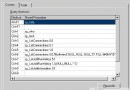
2.如果想讓服務器上所有的存儲表都區分大小寫就需要在安裝服務器時設置服務器的排序規則
或者 運行
alter database testgrass collate Chinese_PRC_CS_AI
3.如果修改整個服務器的默認排序規則,用Rebuildm.exe重建master庫
SQL Server\80\Tools\Binn\rebuildm.exe
4.或者<a href=>圖解</a>
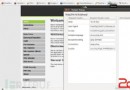
1.先打開oblog數據庫的oblog_user表,右鍵點擊,選設計表
2.找到username字段
3.然後找到下面的排序規則
4.在彈出的對話框中選擇區分大小寫
參考:
我們在create table時經常會碰到這樣的語句,例如:
passWord nvarchar(10)collate chinese_prc_ci_as null,
那它到底是什麼意思呢?不妨看看下面:
首先,collate是一個子句,可應用於數據庫定義或列定義以定義排序規則,或應用於字符串表達式以應用排序規則投影。語法是:
collate collation_name
collation_name ::={Windows_collation_name}|{sql_collation_name}
參數collate_name是應用於表達式、列定義或數據庫定義的排序規則的名稱。collation_name 可以只是指定的 Windows_collation_name 或SQL_collation_name。
Windows_collation_name 是 Windows 排序規則的排序規則名稱。參見 Windows 排序規則名稱。
SQL_collation_name 是 SQL 排序規則的排序規則名稱。參見 SQL 排序規則名稱。
下面簡單介紹一下排序規則:
什麼叫排序規則呢?MS是這樣描述的:"在 Microsoft SQL Server 2000 中,字符串的物理存儲由排序規則控制。排序規則指定表示每個字符的位模式以及存儲和比較字符所使用的規則。"
在查詢分析器內執行下面語句,可以得到SQL SERVER支持的所有排序規則。
select * from ::fn_helpcollations()
排序規則名稱由兩部份構成,前半部份是指本排序規則所支持的字符集。如:
Chinese_PRC_CS_AI_WS
前半部份:指UNICODE字符集,Chinese_PRC_指針對大陸簡體字UNICODE的排序規則。
排序規則的後半部份即後綴 含義:
_BIN 二進制排序
_CI(CS) 是否區分大小寫,CI不區分,CS區分
_AI(AS) 是否區分重音,AI不區分,AS區分
_KI(KS) 是否區分假名類型,KI不區分,KS區分
_WI(WS) 是否區分寬度 WI不區分,WS區分
區分大小寫:如果想讓比較將大寫字母和小寫字母視為不等,請選擇該選項。
區分重音:如果想讓比較將重音和非重音字母視為不等,請選擇該選項。如果選擇該選項,比較還將重音不同的字母視為不等。
區分假名:如果想讓比較將片假名和平假名日語音節視為不等,請選擇該選項。
區分寬度:如果想讓比較將半角字符和全角字符視為不等,請選擇該選項