cube操作符
要使用cube,首先要了解group by
其實cube和rollup區別不太大,只是在基於group by 子句創建和匯總分組的可能的組合上有一定差別,
cube將返回的更多的可能組合。如果在 group by 子句中有n個列或者是有n個表達式的話,
sqlserver在結果集上會返回2的n-1次冪個可能組合。
注意:
使用cube操作符時,最多可以有10個分組表達式
在cube中不能使用all關鍵字
例子:
我們在數據庫統計中常常要查詢以下情況:
如一個定單數據庫,我們要知道每個定單的每個產品數量,每個定單的所有產品數量,所有定單的某一產品數量,所有定單所有產品總量這些匯總信息。這時使用cube就十分方便了。當然不需要這麼多信息或者只想知道某一具體產品、具體某一定單,某一時間關系(前,後,之間)等等具體信息的話,只需在where中限定即可
先舉一個例子,是所有情況的:
一個數據庫表中記載了一個產品定購情況:
現共有三種產品(1,2,3),已經下了兩個定單(1,2)
sql語句:
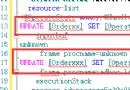
select productid,orderid SUM(quantity) AS total FROM order GROUP BY productid,orderid WITH CUBE
ORDER BY productid,orderid
運行後得到結果:
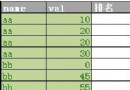
productid orderid total
null null 95 所有定單所有產品總量
null 1 30 定單1所有產品數量
null 2 65 定單2所有產品數量
1 null 15 所有定單產品1總量
1 1 5 定單1產品1數量
1 2 10 定單2產品1數量
2 null 35 所有定單產品2總量
2 1 10 定單1產品2數量
2 2 25 定單2產品2數量
3 null 45 所有定單產品3總量
3 1 15 定單1產品3數量
3 2 30 定單2產品3數量
如果您對sqlserver group by 聚集有一定理解的話,您就可以理解cube操作符的用法和作用。其實在現實運用中cube還是很好有的,我們經常要對一些數據庫數據進行統計,以利於我們更好的掌握情況
我想電子商務可以更好的實現合理配置資源,盡量減少庫存,只有更好的掌握生產、銷售數據的具體情況,才能實現資源的合理配置。希望以後的企業象dell一樣,不要象長虹等彩電廠商。