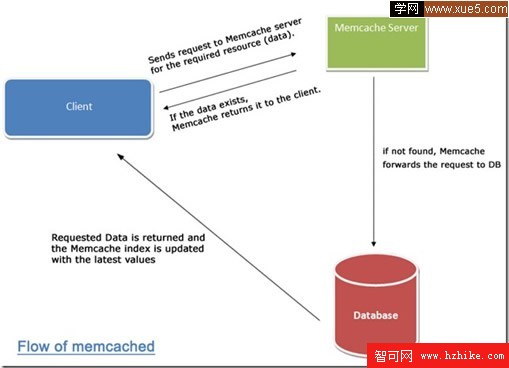
當然如果采用了分布式查詢 我們系統采取數據DataBase也就可能在多個遠程[Remote Server]上訪問時:
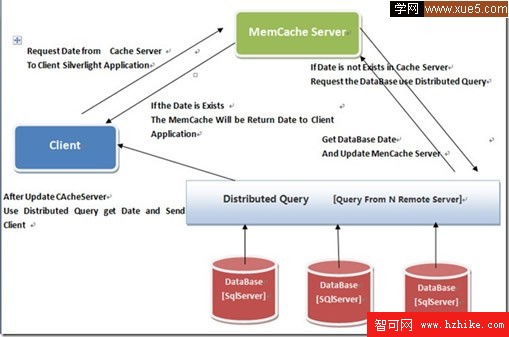
如上截取系統架構中關於數據與緩存流向中涉及的分布式查詢業務, 當我們從客戶端ClIEnt發起請求數據時。 首先檢查MemCache Server緩存服務器是否有我們想要數據。 如果沒有我需要查詢數據庫。 而此時數據要求查詢多個遠程服務器上多個數據庫中表, 這時利用分布式查詢。獲得數據 然後更新我們在緩存服務器MemCache Server上數據保持數據更新同步, 同時向客戶端ClIEnt直接返回數據。那如何來執行這一系列動作中最為關鍵分布式查詢?
《1》分布式查詢方式
我們知道Microsoft微軟公用的數據訪問的API是OLE_DB, 而對數據庫MSSQL Server 2005的分布式查詢支持也是OLE_DB方式.SQL Server 用戶可以使用分布式查詢訪問以下內容:
A:存儲在多個 SQL Server 實例中的分布式數據
B:存儲在各種可以使用 OLE DB 訪問接口訪問的關系和非關系數據源中的異類數據
OLE DB 訪問接口將在稱為行集的表格格式對象中公開數據。SQL Server 允許在 Transact-SQL 語句中像引用 SQL Server 表一樣引用
OLE DB 訪問接口中的行集,[其實不用關心這個行集概念 它的功能類似SQL Server中臨時表 不過它容積更大 能容納類型更多 更豐富]
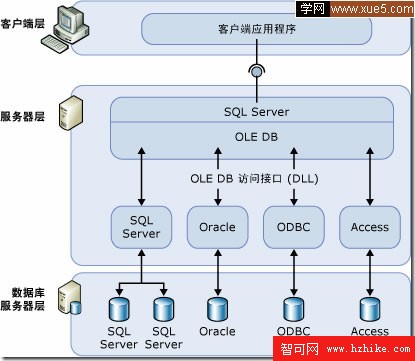
SQL Server 實例的客戶機與 OLE DB 訪問接口之間的連接 如下圖:
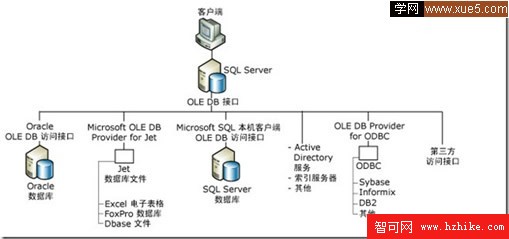
從上圖可以看出。客戶端借助OLEDB接口可以訪問Oracle/MS Jet/MS SQL/ODBC/第三方等這些豐富數據源來我們分布式查詢提供數據。 說了這麼多關於OLEDB底層支持。 關於在MS SQL 2005中則支持兩種方式來進行分布式查詢:
使用添加鏈接服務器方式(Add Link Server)
使用特定名稱及特定數據源來直接指定(Add Host Names)
其實這兩種方式在實際運用中是有區別的:
方式A:Add Link Server方式建立服務器之間關聯。創建一個鏈接的服務器,使其允許對分布式的、針對 OLE DB 數據源的異類查詢進行訪問。 一般適用於持久的數據操作 對於數據量偏大 服務器之間交付時間長特點。
方式B: Add Host Name 利用域來唯一識別數據庫以及數據庫表對象。 來實現跨服務器訪問。 這種方式一般比較簡單 主要適用於對數據需求臨時性查詢是使用偏多。 不適合做大批量數據提取。 有性能瓶頸。
《2》分布式查詢實現
在進行實現分布式查詢之前。本次測試Demo對應的SQL版本:
確定SQL Server版本後如下會演示兩種方式來實現分布式查詢,並對Distributed Query中詳細細節進行說明。
《2.1》鏈接服務器查詢
鏈接服務器配置使 SQL Server 可以對遠程服務器上的 OLE DB 數據源執行命令。鏈接服務器具有以下優點:
訪問遠程服務器。
能夠對企業內的異類數據源發出分布式查詢、更新、命令和事務。
能夠以相似的方式確定不同的數據源
下圖顯示了鏈接服務器配置的基礎:
現在利用鏈接服務器方式實現數據訪問遠程服務器數據庫CustomerDB中Users表數據先本地添加LinkServer:
以下是代碼片段:
-- 建立連接服務器 第一步建立連接 IP方式來控制如上市建立連接服務器最簡單方式。建立鏈接服務器過程其實調用了系統存儲過程Sp_addlinkedserver. 第一個參數為Name 其實用來唯一標識鏈接服務器。 當然可以其他任何有意義字符串來定義,但我個人建議使用遠程服務器的IP來標識。第二個參數是要添加為鏈接服務器的 OLE DB 數據源的產品名稱。 默認為Null,如果指定”SQL Server“則無需指定其他參數。
如果你的本地裝有多個數據庫實例。 第一個種方式就不適用。這是就需要用SQL Server2005架構來唯一標識:
-- 含架構名 查詢數據兩種模式對於SQL Server 2005架構這個概念很多人比較陌生:
在用戶角色設置中需要對指定訪問數據CustomerDB具有讀寫權限:
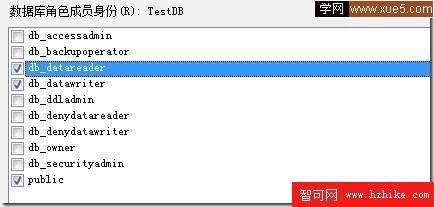
在遠程服務器創建TEst用戶時使用SQL Server身份驗證方式登錄 這時設置密碼為RemoteDB.在使用非Sa用戶進行遠程:
以下是代碼片段:
-- 執行前先刪除已經存在數據如上我們首先清除已經可能創建服務器數據記錄. 然後創建服務器連接.sp_addlinkedSrvlogin系統存儲過程用來創建鏈接服務器上遠程登錄之間的映射 . 即我們可以詳細設置本地與遠程服務器詳細的映射信息. 例如設置我們特定用戶訪問的用戶名和密碼.
查詢數據
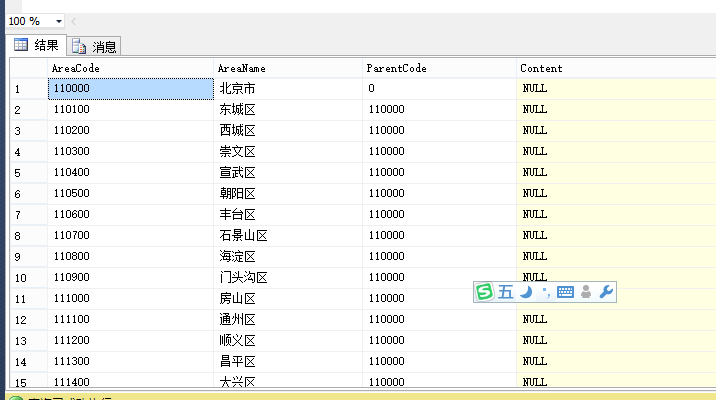
-- 查詢指定用戶Test數據 select * from [demodb].CustomerDB.dbo.Users -- [如上測試成功]
查詢結果
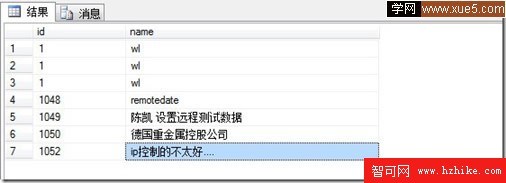
指定用戶Test對CustomerDB訪問數據方式測試成功。
當測試完成後我們不需要這個連接服務器是即可利用SP_DroplinkServer刪除掉。 對應參數為創建時Name唯一標識。 通過Sp_helpserver來查看連接服務器詳細信息。
注意如上創建連接服務器時設置srvproduct參數即OLED數據源名稱時我們采用了SQlServer方式。
下面說明這種方式特點。:
這種方式是最為簡單直接的一種建立鏈接服務器方式。 但是存在前提的。 測試發現:
在所有數據庫的遠程連接 dbo 的方式必須建立在SA 密碼相同的基礎上 ,否則容易產生無法連接的情況 Sa用戶登錄失敗。 你也就明白這個SQlServer參數其實就是在本地數據拷貝服務器角色SysAdmin下用戶SA.來對服務器進行登錄。 如果你的本地Sa密碼與遠程服務器上密碼不一致 則無法正常連接。
經過測試還發現一種情況:
利用Windows7訪問XP(Sp2)系統時始終提示無法解析或拒絕連接SQL Server2005.這個問題我整了好久後來才到官方鏈接參數中發現。:如果你的XP系統沒有打上SP4的補丁包 這個問題會始終出現。 需要特別注意。
《2.2》直接指定數據源分布式查詢
其實相對第一種方式, 直接指定方式在SQL Server架構中 其實跳過本地與遠程服務器建立映射關系的這一步。 通過鏈接關系建立 其實就是建立一種內部映射關系。 如果沒有映射關系則 大部分設置需要手動控制。
直接指定數據源方式 需要開啟分布式查詢的基本權限 來進行查詢:
以下是代碼片段:
-- 如果想使用分布式查詢,必須先開通分布式查詢 [外圍配置 這點是所有查詢操作前提]如上我們首先清除已經可能創建服務器數據記錄. 然後創建服務器連接.sp_addlinkedSrvlogin系統存儲過程用來創建鏈接服務器上遠程登錄之間的映射 . 即我們可以詳細設置本地與遠程服務器詳細的映射信息. 例如設置我們特定用戶訪問的用戶名和密碼.
查詢數據
-- 查詢指定用戶Test數據 select * from [demodb].CustomerDB.dbo.Users -- [如上測試成功]
查詢結果

指定用戶Test對CustomerDB訪問數據方式測試成功。
《3》問題排查與更多查詢方式
當我們在實際編程中進行訪問遠程數據時 因為不同操作環境會引發各種各樣的異常,如下我會提出一種常見的異常方式解決辦法和關於遠程數據操作更多查詢方式。
《3.1》無法建立遠程連接
其實這個問題在做分布式查詢時極其常見。 而引起這個問題的因素過多。 我們一時無法判斷真正引發這個異常地方。 只能通過逐個排查方式來進行設置:
例如我們在建立關聯關系後 進行查詢時會遇到:

提示是: 在進行遠程連接時超時, 引起這個問題原因可能是遠程服務器積極拒絕訪問!
首先要在SQL Server Configuation Manager中保證你服務已經運行 且是開機自動運行。
再次檢查SQL Server 2005外圍配置DataBaseEngine允許遠程連接:
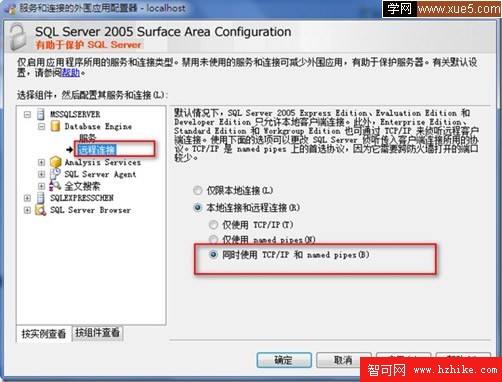
設置完成後。我們還需要設置SQL Server Analysis Services分析服務也支持遠程數據查詢:
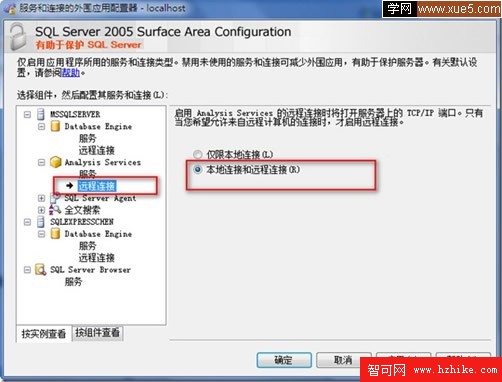
在遠程服務器上如果啟用了防火牆則可能對目前SQL Server Server方位實例進行攔截。 所以在服務器端啟用防火牆情況下要為SQL Server DAtaBase創建例外。防止客戶端請求被攔截。
《3.2》進程被其他用戶占用
當我們在遠程分布式查詢中有創建動作或是類似創建一個新的數據庫。 有時會提示 “該數據庫無法操作 已經別其他進程占用”異常。 導致我們無法訪問數據庫。 或是執行我們要做的創建操作.
遇到這種情況我們可以利用SA權限查詢到Master數據庫對應數據庫被占用的進程 並殺掉Kill Process.查詢:
以下是代碼片段:
-- [sysprocesses 表中保存關於運行在 Microsoft® SQL Server™ 上的進程的信息。當我們對進程占用清除時有可能訪問數據庫被系統進程占用。 則這時用Sa無法殺死。這時提示:
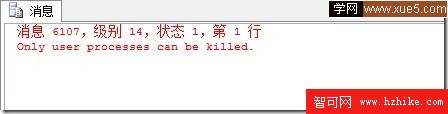
“Only use Process can be Kill ”在SQL Server2005 只有只有用戶進程才能Kill掉。
《3.3》更多的查詢操作
往往我們在實際操作中需要對數據讀寫有更多要求。 例如從遠程連接多個服務器進行數據讀取或是把本地數據提交到服務器上。 為了提高效率和性能采用分布式事務來進行批量操作等等。 如下簡單介紹在分布式查詢中多中數據操作:
把遠程數據導入本地:
以下是代碼片段:
-- 把本地表導入遠程表 [openWset方式]導入時使用Into方式 自動在本地創建CopyDB表完全復制遠程服務器上Users表的數據結構。但是要注意在進行後 的CopyDB將不包含原表的主鍵和索引約束。 雖然能快構建 但是主鍵和索引設置都會丟失。
本地數據導入遠程:
-- 把本地表導入遠程表 [openWset方式] insert openrowset( 'SQLOLEDB ', 'sql服務器名 '; '用戶名 '; '密碼 ',數據庫名.dbo.表名) select *from 本地表 -- 把本地表導入遠程表 [open Query方式] insert openquery(ITSV, 'SELECT * FROM 數據庫.dbo.表名 ')更新本地表數據:
以下是代碼片段:
-- 把本地表導入遠程表 [opendataSource方式]當然還有更多方式來操作分布式查詢操作。各位都可以嘗試。
《4》尾 語
如上是我最近在項目中處理關於分布式查詢涉及到方方面面。 從系統架構到分部是查詢具體操作細節。基本都是一些非常基礎運用。當然也參考不少資料。以及動手來驗證整個過程出現問題原因所在。 篇幅有限 寫的有些倉促。 難免有纰漏地方 還望各位指正。