索引定義 : 微軟的SQL Server提供了兩種索引:聚集索引(clustered index,也稱聚類索引、簇集索引)和非聚集索引(nonclustered index,也稱非聚類索引、非簇集索引)。
SARG的定義:用於限制搜索的一個操作,因為它通常是指一個特定的匹配,一個值得范圍內的匹配或者兩個以上條件的AND連接。形式如下: 列名 操作符 <常數 或 變量>或<常數 或 變量> 操作符列名列名可以出現在操作符的一邊,而常數或變量出現在操作符的另一邊。
SARG的意義:如果一個階段可以被用作一個掃描參數(SARG),那麼就稱之為可優化的,並且可以利用索引快速獲得所需數據。
討論問題:現在有些觀點直接說in不符合SARG標准,故在查詢中全產生全表掃描.
我的觀點:這個觀點在早期的數據庫中可能是這樣,起碼SQL2005足以證明上面的說法是錯誤的.
案例:有一會員表(member),裡面包含代理信息,其中代理號proxyID上創建有索引.數量量在百萬以上。
需求:查詢指定代理的代理信息.
查詢SQL:
方法1: select 相關字段 from member where proxyID IN('ID1','ID2',.....)
方法2: select 相關字段 from member where proxyID='ID1'
union all
select 相關字段 from member where proxyID='ID1'
union all
...
如何比較:
第一:proxyID的數量比較多,我測試時輸入了30個proxyID
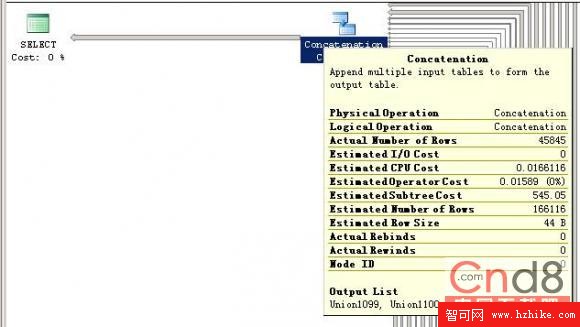
下面是兩種方法的執行計劃圖:
1:union all的執行計劃圖:由於圖比較長,所有分成兩部分顯示.
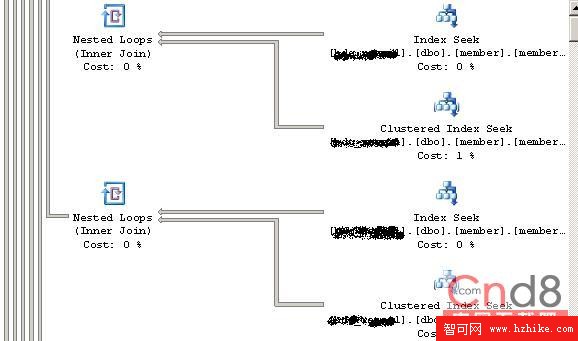
2:in的執行計劃圖:

結論:
1:無論哪種方法,都會用上索引.
2:兩都的執行計劃不同:當proxyID的數量比較多時,用in會直接查找索引,並有過濾的操作.union all則是連接了 n 個嵌套查詢.
3:代理號比較多時,union all的效率明顯高於in
第二:proxyID的數量比較小,現在分別輸入兩個,6個,15個,執行計劃圖可以看出,當proxyID的數量為15時,直接查找索引,而2個和6個時都選擇嵌套查詢來完成.因為union all的執行計劃圖總是一樣的,所有貼於不同proxyID下,用in查詢的執行計劃圖:
1:兩個代理的執行計劃圖:
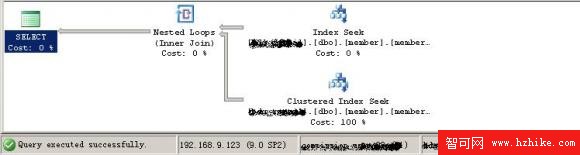
2:六個代理的執行計劃圖:
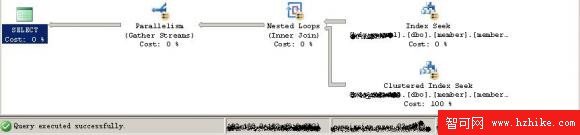
3:十五個代理的執行計劃圖:

結論:
1:無論哪種方法,都會用上索引.
2:proxyID的數據量比較小的時候在執行時間上和union all差距不大.
3:in裡面的數據個數不同時,執行計劃也會相應的同,數據量小時會采用嵌套查詢,反之則直接查詢索引以及其它相關輔助操作.
結論:現在的數據庫引擎一般都會通過查詢成本分析來選擇最優的查詢算法來執行,不能把以前的觀點拿到現在說.in與union all的差別並不是永遠不變的,看什麼情況而定.類似in的還有or,對於or,有觀點也說不能應用索引,其實和in一樣,高版本中的都會用上索引.