在以下的文章中,我將以“辦公自動化”系統為例,探討如何在有著1000萬條數據的MS SQL Server數據庫中實現快速的數據提取和數據分頁。以下代碼說明了我們實例中數據庫的“紅頭文件”一表的部分數據結構:
CREATE TABLE [dbo].[TGongwen] ( --TGongwen是紅頭文件表名
[Gid] [int] IDENTITY (1, 1) NOT NULL ,
--本表的id號,也是主鍵
[title] [varchar] (80) COLLATE Chinese_PRC_CI_AS NULL ,
--紅頭文件的標題
[fariqi] [datetime] NULL ,
--發布日期
[neibuYonghu] [varchar] (70) COLLATE Chinese_PRC_CI_AS NULL ,
--發布用戶
[reader] [varchar] (900) COLLATE Chinese_PRC_CI_AS NULL ,
--需要浏覽的用戶。每個用戶中間用分隔符“,”分開
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
下面,我們來往數據庫中添加1000萬條數據:
declare @i int
set @i=1
while @i<=250000
begin
insert into Tgongwen(fariqi,neibuyonghu,reader,title) values('2004-2-5','通信科','通信科,辦公室,王局長,劉局長,張局長,admin,刑偵支隊,特勤支隊,交巡警支隊,經偵支隊,戶政科,治安支隊,外事科','這是最先的25萬條記錄')
set @i=@i+1
end
GO
declare @i int
set @i=1
while @i<=250000
begin
insert into Tgongwen(fariqi,neibuyonghu,reader,title) values('2004-9-16','辦公室','辦公室,通信科,王局長,劉局長,張局長,admin,刑偵支隊,特勤支隊,交巡警支隊,經偵支隊,戶政科,外事科','這是中間的25萬條記錄')
set @i=@i+1
end
GO
declare @h int
set @h=1
while @h<=100
begin
declare @i int
set @i=2002
while @i<=2003
begin
declare @j int
set @j=0
while @j<50
begin
declare @k int
set @k=0
while @k<50
begin
insert into Tgongwen(fariqi,neibuyonghu,reader,title) values(cast(@i as varchar(4))+'-8-15 3:'+cast(@j as varchar(2))+':'+cast(@j as varchar(2)),'通信科','辦公室,通信科,王局長,劉局長,張局長,admin,刑偵支隊,特勤支隊,交巡警支隊,經偵支隊,戶政科,外事科','這是最後的50萬條記錄')
set @k=@k+1
end
set @j=@j+1
end
set @i=@i+1
end
set @h=@h+1
end
GO
declare @i int
set @i=1
while @i<=9000000
begin
insert into Tgongwen(fariqi,neibuyonghu,reader,title) values('2004-5-5','通信科','通信科,辦公室,王局長,劉局長,張局長,admin,刑偵支隊,特勤支隊,交巡警支隊,經偵支隊,戶政科,治安支隊,外事科','這是最後添加的900萬條記錄')
set @i=@i+1000000
end
GO
通過以上語句,我們創建了25萬條由通信科於2004年2月5日發布的記錄,25萬條由辦公室於2004年9月6日發布的記錄,2002年和2003年各100個2500條相同日期、不同分秒的由通信科發布的記錄(共50萬條),還有由通信科於2004年5月5日發布的900萬條記錄,合計1000萬條。
一、因情制宜,建立“適當”的索引
建立“適當”的索引是實現查詢優化的首要前提。
索引(index)是除表之外另一重要的、用戶定義的存儲在物理介質上的數據結構。當根據索引碼的值搜索數據時,索引提供了對數據的快速訪問。事實上,沒有索引,數據庫也能根據SELECT語句成功地檢索到結果,但隨著表變得越來越大,使用“適當”的索引的效果就越來越明顯。注意,在這句話中,我們用了“適當”這個詞,這是因為,如果使用索引時不認真考慮其實現過程,索引既可以提高也會破壞數據庫的工作性能。
(一)深入淺出理解索引結構
實際上,您可以把索引理解為一種特殊的目錄。微軟的SQL Server提供了兩種索引:聚集索引(clustered index,也稱聚類索引、簇集索引)和非聚集索引(nonclustered index,也稱非聚類索引、非簇集索引)。下面,我們舉例來說明一下聚集索引和非聚集索引的區別:
其實,我們的漢語字典的正文本身就是一個聚集索引。比如,我們要查“安”字,就會很自然地翻開字典的前幾頁,因為“安”的拼音是“an”,而按照拼音排序漢字的字典是以英文字母“a”開頭並以“z”結尾的,那麼“安”字就自然地排在字典的前部。如果您翻完了所有以“a”開頭的部分仍然找不到這個字,那麼就說明您的字典中沒有這個字;同樣的,如果查“張”字,那您也會將您的字典翻到最後部分,因為“張”的拼音是“zhang”。也就是說,字典的正文部分本身就是一個目錄,您不需要再去查其他目錄來找到您需要找的內容。
我們把這種正文內容本身就是一種按照一定規則排列的目錄稱為“聚集索引”。
如果您認識某個字,您可以快速地從自動中查到這個字。但您也可能會遇到您不認識的字,不知道它的發音,這時候,您就不能按照剛才的方法找到您要查的字,而需要去根據“偏旁部首”查到您要找的字,然後根據這個字後的頁碼直接翻到某頁來找到您要找的字。但您結合“部首目錄”和“檢字表”而查到的字的排序並不是真正的正文的排序方法,比如您查“張”字,我們可以看到在查部首之後的檢字表中“張”的頁碼是672頁,檢字表中“張”的上面是“馳”字,但頁碼卻是63頁,“張”的下面是“弩”字,頁面是390頁。
很顯然,這些字並不是真正的分別位於“張”字的上下方,現在您看到的連續的“馳、張、弩”三字實際上就是他們在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我們可以通過這種方式來找到您所需要的字,但它需要兩個過程,先找到目錄中的結果,然後再翻到您所需要的頁碼。我們把這種目錄純粹是目錄,正文純粹是正文的排序方式稱為“非聚集索引”。
通過以上例子,我們可以理解到什麼是“聚集索引”和“非聚集索引”。
進一步引申一下,我們可以很容易的理解:每個表只能有一個聚集索引,因為目錄只能按照一種方法進行排序。
(二)何時使用聚集索引或非聚集索引
下面的表總結了何時使用聚集索引或非聚集索引(很重要)。
動作描述
使用聚集索引
使用非聚集索引
列經常被分組排序
應
應
返回某范圍內的數據
應
不應
一個或極少不同值
不應
不應
小數目的不同值
應
不應
大數目的不同值
不應
應
頻繁更新的列
不應
應
外鍵列
應
應
主鍵列
應
應
頻繁修改索引列
不應
應
事實上,我們可以通過前面聚集索引和非聚集索引的定義的例子來理解上表。如:返回某范圍內的數據一項。比如您的某個表有一個時間列,恰好您把聚合索引建立在了該列,這時您查詢2004年1月1日至2004年10月1日之間的全部數據時,這個速度就將是很快的,因為您的這本字典正文是按日期進行排序的,聚類索引只需要找到要檢索的所有數據中的開頭和結尾數據即可;而不像非聚集索引,必須先查到目錄中查到每一項數據對應的頁碼,然後再根據頁碼查到具體內容。
(三)結合實際,談索引使用的誤區
理論的目的是應用。雖然我們剛才列出了何時應使用聚集索引或非聚集索引,但在實踐中以上規則卻很容易被忽視或不能根據實際情況進行綜合分析。下面我們將根據在實踐中遇到的實際問題來談一下索引使用的誤區,以便於大家掌握索引建立的方法。
1、主鍵就是聚集索引
這種想法筆者認為是極端錯誤的,是對聚集索引的一種浪費。雖然SQL Server默認是在主鍵上建立聚集索引的。
通常,我們會在每個表中都建立一個ID列,以區分每條數據,並且這個ID列是自動增大的,步長一般為1。我們的這個辦公自動化的實例中的列Gid就是如此。此時,如果我們將這個列設為主鍵,SQL Server會將此列默認為聚集索引。這樣做有好處,就是可以讓您的數據在數據庫中按照ID進行物理排序,但筆者認為這樣做意義不大。
顯而易見,聚集索引的優勢是很明顯的,而每個表中只能有一個聚集索引的規則,這使得聚集索引變得更加珍貴。
從我們前面談到的聚集索引的定義我們可以看出,使用聚集索引的最大好處就是能夠根據查詢要求,迅速縮小查詢范圍,避免全表掃描。在實際應用中,因為ID號是自動生成的,我們並不知道每條記錄的ID號,所以我們很難在實踐中用ID號來進行查詢。這就使讓ID號這個主鍵作為聚集索引成為一種資源浪費。其次,讓每個ID號都不同的字段作為聚集索引也不符合“大數目的不同值情況下不應建立聚合索引”規則;當然,這種情況只是針對用戶經常修改記錄內容,特別是索引項的時候會負作用,但對於查詢速度並沒有影響。
在辦公自動化系統中,無論是系統首頁顯示的需要用戶簽收的文件、會議還是用戶進行文件查詢等任何情況下進行數據查詢都離不開字段的是“日期”還有用戶本身的“用戶名”。
通常,辦公自動化的首頁會顯示每個用戶尚未簽收的文件或會議。雖然我們的where語句可以僅僅限制當前用戶尚未簽收的情況,但如果您的系統已建立了很長時間,並且數據量很大,那麼,每次每個用戶打開首頁的時候都進行一次全表掃描,這樣做意義是不大的,絕大多數的用戶1個月前的文件都已經浏覽過了,這樣做只能徒增數據庫的開銷而已。事實上,我們完全可以讓用戶打開系統首頁時,數據庫僅僅查詢這個用戶近3個月來未閱覽的文件,通過“日期”這個字段來限制表掃描,提高查詢速度。如果您的辦公自動化系統已經建立的2年,那麼您的首頁顯示速度理論上將是原來速度8倍,甚至更快。
在這裡之所以提到“理論上”三字,是因為如果您的聚集索引還是盲目地建在ID這個主鍵上時,您的查詢速度是沒有這麼高的,
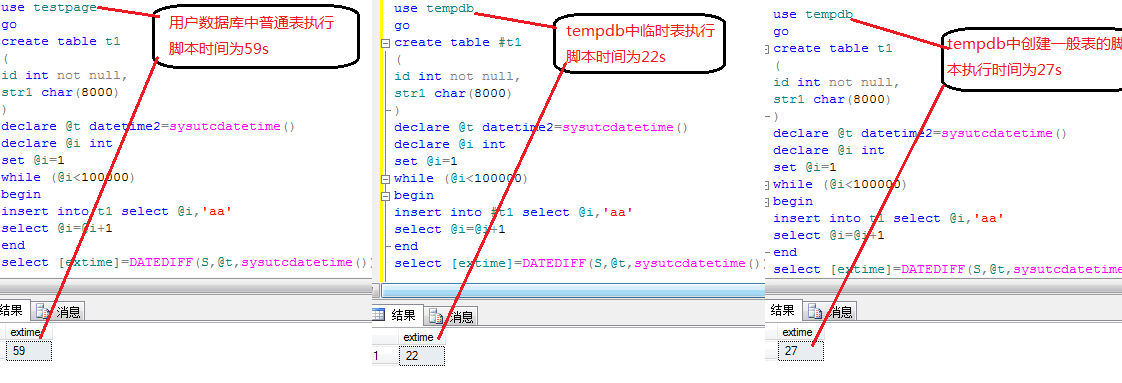
即使您在“日期”這個字段上建立的索引(非聚合索引)。下面我們就來看一下在1000萬條數據量的情況下各種查詢的速度表現(3個月內的數據為25萬條):(1)僅在主鍵上建立聚集索引,並且不劃分時間段:
Select gid,fariqi,neibuyonghu,title from tgongwen
用時:128470毫秒(即:128秒)
(2)在主鍵上建立聚集索引,在fariq上建立非聚集索引:
select gid,fariqi,neibuyonghu,title from Tgongwen
where fariqi> dateadd(day,-90,getdate())
用時:53763毫秒(54秒)
(3)將聚合索引建立在日期列(fariqi)上:
select gid,fariqi,neibuyonghu,title from Tgongwen
where fariqi> dateadd(day,-90,getdate())
用時:2423毫秒(2秒)
雖然每條語句提取出來的都是25萬條數據,各種情況的差異卻是巨大的,特別是將聚集索引建立在日期列時的差異。事實上,如果您的數據庫真的有1000萬容量的話,把主鍵建立在ID列上,就像以上的第1、2種情況,在網頁上的表現就是超時,根本就無法顯示。這也是我摒棄ID列作為聚集索引的一個最重要的因素。
得出以上速度的方法是:在各個select語句前加:declare @d datetime
set @d=getdate()
並在select語句後加:
select [語句執行花費時間(毫秒)]=datediff(ms,@d,getdate())
2、只要建立索引就能顯著提高查詢速度
事實上,我們可以發現上面的例子中,第2、3條語句完全相同,且建立索引的字段也相同;不同的僅是前者在fariqi字段上建立的是非聚合索引,後者在此字段上建立的是聚合索引,但查詢速度卻有著天壤之別。所以,並非是在任何字段上簡單地建立索引就能提高查詢速度。
從建表的語句中,我們可以看到這個有著1000萬數據的表中fariqi字段有5003個不同記錄。在此字段上建立聚合索引是再合適不過了。在現實中,我們每天都會發幾個文件,這幾個文件的發文日期就相同,這完全符合建立聚集索引要求的:“既不能絕大多數都相同,又不能只有極少數相同”的規則。由此看來,我們建立“適當”的聚合索引對於我們提高查詢速度是非常重要的。
3、把所有需要提高查詢速度的字段都加進聚集索引,以提高查詢速度
上面已經談到:在進行數據查詢時都離不開字段的是“日期”還有用戶本身的“用戶名”。既然這兩個字段都是如此的重要,我們可以把他們合並起來,建立一個復合索引(compound index)。
很多人認為只要把任何字段加進聚集索引,就能提高查詢速度,也有人感到迷惑:如果把復合的聚集索引字段分開查詢,那麼查詢速度會減慢嗎?帶著這個問題,我們來看一下以下的查詢速度(結果集都是25萬條數據):(日期列fariqi首先排在復合聚集索引的起始列,用戶名neibuyonghu排在後列)
(1)select gid,fariqi,neibuyonghu,title from Tgongwen where fariqi>'2004-5-5'
查詢速度:2513毫秒
(2)select gid,fariqi,neibuyonghu,title from Tgongwen where fariqi>'2004-5-5' and neibuyonghu='辦公室'
查詢速度:2516毫秒
(3)select gid,fariqi,neibuyonghu,title from Tgongwen where neibuyonghu='辦公室'
查詢速度:60280毫秒
從以上試驗中,我們可以看到如果僅用聚集索引的起始列作為查詢條件和同時用到復合聚集索引的全部列的查詢速度是幾乎一樣的,甚至比用上全部的復合索引列還要略快(在查詢結果集數目一樣的情況下);而如果僅用復合聚集索引的非起始列作為查詢條件的話,這個索引是不起任何作用的。當然,語句1、2的查詢速度一樣是因為查詢的條目數一樣,如果復合索引的所有列都用上,而且查詢結果少的話,這樣就會形成“索引覆蓋”,因而性能可以達到最優。同時,請記住:無論您是否經常使用聚合索引的其他列,但其前導列一定要是使用最頻繁的列。
(四)其他書上沒有的索引使用經驗總結
1、用聚合索引比用不是聚合索引的主鍵速度快
下面是實例語句:(都是提取25萬條數據)
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi='2004-9-16'
使用時間:3326毫秒
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where gid<=250000
使用時間:4470毫秒
這裡,用聚合索引比用不是聚合索引的主鍵速度快了近1/4。
2、用聚合索引比用一般的主鍵作order by時速度快,特別是在小數據量情況下
select gid,fariqi,neibuyonghu,reader,title from Tgongwen order by fariqi
用時:12936
select gid,fariqi,neibuyonghu,reader,title from Tgongwen order by gid
用時:18843
這裡,用聚合索引比用一般的主鍵作order by時,速度快了3/10。事實上,如果數據量很小的話,用聚集索引作為排序列要比使用非聚集索引速度快得明顯的多;而數據量如果很大的話,如10萬以上,則二者的速度差別不明顯。
3、使用聚合索引內的時間段,搜索時間會按數據占整個數據表的百分比成比例減少,而無論聚合索引使用了多少個
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi>'2004-1-1'
用時:6343毫秒(提取100萬條)
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi>'2004-6-6'
用時:3170毫秒(提取50萬條)
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi='2004-9-16'
用時:3326毫秒(和上句的結果一模一樣。如果采集的數量一樣,那麼用大於號和等於號是一樣的)
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi>'2004-1-1' and fariqi<'2004-6-6'
用時:3280毫秒
4 、日期列不會因為有分秒的輸入而減慢查詢速度
下面的例子中,共有100萬條數據,2004年1月1日以後的數據有50萬條,但只有兩個不同的日期,日期精確到日;之前有數據50萬條,有5000個不同的日期,日期精確到秒。
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi>'2004-1-1' order by fariqi
用時:6390毫秒
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi<'2004-1-1' order by fariqi
用時:6453毫秒
(五)其他注意事項
“水可載舟,亦可覆舟”,索引也一樣。索引有助於提高檢索性能,但過多或不當的索引也會導致系統低效。因為用戶在表中每加進一個索引,數據庫就要做更多的工作。過多的索引甚至會導致索引碎片。
所以說,我們要建立一個“適當”的索引體系,特別是對聚合索引的創建,更應精益求精,以使您的數據庫能得到高性能的發揮。
當然,在實踐中,作為一個盡職的數據庫管理員,您還要多測試一些方案,找出哪種方案效率最高、最為有效。
二、改善SQL語句
很多人不知道SQL語句在SQL SERVER中是如何執行的,他們擔心自己所寫的SQL語句會被SQL Server誤解。比如:
select * from table1 where name='zhangsan' and tID > 10000
和執行:
select * from table1 where tID > 10000 and name='zhangsan'
一些人不知道以上兩條語句的執行效率是否一樣,因為如果簡單的從語句先後上看,這兩個語句的確是不一樣,如果tID是一個聚合索引,那麼後一句僅僅從表的10000條以後的記錄中查找就行了;而前一句則要先從全表中查找看有幾個name='zhangsan'的,而後再根據限制條件條件tID>10000來提出查詢結果。
事實上,這樣的擔心是不必要的。SQL Server中有一個“查詢分析優化器”,它可以計算出where子句中的搜索條件並確定哪個索引能縮小表掃描的搜索空間,也就是說,它能實現自動優化。
雖然查詢優化器可以根據where子句自動的進行查詢優化,但大家仍然有必要了解一下“查詢優化器”的工作原理,如非這樣,有時查詢優化器就會不按照您的本意進行快速查詢。
在查詢分析階段,查詢優化器查看查詢的每個階段並決定限制需要掃描的數據量是否有用。如果一個階段可以被用作一個掃描參數(SARG),那麼就稱之為可優化的,並且可以利用索引快速獲得所需數據。
SARG的定義:用於限制搜索的一個操作,因為它通常是指一個特定的匹配,一個值得范圍內的匹配或者兩個以上條件的AND連接。形式如下:
列名 操作符 <常數 或 變量>
或
<常數 或 變量> 操作符列名
列名可以出現在操作符的一邊,而常數或變量出現在操作符的另一邊。如:
Name=’張三’
價格>5000
5000<價格
Name=’張三’ and 價格>5000
如果一個表達式不能滿足SARG的形式,那它就無法限制搜索的范圍了,也就是SQL Server必須對每一行都判斷它是否滿足WHERE子句中的所有條件。所以一個索引對於不滿足SARG形式的表達式來說是無用的。
介紹完SARG後,我們來總結一下使用SARG以及在實踐中遇到的和某些資料上結論不同的經驗:
1、Like語句是否屬於SARG取決於所使用的通配符的類型
如:name like ‘張%’ ,這就屬於SARG
而:name like ‘%張’ ,就不屬於SARG。
原因是通配符%在字符串的開通使得索引無法使用。
2、or 會引起全表掃描
Name=’張三’ and 價格>5000 符號SARG,而:Name=’張三’ or 價格>5000 則不符合SARG。使用or會引起全表掃描。
3、非操作符、函數引起的不滿足SARG形式的語句
不滿足SARG形式的語句最典型的情況就是包括非操作符的語句,如:NOT、!=、<>、!<、!>、NOT EXISTS、NOT IN、NOT LIKE等,另外還有函數。下面就是幾個不滿足SARG形式的例子:
ABS(價格)<5000
Name like ‘%三’
有些表達式,如:
WHERE 價格*2>5000
SQL SERVER也會認為是SARG,SQL Server會將此式轉化為:
WHERE 價格>2500/2
但我們不推薦這樣使用,因為有時SQL Server不能保證這種轉化與原始表達式是完全等價的。
4、IN 的作用相當與OR
語句:
Select * from table1 where tid in (2,3)
和
Select * from table1 where tid=2 or tid=3
是一樣的,都會引起全表掃描,如果tid上有索引,其索引也會失效。
5、盡量少用NOT
6、exists 和 in 的執行效率是一樣的
很多資料上都顯示說,exists要比in的執行效率要高,同時應盡可能的用not exists來代替not in。但事實上,我試驗了一下,發現二者無論是前面帶不帶not,二者之間的執行效率都是一樣的。因為涉及子查詢,我們試驗這次用SQL Server自帶的pubs數據庫。運行前我們可以把SQL Server的statistics I/O狀態打開。
(1)select title,price from titles where title_id in (select title_id from sales where qty>30)
該句的執行結果為:
表 'sales'。掃描計數 18,邏輯讀 56 次,物理讀 0 次,預讀 0 次。
表 'titles'。掃描計數 1,邏輯讀 2 次,物理讀 0 次,預讀 0 次。
(2)select title,price from titles where exists (select * from sales where sales.title_id=titles.title_id and qty>30)
第二句的執行結果為:
表 'sales'。掃描計數 18,邏輯讀 56 次,物理讀 0 次,預讀 0 次。
表 'titles'。掃描計數 1,邏輯讀 2 次,物理讀 0 次,預讀 0 次。
我們從此可以看到用exists和用in的執行效率是一樣的。
7、用函數charindex()和前面加通配符%的LIKE執行效率一樣
前面,我們談到,如果在LIKE前面加上通配符%,那麼將會引起全表掃描,所以其執行效率是低下的。但有的資料介紹說,用函數charindex()來代替LIKE速度會有大的提升,經我試驗,發現這種說明也是錯誤的:
select gid,title,fariqi,reader from tgongwen where charindex('刑偵支隊',reader)>0 and fariqi>'2004-5-5'
用時:7秒,另外:掃描計數 4,邏輯讀 7155 次,物理讀 0 次,預讀 0 次。
select gid,title,fariqi,reader from tgongwen where reader like '%' + '刑偵支隊' + '%' and fariqi>'2004-5-5'
用時:7秒,另外:掃描計數 4,邏輯讀 7155 次,物理讀 0 次,預讀 0 次。
8、union並不絕對比or的執行效率高
我們前面已經談到了在where子句中使用or會引起全表掃描,一般的,我所見過的資料都是推薦這裡用union來代替or。事實證明,這種說法對於大部分都是適用的。
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi='2004-9-16' or gid>9990000
用時:68秒。掃描計數 1,邏輯讀 404008 次,物理讀 283 次,預讀 392163 次。
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi='2004-9-16'
union
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where gid>9990000
用時:9秒。掃描計數 8,邏輯讀 67489 次,物理讀 216 次,預讀 7499 次。
看來,用union在通常情況下比用or的效率要高的多。
但經過試驗,筆者發現如果or兩邊的查詢列是一樣的話,那麼用union則反倒和用or的執行速度差很多,雖然這裡union掃描的是索引,而or掃描的是全表。
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi='2004-9-16' or fariqi='2004-2-5'
用時:6423毫秒。掃描計數 2,邏輯讀 14726 次,物理讀 1 次,預讀 7176 次。
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi='2004-9-16'
union
select gid,fariqi,neibuyonghu,reader,title from Tgongwen where fariqi='2004-2-5'
用時:11640毫秒。掃描計數 8,邏輯讀 14806 次,物理讀 108 次,預讀 1144 次。
9、字段提取要按照“需多少、提多少”的原則,避免“select *”
我們來做一個試驗:
select top 10000 gid,fariqi,reader,title from tgongwen order by gid desc
用時:4673毫秒
select top 10000 gid,fariqi,title from tgongwen order by gid desc
用時:1376毫秒
select top 10000 gid,fariqi from tgongwen order by gid desc
用時:80毫秒
由此看來,我們每少提取一個字段,數據的提取速度就會有相應的提升。提升的速度還要看您捨棄的字段的大小來判斷。
10、count(*)不比count(字段)慢
某些資料上說:用*會統計所有列,顯然要比一個世界的列名效率低。這種說法其實是沒有根據的。我們來看:
select count(*) from Tgongwen
用時:1500毫秒
select count(gid) from Tgongwen
用時:1483毫秒
select count(fariqi) from Tgongwen
用時:3140毫秒
select count(title) from Tgongwen
用時:52050毫秒
從以上可以看出,如果用count(*)和用count(主鍵)的速度是相當的,而count(*)卻比其他任何除主鍵以外的字段匯總速度要快,而且字段越長,匯總的速度就越慢。我想,如果用count(*), SQL Server可能會自動查找最小字段來匯總的。當然,如果您直接寫count(主鍵)將會來的更直接些。
11、order by按聚集索引列排序效率最高
我們來看:(gid是主鍵,fariqi是聚合索引列)
select top 10000 gid,fariqi,reader,title from tgongwen
用時:196 毫秒。 掃描計數 1,邏輯讀 289 次,物理讀 1 次,預讀 1527 次。
select top 10000 gid,fariqi,reader,title from tgongwen order by gid asc
用時:4720毫秒。 掃描計數 1,邏輯讀 41956 次,物理讀 0 次,預讀 1287 次。
select top 10000 gid,fariqi,reader,title from tgongwen order by gid desc
用時:4736毫秒。 掃描計數 1,邏輯讀 55350 次,物理讀 10 次,預讀 775 次。
select top 10000 gid,fariqi,reader,title from tgongwen order by fariqi asc
用時:173毫秒。 掃描計數 1,邏輯讀 290 次,物理讀 0 次,預讀 0 次。
select top 10000 gid,fariqi,reader,title from tgongwen order by fariqi desc
用時:156毫秒。 掃描計數 1,邏輯讀289 次,物理讀 0 次,預讀 0 次。
從以上我們可以看出,不排序的速度以及邏輯讀次數都是和“order by 聚集索引列” 的速度是相當的,但這些都比“order by 非聚集索引列”的查詢速度是快得多的。
同時,按照某個字段進行排序的時候,無論是正序還是倒序,速度是基本相當的。
12、高效的TOP
事實上,在查詢和提取超大容量的數據集時,影響數據庫響應時間的最大因素不是數據查找,而是物理的I/0操作。如:
select top 10 * from (
select top 10000 gid,fariqi,title from tgongwen
where neibuyonghu='辦公室'
order by gid desc) as a
order by gid asc
這條語句,從理論上講,整條語句的執行時間應該比子句的執行時間長,但事實相反。因為,子句執行後返回的是10000條記錄,而整條語句僅返回10條語句,所以影響數據庫響應時間最大的因素是物理I/O操作。而限制物理I/O操作此處的最有效方法之一就是使用TOP關鍵詞了。TOP關鍵詞是SQL Server中經過系統優化過的一個用來提取前幾條或前幾個百分比數據的詞。經筆者在實踐中的應用,發現TOP確實很好用,效率也很高。但這個詞在另外一個大型數據庫ORACLE中卻沒有,這不能說不是一個遺憾,雖然在Oracle中可以用其他方法(如:rownumber)來解決。在以後的關於“實現千萬級數據的分頁顯示存儲過程”的討論中,我們就將用到TOP這個關鍵詞。
到此為止,我們上面討論了如何實現從大容量的數據庫中快速地查詢出您所需要的數據方法。當然,我們介紹的這些方法都是“軟”方法,在實踐中,我們還要考慮各種“硬”因素,如:網絡性能、服務器的性能、操作系統的性能,甚至網卡、交換機等。
三、實現小數據量和海量數據的通用分頁顯示存儲過程
建立一個web 應用,分頁浏覽功能必不可少。這個問題是數據庫處理中十分常見的問題。經典的數據分頁方法是:ADO 紀錄集分頁法,也就是利用ADO自帶的分頁功能(利用游標)來實現分頁。但這種分頁方法僅適用於較小數據量的情形,因為游標本身有缺點:游標是存放在內存中,很費內存。游標一建立,就將相關的記錄鎖住,直到取消游標。游標提供了對特定集合中逐行掃描的手段,一般使用游標來逐行遍歷數據,根據取出數據條件的不同進行不同的操作。而對於多表和大表中定義的游標(大的數據集合)循環很容易使程序進入一個漫長的等待甚至死機。
更重要的是,對於非常大的數據模型而言,分頁檢索時,如果按照傳統的每次都加載整個數據源的方法是非常浪費資源的。現在流行的分頁方法一般是檢索頁面大小的塊區的數據,而非檢索所有的數據,然後單步執行當前行。
最早較好地實現這種根據頁面大小和頁碼來提取數據的方法大概就是“俄羅斯存儲過程”。這個存儲過程用了游標,由於游標的局限性,所以這個方法並沒有得到大家的普遍認可。
後來,網上有人改造了此存儲過程,下面的存儲過程就是結合我們的辦公自動化實例寫的分頁存儲過程:
CREATE procedure pagination1
(@pagesize int, --頁面大小,如每頁存儲20條記錄
@pageindex int --當前頁碼
)
as
set nocount on
begin
declare @indextable table(id int identity(1,1),nid int) --定義表變量
declare @PageLowerBound int --定義此頁的底碼
declare @PageUpperBound int --定義此頁的頂碼
set @PageLowerBound=(@pageindex-1)*@pagesize
set @PageUpperBound=@PageLowerBound+@pagesize
set rowcount @PageUpperBound
insert into @indextable(nid) select gid from TGongwen where fariqi >dateadd(day,-365,getdate()) order by fariqi desc
select O.gid,O.mid,O.title,O.fadanwei,O.fariqi from TGongwen O,@indextable t where O.gid=t.nid
and t.id>@PageLowerBound and t.id<=@PageUpperBound order by t.id
end
set nocount off
以上存儲過程運用了SQL SERVER的最新技術――表變量。應該說這個存儲過程也是一個非常優秀的分頁存儲過程。當然,在這個過程中,您也可以把其中的表變量寫成臨時表:CREATE TABLE #Temp。但很明顯,在SQL Server中,用臨時表是沒有用表變量快的。所以筆者剛開始使用這個存儲過程時,感覺非常的不錯,速度也比原來的ADO的好。但後來,我又發現了比此方法更好的方法。
筆者曾在網上看到了一篇小短文《從數據表中取出第n條到第m條的記錄的方法》,全文如下:
從publish 表中取出第 n 條到第 m 條的記錄:
SELECT TOP m-n+1 *
FROM publish
WHERE (id NOT IN
(SELECT TOP n-1 id
FROM publish))
id 為publish 表的關鍵字
我當時看到這篇文章的時候,真的是精神為之一振,覺得思路非常得好。等到後來,我在作辦公自動化系統(ASP.Net+ C#+SQL Server)的時候,忽然想起了這篇文章,我想如果把這個語句改造一下,這就可能是一個非常好的分頁存儲過程。於是我就滿網上找這篇文章,沒想到,文章還沒找到,卻找到了一篇根據此語句寫的一個分頁存儲過程,這個存儲過程也是目前較為流行的一種分頁存儲過程,我很後悔沒有爭先把這段文字改造成存儲過程:
CREATE PROCEDURE pagination2
(
@SQL nVARCHAR(4000), --不帶排序語句的SQL語句
@Page int, --頁碼
@RecsPerPage int, --每頁容納的記錄數
@ID VARCHAR(255), --需要排序的不重復的ID號
@Sort VARCHAR(255) --排序字段及規則
)
AS
DECLARE @Str nVARCHAR(4000)
SET @Str='SELECT TOP '+CAST(@RecsPerPage AS VARCHAR(20))+' * FROM ('+@SQL+') T WHERE T.'+@ID+'NOT IN
(SELECT TOP '+CAST((@RecsPerPage*(@Page-1)) AS VARCHAR(20))+' '+@ID+' FROM ('+@SQL+') T9 ORDER BY '+@Sort+') ORDER BY '+@Sort
PRINT @Str
EXEC sp_ExecuteSql @Str
GO
其實,以上語句可以簡化為:
SELECT TOP 頁大小 *
FROM Table1
WHERE (ID NOT IN
(SELECT TOP 頁大小*頁數 id
FROM 表
ORDER BY id))
ORDER BY ID
但這個存儲過程有一個致命的缺點,就是它含有NOT IN字樣。雖然我可以把它改造為:
SELECT TOP 頁大小 *
FROM Table1
WHERE not exists
(select * from (select top (頁大小*頁數) * from table1 order by id) b where b.id=a.id )
order by id
即,用not exists來代替not in,但我們前面已經談過了,二者的執行效率實際上是沒有區別的。
既便如此,用TOP 結合NOT IN的這個方法還是比用游標要來得快一些。
雖然用not exists並不能挽救上個存儲過程的效率,但使用SQL Server中的TOP關鍵字卻是一個非常明智的選擇。因為分頁優化的最終目的就是避免產生過大的記錄集,而我們在前面也已經提到了TOP的優勢,通過TOP 即可實現對數據量的控制。
在分頁算法中,影響我們查詢速度的關鍵因素有兩點:TOP和NOT IN。TOP可以提高我們的查詢速度,而NOT IN會減慢我們的查詢速度,所以要提高我們整個分頁算法的速度,就要徹底改造NOT IN,同其他方法來替代它。
我們知道,幾乎任何字段,我們都可以通過max(字段)或min(字段)來提取某個字段中的最大或最小值,所以如果這個字段不重復,那麼就可以利用這些不重復的字段的max或min作為分水嶺,使其成為分頁算法中分開每頁的參照物。在這裡,我們可以用操作符“>”或“<”號來完成這個使命,使查詢語句符合SARG形式。如:
Select top 10 * from table1 where id>200
於是就有了如下分頁方案:
select top 頁大小 *
from table1
where id>
(select max (id) from
(select top ((頁碼-1)*頁大小) id from table1 order by id) as T
)
order by id
在選擇即不重復值,又容易分辨大小的列時,我們通常會選擇主鍵。下表列出了筆者用有著1000萬數據的辦公自動化系統中的表,在以GID(GID是主鍵,但並不是聚集索引。)為排序列、提取gid,fariqi,title字段,分別以第1、10、100、500、1000、1萬、10萬、25萬、50萬頁為例,測試以上三種分頁方案的執行速度:(單位:毫秒)
頁 碼
方案1
方案2
方案3
1
60
30
76
10
46
16
63
100
1076
720
130
500
540
12943
83
1000
17110
470
250
1萬
24796
4500
140
10萬
38326
42283
1553
25萬
28140
128720
2330
50萬
121686
127846
7168
從上表中,我們可以看出,三種存儲過程在執行100頁以下的分頁命令時,都是可以信任的,速度都很好。但第一種方案在執行分頁1000頁以上後,速度就降了下來。第二種方案大約是在執行分頁1萬頁以上後速度開始降了下來。而第三種方案卻始終沒有大的降勢,後勁仍然很足。
在確定了第三種分頁方案後,我們可以據此寫一個存儲過程。大家知道SQL Server的存儲過程是事先編譯好的SQL語句,它的執行效率要比通過WEB頁面傳來的SQL語句的執行效率要高。下面的存儲過程不僅含有分頁方案,還會根據頁面傳來的參數來確定是否進行數據總數統計。
-- 獲取指定頁的數據
CREATE PROCEDURE pagination3
@tblName varchar(255), -- 表名
@strGetFIElds varchar(1000) = '*', -- 需要返回的列
@fldName varchar(255)='', -- 排序的字段名
@PageSize int = 10, -- 頁尺寸
@PageIndex int = 1, -- 頁碼
@doCount bit = 0, -- 返回記錄總數, 非 0 值則返回
@OrderType bit = 0, -- 設置排序類型, 非 0 值則降序
@strWhere varchar(1500) = '' -- 查詢條件 (注意: 不要加 where)
AS
declare @strSQL varchar(5000) -- 主語句
declare @strTmp varchar(110) -- 臨時變量
declare @strOrder varchar(400) -- 排序類型
if @doCount != 0
begin
if @strWhere !=''
set @strSQL = "select count(*) as Total from [" + @tblName + "] where "+@strWhere
else
set @strSQL = "select count(*) as Total from [" + @tblName + "]"
end
--以上代碼的意思是如果@doCount傳遞過來的不是0,就執行總數統計。以下的所有代碼都是@doCount為0的情況
else
begin
if @OrderType != 0
begin
set @strTmp = "<(select min"
set @strOrder = " order by [" + @fldName +"] desc"
--如果@OrderType不是0,就執行降序,這句很重要!
end
else
begin
set @strTmp = ">(select max"
set @strOrder = " order by [" + @fldName +"] asc"
end
if @PageIndex = 1
begin
if @strWhere != ''
set @strSQL = "select top " + str(@PageSize) +" "+@strGetFIElds+ " from [" + @tblName + "] where " + @strWhere + " " + @strOrder
else
set @strSQL = "select top " + str(@PageSize) +" "+@strGetFIElds+ " from ["+ @tblName + "] "+ @strOrder
--如果是第一頁就執行以上代碼,這樣會加快執行速度
end
else
begin
--以下代碼賦予了@strSQL以真正執行的SQL代碼
set @strSQL = "select top " + str(@PageSize) +" "+@strGetFIElds+ " from ["
+ @tblName + "] where [" + @fldName + "]" + @strTmp + "(["+ @fldName + "]) from (select top " + str((@PageIndex-1)*@PageSize) + " ["+ @fldName + "] from [" + @tblName + "]" + @strOrder + ") as tblTmp)"+ @strOrder
if @strWhere != ''
set @strSQL = "select top " + str(@PageSize) +" "+@strGetFIElds+ " from ["
+ @tblName + "] where [" + @fldName + "]" + @strTmp + "(["
+ @fldName + "]) from (select top " + str((@PageIndex-1)*@PageSize) + " ["
+ @fldName + "] from [" + @tblName + "] where " + @strWhere + " "
+ @strOrder + ") as tblTmp) and " + @strWhere + " " + @strOrder
end
end
exec (@strSQL)
GO
上面的這個存儲過程是一個通用的存儲過程,其注釋已寫在其中了。
在大數據量的情況下,特別是在查詢最後幾頁的時候,查詢時間一般不會超過9秒;而用其他存儲過程,在實踐中就會導致超時,所以這個存儲過程非常適用於大容量數據庫的查詢。
筆者希望能夠通過對以上存儲過程的解析,能給大家帶來一定的啟示,並給工作帶來一定的效率提升,同時希望同行提出更優秀的實時數據分頁算法。
四、聚集索引的重要性和如何選擇聚集索引
在上一節的標題中,筆者寫的是:實現小數據量和海量數據的通用分頁顯示存儲過程。這是因為在將本存儲過程應用於“辦公自動化”系統的實踐中時,筆者發現這第三種存儲過程在小數據量的情況下,有如下現象:
1、分頁速度一般維持在1秒和3秒之間。
2、在查詢最後一頁時,速度一般為5秒至8秒,哪怕分頁總數只有3頁或30萬頁。
雖然在超大容量情況下,這個分頁的實現過程是很快的,但在分前幾頁時,這個1-3秒的速度比起第一種甚至沒有經過優化的分頁方法速度還要慢,借用戶的話說就是“還沒有Access數據庫速度快”,這個認識足以導致用戶放棄使用您開發的系統。
筆者就此分析了一下,原來產生這種現象的症結是如此的簡單,但又如此的重要:排序的字段不是聚集索引!
本篇文章的題目是:“查詢優化及分頁算法方案”。筆者只所以把“查詢優化”和“分頁算法”這兩個聯系不是很大的論題放在一起,就是因為二者都需要一個非常重要的東西――聚集索引。
在前面的討論中我們已經提到了,聚集索引有兩個最大的優勢:
1、以最快的速度縮小查詢范圍。
2、以最快的速度進行字段排序。
第1條多用在查詢優化時,而第2條多用在進行分頁時的數據排序。
而聚集索引在每個表內又只能建立一個,這使得聚集索引顯得更加的重要。聚集索引的挑選可以說是實現“查詢優化”和“高效分頁”的最關鍵因素。
但要既使聚集索引列既符合查詢列的需要,又符合排序列的需要,這通常是一個矛盾。
筆者前面“索引”的討論中,將fariqi,即用戶發文日期作為了聚集索引的起始列,日期的精確度為“日”。這種作法的優點,前面已經提到了,在進行劃時間段的快速查詢中,比用ID主鍵列有很大的優勢。
但在分頁時,由於這個聚集索引列存在著重復記錄,所以無法使用max或min來最為分頁的參照物,進而無法實現更為高效的排序。而如果將ID主鍵列作為聚集索引,那麼聚集索引除了用以排序之外,沒有任何用處,實際上是浪費了聚集索引這個寶貴的資源。
為解決這個矛盾,筆者後來又添加了一個日期列,其默認值為getdate()。用戶在寫入記錄時,這個列自動寫入當時的時間,時間精確到毫秒。即使這樣,為了避免可能性很小的重合,還要在此列上創建UNIQUE約束。將此日期列作為聚集索引列。
有了這個時間型聚集索引列之後,用戶就既可以用這個列查找用戶在插入數據時的某個時間段的查詢,又可以作為唯一列來實現max或min,成為分頁算法的參照物。
經過這樣的優化,筆者發現,無論是大數據量的情況下還是小數據量的情況下,分頁速度一般都是幾十毫秒,甚至0毫秒。而用日期段縮小范圍的查詢速度比原來也沒有任何遲鈍。
聚集索引是如此的重要和珍貴,所以筆者總結了一下,一定要將聚集索引建立在:
1、您最頻繁使用的、用以縮小查詢范圍的字段上;
2、您最頻繁使用的、需要排序的字段上。
結束語:
本篇文章匯集了筆者近段在使用數據庫方面的心得,是在做“辦公自動化”系統時實踐經驗的積累。希望這篇文章不僅能夠給大家的工作帶來一定的幫助,也希望能讓大家能夠體會到分析問題的方法;最重要的是,希望這篇文章能夠拋磚引玉,掀起大家的學習和討論的興趣,以共同促進,共同為公安科技強警事業和金盾工程做出自己最大的努力。
最後需要說明的是,在試驗中,我發現用戶在進行大數據量查詢的時候,對數據庫速度影響最大的不是內存大小,而是CPU。在我的P4 2.4機器上試驗的時候,查看“資源管理器”,CPU經常出現持續到100%的現象,而內存用量卻並沒有改變或者說沒有大的改變。即使在我們的HP ML 350 G3服務器上試驗時,CPU峰值也能達到90%,一般持續在70%左右。
本文的試驗數據都是來自我們的HP ML 350服務器。服務器配置:雙Inter Xeon 超線程 CPU 2.4G,內存1G,操作系統Windows Server 2003 Enterprise Edition,數據庫SQL Server 2000 SP3。
大家可以訪問以下公安網網址或互聯網網址來體驗一下我們的“千萬級”數據庫的辦公自動化(ASP.Net+C#語言)。
http://10.59.121.11:90
http://www.xx110.Net/OA
微軟MCSE系統工程師
微軟MCDBA數據庫工程師
新鄉市公安局通信科 黨玉龍
參考文獻:
[1]《SQL Server 7編程技術內幕》,(美)John Papa,Matthew Shepker著,機械工業出版社
[2]《SQL Server數據庫原理 ——設計與實現》,微軟亞洲研究院著,清華大學出版社
[3] temp=9.089297E-02">http://community.csdn.Net/Expert/topic/2987/2987172.XML?temp=9.089297E-02,鄒建,CSDN論壇
[4]互聯網