由於數據庫存儲的數據都是以平面方式存儲,所以目前大部分論壇和其他程序都是用遞歸來展現層次數據的,如果分類的層次十分深的話那麼使用的遞歸次數相當可觀,對性能的影響也非常大。最近要做一個分類信息的平台就遇到這個問題了,那麼如何實現快速的展現分層數據呢?MySQL 的開發者幫我們想到了一個算法,這個算法目前唯一的問題就是尚未實現分類排序,我們可以通過右值的反向排序實現先入先出的排序。在這裡我們需要了解的是如何用 SQL Server 來實現,我們就以省市縣數據庫為例來實現:
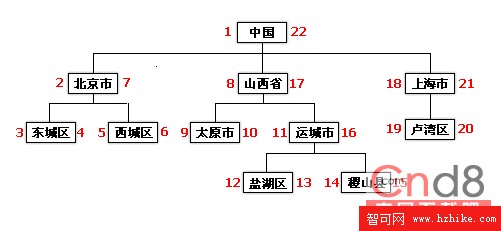
如圖所示我們將一個樹節點的左右各編上號碼,就可以看出一些規律,山西的左右值為(8,17),那麼所有左值大於8,右值小於17的節點都是屬於山西的子節點。稷山先的左右值為(14,15),那麼他的所有父節點就是左值小於14,右值大於15的節點,怎麼樣,用這個方法實現的無限級分類性能絕對是頂呱呱的。一次查詢就可以查出屬於某個節點的數據以及他子節點的數據。這個算是我見過性能最高的無限級分類算法。其他算法跟這個對比基本沒有任何優勢。
我們先建立一個數據表,結構如下圖(LID 為左值,RID 為右值,Tree 為節點深度,Name 和 ID 就不多說了,節點的索引和名稱)
我們可以使用下面的存儲過程來獲得一個節點和其子節點:

CREATE PROCEDURE CLSP_ZoneSelect ( @Root INT, @Tree INT ) AS SELECT Z.ID,Z.Tree,Z.Name FROM CL_ZoneData AS Z,CL_ZoneData AS P WHERE P.ID = @Root AND Z.LID >= P.LID AND Z.RID <= P.RID AND (@Tree = 0 OR Z.Tree <= P.Tree + @Tree) ORDER BY Z.LID ASC GO 我們可以用下面這個存儲過程來在一個節點下插入新的子節點:
CREATE PROCEDURE CLSP_ZoneInsert ( @Root INT, @Name NVARCHAR(50) ) AS DECLARE @RID AS INT,@NID AS INT,@Tree AS INT SET @RID = 1 SET @NID = 0 SET @Tree = 1 IF @Root = 0 BEGIN SELECT TOP 1 @RID = RID + 1 FROM CL_CateData ORDER BY RID DESC END ELSE BEGIN SELECT @RID = RID, @Tree = Tree + 1 FROM CL_ZoneData WHERE ID = @Root END IF @Root = 0 OR @RID > 1 BEGIN UPDATE CL_ZoneData SET RID = RID + 2 WHERE RID >= @RID UPDATE CL_ZoneData SET LID = LID + 2 WHERE LID > @RID INSERT INTO CL_ZoneData(LID,RID,Tree,Name) VALUES (@RID,@RID + 1,@Tree,@Name) SET @NID = SCOPE_IDENTITY() END SELECT @NID GO 刪除一個節點可以用下面的存儲過程:
CREATE PROCEDURE CLSP_ZoneDelete ( @ID INT ) AS DECLARE @LID AS INT, @RID AS INT, @WID AS INT, @DID AS INT SET @DID = 0 SELECT @DID = ID, @LID = LID, @RID = RID, @WID = RID - LID + 1 FROM CL_ZoneData WHERE ID = @ID IF @DID != 0 BEGIN DELETE FROM CL_ZoneData WHERE LID BETWEEN @LID AND @RID UPDATE CL_ZoneData SET RID = RID - @WID WHERE RID > @RID UPDATE CL_ZoneData SET LID = LID - @WID WHERE LID > @RID END SELECT @DID GO