提示:數據挖掘是從大型數據集中發現可行信息的過程。數據挖掘使用數學分析來派生存在於數據中的模式和趨勢。通常,由於這些模式的關系過於復雜或涉及數據過多,因此使用傳統數據浏覽無法發現這些模式。 這些模式和趨勢可以被收集在一起並定義為數據挖掘模型。挖掘模型可以應
盡管關系圖中所示的過程是一個循環過程,但是每個步驟並不需要直接執行到下一個步驟。創建數據挖掘模型是一個動態、交互的過程。浏覽完數據之後,您可能會發現數據不足,無法創建適當的挖掘模型,因此必須查找更多的數據。或者,您可以生成數個模型,但隨後發現這些模型無法充分地回答定義的問題,因此必須重新定義問題。您可能必須在部署模型之後對其進行更新,因為又出現了更多的可用數據。可能需要多次重復過程中的每個步驟才能創建良好的模型。
SQL Server 2008 提供用於創建和使用數據挖掘模型的集成環境,稱為 Business Intelligence Development Studio。該環境包括數據挖掘算法和工具,使用這些算法和工具更易於生成用於各種項目的綜合解決方案。
創建數據挖掘解決方案後,您可以使用 SQL Server Management Studio 維護和浏覽該解決方案。
定義問題
與以下關系圖的突出顯示相同,數據挖掘過程的第一步就是明確定義業務問題,並考慮解答該問題的方法。
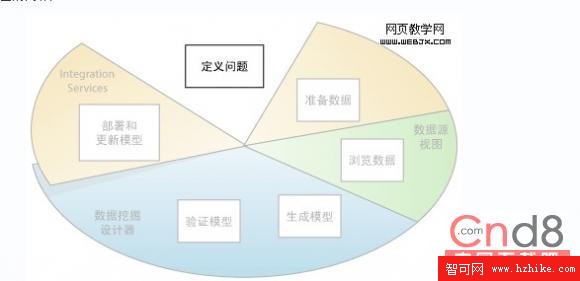
該步驟包括分析業務需求,定義問題的范圍,定義計算模型所使用的度量,以及定義數據挖掘項目的特定目標。這些任務轉換為下列問題:
◆ 您在查找什麼?您要嘗試找到什麼類型的關系?
◆ 您要嘗試解決的問題是否反映了業務策略或流程?
◆ 您要通過數據挖掘模型進行預測,還是僅僅查找受關注的模式和關聯?
◆ 您要嘗試預測數據集的哪個屬性?
◆ 列如何關聯?或者如果有多個表,則表如何關聯?
◆ 如何分發數據?數據是否具有季節性性質?數據是否可以准確反映業務流程?
若要回答這些問題,可能必須進行數據可用性研究,必須調查業務用戶對可用數據的需求。如果數據不支持用戶的需求,則還必須重新定義項目。
此外,還需要考慮如何將模型結果納入用於度量業務進度的關鍵績效指標 (KPI)。