一、不合理的索引設計
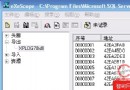
例:表record有620000行,試看在不同的索引下,下面幾個 SQL的運行情況:
1.在date上建有一非個群集索引
select count(*) from record where date > ′19991201′ and date < ′19991214′and amount > 2000 (25秒) select date,sum(amount) from record group by date (55秒) select count(*) from record where date > ′19990901′ and place in (′BJ′,′SH′) (27秒)
分析:
date上有大量的重復值,在非群集索引下,數據在物理上隨機存放在數據頁上,在范圍查找時,必須執行一次表掃描才能找到這一范圍內的全部行。
2.在date上的一個群集索引
select count(*) from record where date > ′19991201′ and date < ′19991214′ and amount > 2000 (14秒) select date,sum(amount) from record group by date (28秒) select count(*) from record where date > ′19990901′ and place in (′BJ′,′SH′)(14秒)
分析:
在群集索引下,數據在物理上按順序在數據頁上,重復值也排列在一起,因而在范圍查找時,可以先找到這個范圍的起末點,且只在這個范圍內掃描數據頁,避免了大范圍掃描,提高了查詢速度。
3.在place,date,amount上的組合索引
select count(*) from record where date > ′19991201′ and date < ′19991214′ and amount > 2000 (26秒) select date,sum(amount) from record group by date (27秒) select count(*) from record where date > ′19990901′ and place in (′BJ, ′SH′)(< 1秒)
分析:
這是一個不很合理的組合索引,因為它的前導列是place,第一和第二條SQL沒有引用place,