隨著SQLSERVER不斷的學習,認識的深入,我們會發現越來越多的功能呈現在我們面前,這些功能都是十分強大的,在我們應用中發揮著十分有意義的作用,也因此感知作為一個大型的數據庫管理系統的魅力所在。從這一篇開始,我們著手討論“存儲過程“,”觸發器“,”游標“,”事務“和”鎖“的應用,如果熟練的掌握了這些,我想駕馭SQLSERVER的能力將是一個新的層次。學習是為了應用,掌握就是為了解決問題。希望通過我們一起的學習,我們都可以很好的利用這個工具為我們服務。這是我們學習的目的也是我們的奮斗目標。好,我們繼續吧!
說起存儲過程,我們先了解他的概念,這是我們討論必走的第一步:存儲過程就是將所需要的工作,預先以SQL程序寫好,命名後進行保存,以後需要作這些工作時可以使用EXECUTE指令來調用,即可自動完成相應任務。這裡的存儲過程也是自動化的一個方面,總之就是為了方便管理的一種措施。讓我來說說他的優點吧:
1.執行效率高(這點不容置疑)
2.統一的操作流程:也就是通過存儲過程的操作避免了一些操作過程中可能無意中認為的錯誤,只要確定了制作存儲過程時是正確地,以後在調用過程中就不用擔心了。大家使用時流程是一樣的。
3.重復使用
4.安全性:這一點我們在數據庫的安全策略裡討論過,可以參考前邊的文章。也就是說:我們可以利用存儲過程作為數據存儲的管道。可以讓客戶在一定的范圍內對數據進行操作。另外,存儲過程是可以加密的,這樣別人就看不到他的內容了。
存儲過程分為三類:
系統存儲過程(System stored Procedure)sp_開頭,為SQLSERVER內置存儲過程:
擴展存儲過程(Extended stored Procedure),也就是外掛程序,用於擴展SQLSERVER的功能,以sp_或者xp_開頭,以DLL的形式單獨存在。
Δ(觀察上面的你會發現系統存儲過程和擴展存儲過程都是在master數據庫中。sp_開頭的可是全局的,任何一個數據庫都可以直接調用的。)
用戶定義的存儲過程(User-defined stored Procedure),這個就是用戶在具體的數據庫中自己定義的,名字最好不要以sp_和xp_開頭,防止混亂。
了解了基本概念,就到應用的階段了。
首先創建一個存儲過程(在pubs數據庫中),我們命名為MyProce示例代碼如下(功能為向stores表中插入stor_id,stor_name兩個字段值):
create procedure MyProce
@param1 char(4), @param2 varchar(40) --定義參數,作為存儲過程的接口
with encryption --存儲過程加密
as insert stores (stor_id,stor_name) values(@param1,@param2)
我們如此調用:
exec MyProce ‘111111’,’Leijun’book’ --參數賦值,調用存儲過程
用企業管理器創建如圖所示:
如果我們要修改,可以查看相應的存儲過程的“屬性“,如上圖在”文本“窗體中修改。
但是注意我們這個因為用了with encryption語句,所以,打開時將有下面的提示,不允許查看,這也就是加密。
看了上面的是不是有所了解了,其實創建時還有其他的參數可以使用,我們這裡只是一個簡單的例子,更多的應用需要我們在實踐中不斷的總結,這樣才能更加靈活的應用。 下面我們再來看一個創建的例子(這個的作用是在authors表中查找一個人名,表中把一個名字分為兩字段存儲了,如果查到了,打印“查有此人ID:”及其au_id字段值):
CREATE procedure SearchMe
@param1 varchar(10),@param2 varchar(30)
select @param2=au_id
from authors
where au_fname+au_lname=@param1
if @@rowcount>0 --全局變量,記錄影響到的行
print'查有此人ID:'+@param2
我們這樣執行:Exec SearchMe ‘leijun’,null
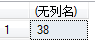
由於查找到了所以顯示如下:
例子就簡單列舉這些,因為他的靈活性很大,所以我們只簡單的說明一下,如果要更好的利用,這就需要我們不斷的摸索了。
下面我們談談使用過程中我了解到的注意事項:
1.在存儲過程中,有些建立對象的語句是不可使用的:create default,create trigger,create procedure,create vIEw,create rule.
2.在同一數據庫中,不同的所有者可以建立相同名稱的對象名。例如:a.sample,b.sample,c.sample三個數據表可以同時存在。如果存儲過程中未指明對象的所有者(例如存儲過程中的語句select * from sample,這句中的sample沒有指明所有者),在執行的過程中默認的所有者查找順序是:相應的存儲過程的建立者->相應數據庫的所有者。如果這個查找過程中沒有把所有者確定下來,系統就要報錯。
(這裡我額外插一句:如果需要嚴密的數據操作,在任何操作中盡量加上所有者,例如leijun.sample)
3.在存儲過程名稱前邊添加#或者##,所建立的存儲過程則是“臨時存儲過程“(#是局部臨時存儲過程,##是全局臨時存儲過程)。
上面的都是一些容易忽略的,特別是第二條,我們一定的認真思考,也許這些有意無意的忽略是我們造成錯誤的根源!