用臨時表改善嵌套SQL語句的執行速度
左直拳
這兩天檢查一條嵌套SQL語句,發覺非常耗時。形如:
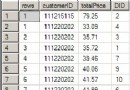
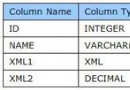
SELECT KeyId,COUNT(1) AS Num
FROM Table1
WHERE 1=1
AND CreateDate>='2007-09-21'
AND KeyId IN(SELECT KeyId FROM Table2 WHERE Id=1611)
GROUP BY KeyId
究其原因,大約該SQL語句執行的步驟是從Table1中每拿出一條記錄,都要執行
IN(SELECT KeyId FROM Table2 WHERE Id=1611) 一番
靠,數據庫也太弱智了吧。學編譯方法時就知道,編譯器會自動優化代碼,將一些計算從循環中提取出來,數據庫怎麼就不能先查找出
(SELECT KeyId FROM Table2 WHERE Id=1611)
的結果,然後再代入整條SQL語句中執行呢?
先是這樣修改:
SELECT a.KeyId,COUNT(1) AS Num
FROM Table1 a
, (SELECT KeyId FROM Table2 WHERE Id=1611) AS b
WHERE 1=1
AND a.CreateDate>='2007-09-21'
AND a.KeyId=b.KeyId
GROUP BY a.KeyId
結果發現沒什麼改進,有時甚至效果更壞。
把心一橫,祭出臨時表來:
SELECT KeyId INTO t# FROM Table2 WHERE Id=1611;
SELECT a.KeyId,COUNT(1) AS Num
FROM Table1 a
, t# AS b
WHERE 1=1
AND a.CreateDate>='2007-09-21'
AND a.KeyId=b.KeyId
GROUP BY a.KeyId;
DROP TABLE #t;
結果速度改善非常明顯。不必擔心並發操作時臨時表會有沖突,說這個會話創建了一個t#,那個會話也創建了一個t#。臨時表就好象局部變量,只在某個會話裡有意義。