1:使用分區表來提高數據庫性能
以前的處理大數據量時很多人會采取使用多個結構相同的表按時間段來分,不同時間的數據存在不同的數據表裡,這樣如果只查詢一個表的數據就很快,如果需要跨表查詢則再通過連接視圖將這些表連起來偽裝成一個表的樣子,這樣可以提高查詢效率,但犧牲了程序設計的優雅性和數據庫設計的簡單性,特別是在處理關系、約束、數據完整性時會非常的繁瑣復雜。
升級到sql2005可以采用分區表(partition table)來處理這種需求,我們可以將我們的分區規則寫成分區函數,然後我們的分區表就可以按照這個分區函數來將我們的表存儲在不同的存儲介質上,當我們查詢時SQL Server最優化程序會自動選擇分區做Join這樣當然要比大數量過濾起來有效的多。
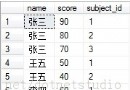
2:通過Row_Number來給查詢結果集加個序號
查詢結果集沒有序號郁悶的問題相信折騰了不少人,每每有客戶指著我的Grid OR Report對我說“小莫,你能不能給這個地方加個序號?”對於這樣的合理要求只能說是,然後就將查詢來的結果手動的加個序號,對犧牲的性能也只好燒把高香祝福它能升上天堂,然後就是保佑著客戶查詢數據量不要太大。
升級到SQL2005 我可以將序號這個功能默認給用戶不要他再給我提這樣的合理要求了。
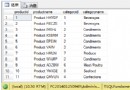
3:交叉表惡夢的結束
如果你做過考勤管理,選擇建31個列還是添加31行?選擇31列直觀,但你查詢的時候你也許更喜歡你頭撞牆而不是來查詢,添加31行當你決定用列顯示日期的時候你發現你還是願意撞牆。還有當你做類似學生成績管理系統的時候你要將課程表中的課程數據做列學生表中的學生作行的時候這個時候你突然醒悟還是撞牆好些。
升級到SQL Server2005你可以用Pivot這個單詞的意思就是“樞軸”有了軸你可以將行扭成列還可將列扭成行(UNPivot)