在本系列的上一篇文章中,我列舉了目前三大數據庫(Oracle、DB2、SQL Server)在最新版本中使用的壓縮技術的相關鏈接,關於SQL Server 2008的相關信息是最少的,因為直到目前為止,我們還不能拿到具有數據壓縮功能的SQL Server 2008版本。一個好消息是,在SQL Server 2008的下一個社區預覽版(CTP6)中,我們終於能夠看到“數據壓縮”功能的廬山真面目了(注:11月剛剛發布的SQL Server 2008社區預覽版為CTP5)。這個好消息來源於SQL Server存儲引擎開發組的博客Data Compression will be available in CTP-6,在這篇博客(博客作者Sunil Agarwal為SQL Server Storage Engine組的一名程序經理)中同時提到,數據壓縮功能將是企業版獨有的。
在Types of data compression in SQL Server 2008這篇博客中, Sunil Agarwal提到了在SQL Server 2008中采用的兩種壓縮策略:
(1)以變長格式存儲所有的定長數據類型。在本系列的上一篇文章中,我提到過在SQL Server 2005 SP2中提供的使用vardecimal類型來存儲decimal/numeric數據類型以節省存儲空間的問題,有興趣的朋友可以參考上一篇文章最後列出的相關鏈接以獲取更多信息。在SQL Server 2008中,微軟將這一思想擴展到了所有的定長數據類型,例如integer,char,float類型。需要注意的是,雖然SQL Server 2008以變長格式存儲所有的定長數據類型,但這只是一種存儲的具體實現機制,並不會改變任何語義上的東西,任何客戶的程序都不需要修改,因為它根本不關心也不必知道數據庫內部具體的數據存儲方式。
例子一:假設一個表中有一個32位整數列(integer),但是該列的值均在(0~255或-128~127)的范圍內,那麼SQL Server 2008就可以只用一個字節來存儲該列的值,這與之前版本的SQL Server總是使用4個字節來存儲該列相比,就節省了75%的空間。
例子二:假設一個表中有一個定長字符串列CHAR(100),在以前的SQL Server版本中,該列總是使用100個字節來存儲(即使實際的字符串沒有100個字節,也會在其後填充空格以達到長度正好為100)。但是在SQL Server 2008中,該列將根據實際字符串的長度來進行存儲,例如"Hello"將只耗費5個字節存儲空間,而"This is a longer string"將只需23個字節存儲,分別帶來95%和77%的存儲空間的節省。
當然,在上述例子一中如果實際的數值變化范圍超過了一個字節能夠表示的范圍,那麼相應的壓縮比就會降低;對於例子二也類似,如果實際的字符串長度接近100,那麼壓縮效果也會大大降低。這意味著壓縮的效果將依賴於實際的數據值的分布,同時也依賴於表的架構定義,這可能不那麼明顯,但是想象一下上述的例子二,如果將列的定義改為CHAR(150),顯然壓縮的效果就更為顯著。另外請注意,NULL值是不需要占用任何存儲空間的(參見下面的行格式)。
在SQL Server 2008 Data Compression這篇博客中,博客作者Shailan Chudasama用一副圖形象的說明了上述例子一描述的場景:

圖1 SQL Server 2008以變長格式存儲整數類型列
在上面的圖1中,我們注意到在SQL Server 2008中,存儲一個字節能夠表示的整數實際需要1.5個字節來存儲,而不是我們上面例子一中所描述的一個字節,為什麼會是這樣呢?我們知道,在SQL Server中存儲一個變長列時,需要額外的存儲空間來存儲該列在一個數據行中的位置,以便能夠在需要的時候快速訪問到該列,以下這幅圖說明了在SQL Server 2000/2005中一個數據行是如何存儲的:

圖2 SQL Server 2000/2005中的數據行存儲格式
從上面這副圖2中,我們可以清楚的看到,一個定長列除了存儲該列數據本身以外,是不需要額外的存儲空間的。而對於一個變長列,除了該列數據本身所占的空間外,每個變長列還需要2個額外的字節來存儲該列在數據行中的位置,這就是上圖中的“Column Offset Array”。從這個意義上來將,將smallint甚至我們例子一中提到的integer數據類型以變長方式存儲的壓縮效果就幾乎毫無意義了。因此在SQL Server 2008中針對這種情況進行了特殊的優化,那就是如果該列的長度不超過8字節,那麼每列只需要4bit來存儲上述的列偏移,這就清楚的解釋了圖1中的4Bits從何而來了。需要提醒大家的上,圖2中的數據行存儲格式在SQL Server 2008中依然有效,而且是默認的存儲格式(我猜測應該是不啟用數據壓縮時所使用存儲格式)。
在SQL Server 2008中,這種壓縮策略是通過在DDL(數據操縱語言)中的“ROW COMPRESSION"而暴露出來的,這也就是我們通常所說的行級壓縮(Row level compression)。
(2) 與上面所說的行級壓縮相對應,在SQL Server 2008中所采用的另外一種壓縮策略是”頁級壓縮(Page level compression)",它是在一個數據頁內部減少一個或多個數據行的列之間的數據冗余。它的設計思想是:在一個數據頁(對於SQL Server為8KB)內部,對於冗余數據只存儲一次,然後在用到的地方進行多次引用而非多次重復存儲,以此來減少存儲空間的占用。例如如下的表:
Table employee( name varchar
0);">(100),
status varchar (10) default ‘full time’) 對於這樣一個表,如果插入很多數據行,那麼很可能很多行的status列都是使用默認的"full time“值。這種情況下,SQL Server 2008可以通過在數據頁內只存儲"full time"一次,然後在其他需要的地方進行引用,這樣存儲空間自然減少了。很顯然,這種壓縮策略的效果取決於冗余數據的數量。
在SQL Server 2008 Data Compression這篇博客中,博客作者Shailan Chudasama用以下兩幅圖說明了頁級壓縮的實現原理,與行級壓縮一樣,頁級壓縮也是通過DDL暴露給用戶的。
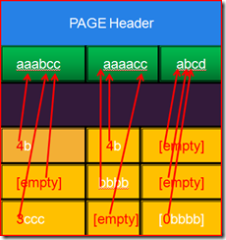
圖3 通過引用減少冗余數據的存儲

圖4 冗余數據字典
從上面兩幅圖,我們可以猜想在SQL Server 2008中的頁級壓縮中,采用了類似LZ78/LZ77這樣的字典壓縮算法的思想,到底是否這樣,我們暫且拭目以待。
在Sunil Agarwal的另外一篇博客Estimating the space savings with data compression中,他使用如下的表進行了壓縮效果的測試:
create table t1_big (c1 int, c2 int, c3 char(8000))
go
declare @i int
select @i = 0
while (@i < 6000
0);">)
begin
insert into t1_big values (@i, @i + 6000, replicate (‘a’, 60))
set @i = @i + 1
end
-- find the current size of the uncompressed table
EXEC sp_spaceused N''文章整理:
ong>
0);">t1_big''
-- 輸出結果如下:
Name Rows Reserved Data Index_size unused
t1_big 6000 48008 KB 48000 KB 8 KB 0 KB
-- 估計行壓縮的效果
exec sp_estimate_data_compression_savings
''dbo
0);">'', ''t1_big'', NULL, NULL, ''ROW''
object_name schema_name index_id partition_number
----------- ----------- ------- -----------------
t1_big dbo 0 1
size_with_current_compression_setting(KB)
-----------------------------------------
48008
0);">
size_with_requested_compression_setting(KB)
-------------------------------------------
472
sample_size_with_current_compression_setting(KB)
-----------------------------------------------
39648
sample_size_with_requested_compression_setting(KB)
--------------------------------------------------
392
--估計頁級壓縮的效果
--
128);"> estimate the PAGE compression
exec sp_estimate_data_compression_savings
''dbo'', ''t1_big'', NULL, NULL, ''PAGE''
object_name schema_name index_id partition_number
----------- ---------------- ---------- -----------------
t1_big dbo 0 1
size_with_current_compression_setting(KB)
-----------------------------------------
48008
size_with_requested_compression_setting(KB)
-------------------------------------------
80
sample_size_with_current_compression_setting(KB)
-----------------------------------------------
39960
sample_size_with_requested_compression_setting(KB)
--------------------------------------------------
128);">
72
以下是目前能夠找到的關於SQL Server 2008的數據壓縮的相關信息:
(1) SQL Server 2008 Data Compression
(2) Data Compression: Why Do we need it?
(3) Data compression techniques and trade offs
(4) Katmai (Sql 2008) - Data Compression (including Backup Compression)
(5) Why not use compressed disk files or disk volumes?
(6) Estimating the space savings with data compression
(7) Types of data compression in SQL Server 2008
(8) Data Compression will be available in CTP-6
最後說些題外話,在接下來的SQL Server系列文章中,我除了將會繼續關注SQL Server 2008的新特性之外,還將會嘗試解開SQL Server中的查詢優化的秘密。提到SQL Server的查詢優化,就不能不提到Goetz Graefe這個牛人,此君浸淫查詢優化多年,於上世紀九十年代中期加入微軟,應該是SQL Server的查詢優化機制的主要設計者吧(我猜測的)。不過據悉此君已於今年初離開微軟加盟HP實驗室,這對微軟來說應該是一個損失吧。