在談到R2中的商務智能,就肯定離不開多維數據。簡單的說,多維數據就好比是將數據存放在一個N維的數組中,而不是像傳統關系數據庫那樣以記錄的形式存放。在商務智能中,多維數據的價值是顯而易見的。如可以提高數據的處理速度、提高查詢效率。而這些優勢正是商務智能中所必需的。
不過這篇文章的重點並不是多維數據在商務智能中的應用。筆者主要談的是,針對多維數據,在排序過程中需要注意的事項。具體的來說,有如下幾點。
一、是否需要區分大小寫?
在考慮排序的時候,第一個需要考慮的是是否區分大小寫。在普通數據庫應用中,一般都需要區分大小寫。但是在多維數據中,則具體需要根據用戶的需求來定。如在商務智能過程中,有可能數據量比較多,大小寫比較難以統一。此時在排序過程中,如果區分大小寫的話,那麼可能最後的所需要顯示的結果跟用戶最終的需要有所差別。如用戶可能內容Name與NAME是同一個字段,需要排列在一起。而如果區分大小寫排序的話,他們則有可能不會排在一起。因為如果區分大小寫的話,排序時小寫字母將排在對應的大寫字母之前。相反,如不區分大小寫字母的話,則排序時,系統會將大寫字與小寫字母視為相同的字符(注意數據庫中實際存儲時大小寫字符仍然是不同的)。
具體設置方法:
為此是否區分大小寫字母,對於系統來說沒有什麼影響,主要是看用戶的需要。數據庫管理員可以在排序規則設置或者分析服務器屬性上來進行排序規則的設置。如在安裝向導中的排序規則設置頁簽中通過“排序規則設置”頁面上的“區分大小寫”選項來進行設置。或者在安裝完成之後選擇“分析服務器屬性”對話框中的“語言/排序規則”頁面上的“區分大小寫選項”來調整。
二、BIN1與BIN2之間的區別。
BIN1 選項是指為每個字符所定義的位模式對報表中的數據進行排序和比較。而BIN2則是根據Unicode數據的Unicode碼位對數據進行排序和比較。當數據量比較多的時候(如在商務智能系統中要對大量數據進行聯機分析),選擇這兩種不同的排序方式,會有很大的差異。為此在設計多維數據模型的時候,數據庫管理員要對這兩個選項之間的差別,特別是應用效果上的差異,要有深刻的認識。
具體的說,BIN1碼在排序時是會區分大小寫的(此時第一條談到的大小寫選項設置無效),而且也會區分重音。另外,這個排序規則的話,在數據量很多的時候,能夠表現出比較好的性能。而對於BIN2來說,其主要的優點在於在比較已經排序數據的應用程序中不需要對數據進行重新排序。也就是說,如果一張報表已經對數據進行了排序。然後需要在這個已經排序的報表中,查詢某個符合特定條件的數據,采用BIN2的時候,不需要重新排序。為此往往對於在報表中 (這張報表已經按特定的規則進行排序)查詢符合條件的記錄時,采用BIN2排序規則的方式比較合適。
另外需要注意的是,BIN2主要針對的是Unicode類型的數據,因為其主要是根據Unicode碼位來進行排序和比較的。那麼對於非Unicode類型的數據,其又會怎麼處理呢?如果系統遇到這種情況,那麼其采用的排序與比較的規則與BIN1相似。
總之,一般來說,采用BIN2方式,會讓應用程序的開發更為簡單,並且可以明顯提高應用程序的性能。
具體設置方法:
這也可以在安裝過程中或者分析服務器屬性中設置。具體的設置方法跟第一個排序規則的設置類似。主要是根據二進制(對應的是BIN1)和二進制2(對應的是BIN2)選項來指定。
三、采用Windows排序規則。
在多維數據中,Windows排序規則也是起效的。簡單的說,Windows排需規則根據關聯的Windows區域設置來定義字符數據的存儲規則。具體的說,Windows基本排需規則指定應用字典排序時所采用的字符表或者語言,以及用於存儲非Unicode字符數據的代碼頁。這句話聽起來比較拗口。其實它說的就是,在數據庫記錄排序的時候,按照的並不是數據庫中的設置,而是其Windows操作系統上的設置。如下圖所示,多維數據可以根據“區域和語言選項”中的相關參數來進行排序。
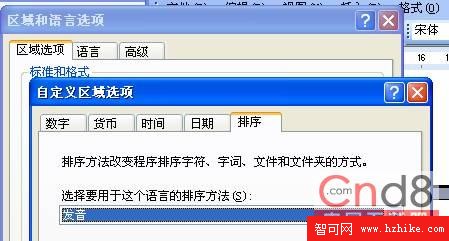
或者說,這裡的區域和語言選項的排需規則會替代數據庫中設置的排序規則。具體的說,需要注意以下幾個方面的內容。
一是對於二進制數據而言,二進制排需規則將會采用基於區域設置和數據類型定義的編碼值順序來對數據進行排序。也就是說,強制采用二進制排序規則。這主要是因為微軟可能考慮到,二進制排序規則相對來說,可以提高應用程序在排序時的性能。
二是對於Unicode數據或者非Unicode數據的排序措施。通常來說,如果采用了Windows排序規則的話,則對於Unicode來說,其采用的主要是基於Unicode碼位的排序方法。而如果是非Unicode類型的數據,則數據的比較將基於ANSI代碼頁中定義的碼位。注意需要注意,如果是Unicode數據類型的話,則系統將不會考慮區域選項中的自定義設置,而不會考慮數據庫中的設置,而直接采用其默認的排需規則,即采用基於 Unicode碼位的方法。可見,如果猜唷國內Windows排序規則的話,有時候數據庫的排序規則、區域與選項中的設置與排需規則的默認方法之間,他們幾個之間的關系會非常的復雜。數據庫管理員需要仔細分清楚,並且需要有充分的測試。
四、多種語言標識符情況下的排序處理。
對於商務智能中的聯機分析程序,可能會涉及到有多種語言標識符的情況。如現在有一個國際零售商業巨頭,其在中國、日本、韓國等多個國家都有其分支機構。在每年年末的時候,需要對這幾個國家的銷售數據進行聯機分析處理。而在各個國家部署數據庫的時候,顯然采用的是各個國家本國的語言標識符。在這種情況下,如果要對他們的記錄進行排序,該如何處理呢?
筆者認為,主要有兩種處理方式。第一種方式原理比較簡單,實現起來比較復雜。即先將其他的集中不同的語言標識符的記錄轉換成某一種語言標識符,然後再對數據進行排序與分析。在R2中提供了類似的工具。可以將不同語言標識符的記錄通過導入導出轉換成某種特定語言標識符的記錄。
第二種方式就是采用Windows排序規則。因為在默認情況下,雖然可以為報表分析工具制定多種語言標識符,但是不管數據庫管理員指定采用哪種類型的語言標識符,所有的數據報表采用的都是相同的Windows排序規則(即分析服務器上的Windows排序規則)。即使各個辦事處采用區域選項設置有所不同也沒有關系。因為其歸根結底是用的是一台服務器的Windows選項。不過在多維數據應用中,有時候仍然需要根據不同的語言標識符來進行排序。此時就需要用到多位數據庫中的Captioncolumn屬性。這個屬性就是用來指定某個特定對象的排序規則。而且這裡的設置優先級要高於Windows排序規則中的設置。如筆者在實際工作中,就比較喜歡使用這個屬性。如在具有多語言標識符的環境下,可以選擇讓系統采用最能夠支持各種語言要求的排序規則。