公司的業務系統中存在一個大的日志表,表大約是這樣:
create table log
(
logtime date, -- PK
username varchar2(20)
);
現有需求如下:統計日志表中,兩小時內使用過系統的用戶在三天內的日志數。
最初編寫的查詢如下:

WITH
result1 AS
(
SELECT DISTINCT username
FROM log
WHERE logtime>=sysdate - 1/24*2
)
SELECT log.username, count(1) as times
FROM log INNER JOIN result1 ON log.username=result1.username
WHERE logtime>=sysdate - 3
GROUP BY log.username; 後來發現,log表記錄達到300萬後,查詢非常慢。測試後發現是因為log表和臨時視圖result1連接的時候,采用NESTED LOOPS,於是增加提示,采用HASH連接:
WITH
result1 AS
(
SELECT DISTINCT username
FROM log
WHERE logtime>=sysdate - 1/24*2
)

SELECT /**//*+USE_HASH(log)*/ log.username, count(1) as times
FROM log INNER JOIN result1 ON log.username=result1.username
WHERE logtime>=sysdate - 3
GROUP BY log.username; 效率果然提高了很多,但是還是不令人滿意。
測試的過程中發現,如果不先選取兩小時內的用戶,而直接選取三天內的所有用戶來統計,效率非常高。看來,性能的瓶頸還是在表連接上。在已經選用HASH連接的情況下,只有想辦法減少連接的記錄數了。於是嘗試寫了如下查詢:
WITH
result1 AS
(
SELECT DISTINCT username
FROM log
WHERE logtime>=sysdate - 1/24*2
),
result2 AS
(
SELECT username, count(1) AS times
FROM log
WHERE logtime>=sysdate - 3
GROUP BY username
)
SELECT result2.username, result1.times
FROM result1 INNER JOIN result2 ON result1.username=result2.username; 性能高了好多好多!!!
哦,還忘記了點東西:
WITH
result1 AS
(
SELECT DISTINCT username
FROM log
WHERE logtime>=sysdate - 1/24*2
),
result2 AS
(
SELECT username, count(1) AS times
FROM log
WHERE logtime>=sysdate - 3
GROUP BY username
)
SELECT /**//*+USE_HASH(result1)*/ result2.username, result1.times
FROM result1 INNER JOIN result2 ON result1.username=result2.username; 測試一下,性能又高了一點點。
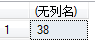
3天內的日志數是300萬,第一個查詢執行了1小時以上,優化後的最後一個查詢只花了112秒。
總結下來,這個查詢優化的思路為:大表變小表,小表再連接。
希望有高手能夠提出更好的想法,謝謝!