用戶對數據庫最頻繁的操作是進行數據查詢。一般情況下,數據庫在進行查詢操作時需要對整個表進行數據搜索。當表中的數據很多時,搜索數據就需要很長的時間,這就造成了服務器的資源浪費。為了提高檢索數據的能力,數據庫引入了索引機制。本章將介紹索引的概念及其創建與管理。
8.1.1 索引的概念
索引是一個單獨的、物理的數據庫結構,它是某個表中一列或若干列值的集合和相應的指向表中物理標識這些值的數據頁的邏輯指針清單。索引是依賴於表建立的,它提供了數據庫中編排表中數據的內部方法。一個表的存儲是由兩部分組成的,一部分用來存放表的數據頁面,另一部分存放索引頁面。索引就存放在索引頁面上,通常,索引頁面相對於數據頁面來說小得多。當進行數據檢索時,系統先搜索索引頁面,從中找到所需數據的指針,再直接通過指針從數據頁面中讀取數據。從某種程度上,可以把數據庫看作一本書,把索引看作書的目錄,通過目錄查找書中的信息,顯然較沒有目錄的書方便、快捷。
索引和關鍵字及約束有較大的聯系。關鍵字可以分為兩類:一種是邏輯關鍵字,即在 “數據庫基礎章”節中介紹的;另一種是物理關鍵字,它用來定義索引的列,也即索引。
8.1.2 索引的結構
(1) 索引的B-樹結構
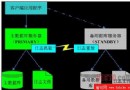
SQL Server 中的索引是以B-樹結構來維護的,如圖8-1 所示。B-樹是一個多層次、自維護的結構。一個B-樹包括一個頂層,稱為根節點(Root Node);0 到多個中間層(Intermediate);一個底層(Level 0),底層中包括若干葉子節點(Leaf Node)。在圖 8-1 中,每個方框代表一個索引頁,索引列的寬度越大,B-樹的深度越深,即層次越多,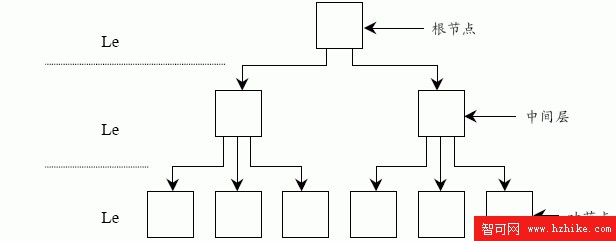
(圖文)
讀取記錄所要訪問的索引頁就越多。也就是說,數據查詢的性能將隨索引列層次數目的增加而降低。 圖8-1 索引的B-樹結構
在SQL Server 的數據庫中按存儲結構的不同將索引分為兩類:簇索引(Clustered Index)和非簇索引(Nonclustered Index)。
(2) 簇索引簇索引對表的物理數據頁中的數據按列進行排序,然後再重新存儲到磁盤上,即簇索引與數據是混為一體,的它的葉節點中存儲的是實際的數據。由於簇索引對表中的數據一一進行了排序,因此用簇索引查找數據很快。但由於簇索引將表的所有數據完全重新排列了,它所需要的空間也就特別大,大概相當於表中數據所占空間的120% 。表的數據行只能以一種排序方式存儲在磁盤上,所以一個表只能有一個簇索引。
(3) 非簇索引非簇索引具有與表的數據完全分離的結構,使用非簇索引不用將物理數據頁中的數據按列排序。非簇索引的葉節點中存儲了組成非簇索引的關鍵字的值和行定位器。行定位器的結構和存儲內容取決於數據的存儲方式。如果數據是以簇索引方式存儲的,則行定位器中存儲的是簇索引的索引鍵;如果數據不是以簇索引方式存儲的,這種方式又稱為堆存儲方式(Heap Structure),則行定位器存儲的是指向數據行的指針。非簇索引將行定位器按關鍵字的值用一定的方式排序,這個順序與表的行在數據頁中的排序是不匹配的。由於非簇索引使用索引頁存儲因此它比簇索引需要更多的存儲空間且檢索效率較低但一個表只能建一個簇索引,當用戶需要建立多個索引時就需要使用非簇索引了。從理論上講,一個表最多可以建249 個非簇索引。