眾所周知,SQL Server執行SQL語句的性能判定標准主要是IO讀取數大小。本文在不違反這一原則情況下,同時來分析一下部分SQL語句執行時,SQL Server內存的變化情況。
首先簡述一下SQL Server內存占用的特點。SQL Server所占用的內存除程序(即SQL Server引擎)外,主要包括緩存的數據(Buffer)和執行計劃(Cache)。SQL Server以8KB大小的頁為單位存儲數據。這個和SQL Server數據在磁盤上的存儲頁大小相同。當SQL Server執行SQL 語句時,如果需要的數據已經在其內存中,則直接從內存緩沖區讀取並進行必要的運算然後輸出執行結果。如果數據還未在內存中,則首先將數據從磁盤上讀入內存Buffer中。而我們通常評價SQL性能指標中的IO邏輯讀取數對應的正是從內存緩沖區讀取的頁數,而IO物理讀取數則對應數據從磁盤讀取的頁數。
注:以下的試驗在多人共享的開發測試服務器上也可以進行,因為實際上可以分別看到某個表所占用的內存情況。但為了方便,筆者在做此試驗時,在一個單獨的、確認沒有其它並發任務的數據庫上進行,因此所看到的內存變化正是每一次所執行的SQL語句引起的。
我們首先來看一個簡單的實例。創建下表:
Create Table P_User
( UserMobileStatus int NOT NULL,
MobileNo int NOT NULL,
LastOpTime DateTime Not NULL
)
然後為該表插入一定的數據:
Declare @i int
Set @i=28000
WHILE @i<29000
BEGIN
Insert Into P_User
Select @i % 2,@i,GetUTCDate()
Set @i=@i+1
END
然後我們在查詢分析器中首先執行:
Set Statistics IO ON
並按下Ctrl+M以顯示實際的執行計劃。
此時,可以開始進行我們的試驗了。為了准確觀察每一次SQL語句變化情況,在執行第一條SQL語句以前,我們首先清空SQL Server所占用的數據內存:
CHECKPOINT
GO
DBCC DROPCLEANBUFFERS
這將清空SQL Server所占用的數據緩沖區(此語句在生產服務器上慎用,因為將導致一段時間內後續的SQL語句執行變慢)。
測試1:在沒有索引的表上執行SQL語句1.1 執行全表選取或者低選擇性選取
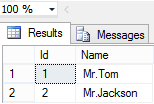
Select * From P_User
從SQL執行計劃可以看到,由於此時表中沒有任何索引,因此將產生Table Scan。而IO統計結果如下:
(1000 row(s) affected)
表'P_User'。掃描計數1,邏輯讀取4 次,物理讀取4 次,預讀0 次,lob 邏輯讀取0 次,lob 物理讀取0 次,lob 預讀0 次。
我們看一下數據庫內存中的情況。
首先查詢到我們所操作database的database_id:
Select database_id From sys.databases Where name='TestGDB'
然後使用該database_id從表中查看內存情況:
SELECT * FROM sys.dm_os_buffer_descriptors bd
WHERE database_id=5
order by allocation_unit_id,page_id
得到結果如下:

得到的結果中可以看到,除了必要的管理頁(一個PFS_Page和一個IAM_Page)外,內存中總共出現了4個Data_Page頁。這和剛才IO統計中看到的結果:邏輯讀為4,物理讀為4相同。由於是全表讀取,表明P_User表全部數據所占用的數據頁數也正是4,將這4個數據頁的row_count數加起來也可以驗證其總數據行=1000。
在上例中,如果不清空數據緩沖區,再執行一遍SQL,可以看到內存毫無變化,而邏輯讀也不變,只是物理讀變為0,因為已經不需要再從磁盤讀入數據。
1.2 執行高選擇性選取
另外,在沒有索引的情況下,如果將上例修改為:
Select Top 1 * From P_Order 或者Select * From P_Order Where MobileNo=28502
可以看到,系統同樣要讀取全部的數據頁到內存。
如果使用Select Top 1 * From P_Order Where MobileNo=28502這樣的選取方式,有可能會出現只讀取部分數據頁到內存的情況。但由於在沒有索引情況下,數據實際上是無序存放在堆上,所以結果很不穩定,也有可能發生讀取所有的數據頁到內存。
測試2:建立聚集索引情況下,執行SQL語句2.1 執行全表選取或者低選擇性選取
修改表結構,在MobileNo字段上建立聚集索引。然後再次執行剛才的SQL語句。得到的執行計劃變為聚集索引掃描。IO統計消息為:
(1000 row(s) affected)
表'P_User'。掃描計數1,邏輯讀取6 次,物理讀取1 次,預讀4 次,lob 邏輯讀取0 次,lob 物理讀取0 次,lob 預讀0 次。
這裡的邏輯讀取變為6次。
內存情況如下:

內存中的變化是增加了一個非葉級的聚集索引頁,而葉級的聚集索引則會和數據放在一起。
另外,可以查看該表索引的級別:
SELECT database_id,object_id,index_id,index_level,page_count,record_count
FROM sys.dm_db_index_physical_stats
(DB_ID(N'TestGDB'), OBJECT_ID(N'dbo.P_User'), NULL, NULL , 'DETAILED');
從結果可以看到該表的聚集索引總共分2級。

因而邏輯讀增加了2——(由於發生Clustered Index Scan,除了根級別的聚集索引頁占用1次外,從根級別聚集索引定位到葉級別的聚集索引也將額外占用1次邏輯讀)。
另外一個變化是只發生了一次物理讀,即讀取根級別的聚集索引頁,另外4個數據頁則通過預讀方式而不是物理讀從磁盤裝入內存Buffer。這使得有聚集索引的情況下,執行SQL所直接花費的代價實際上更小。
2.2 執行高選擇性選取
在建立聚集索引情況下,對性能有益的變化是:
對於Select Top 1 * From P_Order 或者Select * From P_Order Where MobileNo=28702這樣的語句,在有聚集索引情況下,只會將最終記錄所在的頁讀入內存。
測試3:建立非聚集索引情況下,執行SQL語句3.1 執行全表選取或者低選擇性選取
如果將表中同一字段的聚集索引換成非聚集索引,則可以看到如下特點:
執行全表掃描將和沒有任何索引的情況相似,將讀取所有的數據頁到內存。此時,SQL Server的查詢引擎實際上無法使用非聚集索引。
3.2 執行高選擇性選取
將只讀取最終數據所在的頁到內存。通過查詢計劃可以看到,SQL Server在非聚集索引上使用INDEX SEEK,然後通過lookup 得到數據實際所在行(索引覆蓋情況下例外,因為不需要定位到實際數據行)。
測試4:執行Nested Loop Join
在進行測試前,我們先准備另外一張表和數據。
Create Table P_Order
( UserStatus int NOT NULL,
MobileNo int NOT NULL,
Sid int Not NULL,
LastSubTime DateTime
)
插入數據:
Declare @i int
Set @i=20000
WHILE @i<30000
BEGIN
Insert Into P_Order
Select @i % 2,@i,@i-19999,GetUTCDate()
set @i=@i+1
END
可以看到,在執行全表掃描情況下,該表10000條數據總共占用38個內存數據頁。
4.1 執行全表選取或者低選擇性選取
Select * From P_Order A
Inner Loop JOIN P_User B ON A.MobileNo=B.MobileNo
對於此種高選擇性選擇,默認情況下SQL Server不會執行Loop Join。因此,使用了強制性的聯接提示。
在兩個表都沒有任何索引的情況下,可以看到:
兩個表所有的數據頁都將被加載到內存。邏輯讀取代價高達6萬多次——對於P_Order表中的每一條記錄,都將在P_User表中進行遍歷。
在其中一個表有聚集索引情況下,盡管邏輯讀取相比剛才的6萬多次已經大大下降,但仍然達到2萬次。而且聯接的次序對查詢性能影響很大。因為其實際執行的是將SQL語句中前面的表作為聯接的外部輸入,而後面的表作為聯接的內部輸入。
在兩個表都有聚集索引情況下,相比較而言,邏輯讀仍然達到數千次(取決於最終輸出的數據大小),但相比較已經大大改善。而且表中的數據只有最終需要輸出的部分才會被讀入內存Buffer中。
4.2 執行高選擇性選取
執行如下的SQL語句:
Select * From P_Order A
Inner merge JOIN P_User B ON A.MobileNo=B.MobileNo
Where A.MobileNo=28913
在兩個表都沒有任何索引情況下,兩張表都將執行全表掃描。要讀入所有的數據頁到內存。總體邏輯讀取決於兩表的數據頁數。
在一個表有聚集索引或者非聚集索引情況下,該表將執行Index Seek,另一個表將出現全表掃描。內存數據緩沖區中,將有一張表只讀入最終數據所在的數據頁、一張表讀入全部數據頁。邏輯讀數取決於表在聯接中的秩序、以及無索引表的數據頁數。
在兩個表都有聚集索引情況下,邏輯讀最小,每個表只有2到3次。而且只有實際需要輸出的數據才會被讀入內存頁。兩個表都有非聚集索引情況下,消耗的邏輯讀和內存資源近似。
測試5:執行Merge Join5.1 執行全表選取或者低選擇性選取
執行SQL:
Select * From P_Order A
Inner merge JOIN P_User B ON A.MobileNo=B.MobileNo
如果兩張表都沒有任何索引,則兩張表都要進行全表掃描。所有的數據都要讀入內存頁。
邏輯讀數近似等於兩張表的數據頁總和。SQL Server處理過程中將使用到臨時表。
只有一張表有聚集索引的情形類似,SQL Server處理過程中將使用到臨時表。並且讀入所有的數據頁到內存。
如果兩張表都有聚集索引,盡管兩表的數據都會被讀入內存頁,但邏輯讀數已經大大減少,等於其中一張表總數據內存頁數加上最終輸出的數據頁數。而且SQL Server處理過程中將不需要再使用臨時表。
5.2 執行高選擇性選取
對於這樣的高選擇性SQL語句,SQL Server 將提示無法生成執行計劃。
Select * From P_Order A
Inner merge JOIN P_User B ON A.MobileNo=B.MobileNo
Where A.MobileNo=28913
但可以執行:
Select * From P_Order A
Inner merge JOIN P_User B ON A.MobileNo=B.MobileNo
Where A.MobileNo<=28001 (注:最終結果只有2條)
這樣的屬於低選擇性語句,但最終結果也很少的語句。如前面所述,這種情況下,采用netsted loop聯接效率可能更高。
測試6:執行Hash Join6.1 執行全表選取或者低選擇性選取
對於兩表聯接,如果兩張表都沒有索引,不寫明聯接提示的情況下,SQL Server默認使用hash join。而對於兩表聯接,如果兩張表都有聚集索引,則SQL Server默認使用Merge Join。
執行SQL:
Select * From P_Order A
Inner hash JOIN P_User B ON A.MobileNo=B.MobileNo
在使用hash join情況下,無論兩張表有無索引,都將讀取所有的數據頁到內存,SQL Server將使用臨時表進行處理。邏輯讀數近似等於兩張表的數據頁總和。
6.2 執行高選擇性選取
和merge join執行高選擇性選取情況類似,也無法直接執行:
Select * From P_Order A
Inner merge JOIN P_User B ON A.MobileNo=B.MobileNo
Where A.MobileNo=28913
但可以執行這樣的結果很少的低選擇性腳本:
Select * From P_Order A
Inner merge JOIN P_User B ON A.MobileNo=B.MobileNo
Where A.MobileNo<=28001 (注:最終結果只有2條)
但此情況下,采用netsted loop聯接效率更高。
測試總結
本次測試的主要意義在於,通過分析具體的內存變化結合執行計劃、IO讀取等信息,可以更清楚地了解SQL Server執行SQL 語句過程。
另外,也驗證了一些通過分析SQL 語句的IO讀取、執行計劃曾經得到的經驗:
(1) 在執行單表查詢時,如果是高選擇查詢,要建立非聚集索引或者聚集索引(推薦非聚集索引,是獨立於數據存放的)。如果是低選擇性查詢,則需要建立聚集索引。
(2) 在執行聯接查詢時,如果最終輸出結果很少,則適宜使用nested loop join;如果輸出結果較多,則通過建立聚集索引,而以merge join方式查詢能得到好的性能。對於性能較低的hash join,最好通過轉換成merge join或者nested loop join方式提高查詢性能。