本人剛開始學數據挖掘,雖然之前看過一本《數據挖掘原理與應用:SQL Server 2005數據庫》,但是只是大體上了解了一些數據挖掘的概念,並沒有深入去了解一個算法。前段時間開始比較深入的學習,就以關聯規則作為學習的入口點。這才有了這篇文章。
Apriori algorithm是關聯規則裡一項基本算法。是由Rakesh Agrawal和Ramakrishnan Srikant兩位博士在1994年提出的關聯規則挖掘算法。關聯規則的目的就是在一個數據集中找出項與項之間的關系,也被稱為購物藍分析 (Market Basket analysis),因為“購物藍分析”很貼切的表達了適用該算法情景中的一個子集。
關於這個算法有一個非常有名的故事:"尿布和啤酒"。故事是這樣的:美國的婦女們經常會囑咐她們的丈夫下班後為孩子買尿布,而丈夫在買完尿布後又要順手買回自己愛喝的啤酒,因此啤酒和尿布在一起被購買的機會很多。這個舉措使尿布和啤酒的銷量雙雙增加,並一直為眾商家所津津樂道。
【1】一些概念和定義
資料庫(Transaction Database):存儲著二維結構的記錄集。定義為:D
所有項集(Items):所有項目的集合。定義為:I。
記錄(Transaction ):在資料庫裡的一筆記錄。定義為:T,T ∈ D
項集(Itemset):同時出現的項的集合。定義為:k-itemset(k項集),k-itemset ? T。除非特別說明,否則下文出現的k均表示項數。
支持度(Support):定義為 supp(X) = occur(X) / count(D) = P(X)。
1. 解釋一:比如選秀比賽,那個支持和這個有點類似,那麼多人(資料庫),其中有多少人是選擇(支持)你的,那個就是支持度;
2. 解釋二:在100個人去超市買東西的,其中買蘋果的有9個人,那就是說蘋果在這裡的支持度是 9,9/100;
3. 解釋三:P(X),意思是事件X出現的概率;
4. 解釋四:關聯規則當中是有絕對支持度(個數)和相對支持度(百分比)之分的。
置信度(Confidence/Strength): 定義為 conf(X->Y) = supp(X ∪ Y) / supp(X) = P(Y|X)。
在歷史數據中,已經買了某某(例如:A、B)的支持度和經過挖掘的某規則(例如:A=>B)中A的支持度的比例,也就是說買了A和B的人和已經買了 A的人的比例,這就是對A推薦B的置信度(A=>B的置信度)< /span>
候選集(Candidate itemset):通過向下合並得出的項集。定義為C[k]。
頻繁集(Frequent itemset):支持度大於等於特定的最小支持度(Minimum Support/minsup)的項集。表示為L[k]。注意,頻繁集的子集一定是頻繁集。
提升比率(提升度Lift):lift(X -> Y) = lift(Y -> X) = conf(X -> Y)/supp(Y) = conf(Y -> X)/supp(X) = P(X and Y)/(P(X)P(Y))
經過關聯規則分析後,針對某些人推銷(根據某規則)比盲目推銷(一般來說是整個數據)的比率,這個比率越高越好,我們稱這個規則為強規則;
剪枝步
只有當子集都是頻繁集的候選集才是頻繁集,這個篩選的過程就是剪枝步;
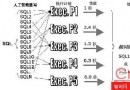
【2】Apriori優化:Fp-tree 算法
關鍵點:以樹形的形式來展示、表達數據的形態;可以理解為水在不同河流分支的流動過程;
生成Fp-tree的幾個點:
掃描原始項目集;
排列數據;
創建ROOT節點;
按照排列的數據進行元素的流動;
節點+1;
更多內容請自行學習
【3】Apriori優化:垂直數據分布
關鍵點:相當於把原始數據進行行轉列的操作,並且記錄每個元素的個數
更多內容請自行學習
【4】摘要:數據挖掘中關聯規則算法的研究
Apriori核心算法過程如下:
過單趟掃描數據庫D計算出各個1項集的支持度,得到頻繁1項集的集合。
連接步:為了生成,預先生成,由2個只有一個項不同的屬於的頻集做一個(k-2)JOIN運算得到的。
剪枝步:由於是的超集,所以可能有些元素不是頻繁的。在潛在k項集的某個子集不是中的成員是,則該潛在頻繁項集不可能是頻繁的可以從中移去。
通過單趟掃描數據庫D,計算中各個項集的支持度,將中不滿足支持度的項集去掉形成。
通過迭代循環,重復步驟2~4,直到有某個r值使得為空,這時算法停止。在剪枝步中的每個元素需在交易數據庫中進行驗證來決定其是否加入,這裡的驗證過程 是算法性能的一個瓶頸。這個方法要求多次掃描可能很大的交易數據庫。可能產生大量的候選集,以及可能需要重復掃描數據庫,是Apriori算法的兩大缺點。
目前,幾乎所有高效的發現關聯規則的並行數據挖掘算法都是基於Apriori算法的,Agrawal和Shafer 提出了三種並行算法:計數分發(Count Distribution)算法、數據分發(Data Distribution)算法和候選分發(Candidate Distribute)算法。
【5】總結
例子就暫時不舉例,因為網上的這些例子也是比較多的;
度量標准還有很多很多很多,如:Lift/Interest、All-confidence、Consine、Conviction、Jaccard、Leverage、Collective strength等等。
頻繁數據模型的分類比較多,需要慢慢理解;