 Sql Server性能優化——Compression
Sql Server性能優化——Compression
執行SQL查詢時,主要的幾個瓶頸在於:CPU運算速度、內存緩存區大小、磁盤IO速度。而對於大數據量數據的查詢,其瓶頸則一般集中於磁盤IO,以及內存緩存。那
 Sql Server 2005/2008 SqlCacheDependency查詢通知的使用總結
Sql Server 2005/2008 SqlCacheDependency查詢通知的使用總結
SQL Server 7.0/2000下 SqlCacheDependency使用輪詢的方式進行緩存失效檢查, 雖然ms說對服務器壓力不大, 但還是有一些
 100萬條數據導入SQL SERVER數據庫僅用4秒
100萬條數據導入SQL SERVER數據庫僅用4秒
實際工作中有時候需要把大量數據導入數據庫,然後用於各種程序計算,本實驗將使用5中方法完成這個過程,並詳細記錄各種方法所耗費的時間。 本實驗中所用到工具為
SQLServer2005中的uniqueidentifier數據類型與NEWID()函數
uniqueidentifIEr中文含義“唯一的標識符”。 uniqueidentifIEr數據類型是16個字節的二進制值,應具有唯一性,必須與NEWI
SqlServer性能優化:Partition(管理分區)
正如上一篇文章SqlServer性能優化——Partition(創建分區)中所述,分區並不是一個一勞永逸的操作,對一張表做好分區僅僅是開始,接下來可能需
數據挖掘算法-Apriori Algorithm(關聯規則)
本人剛開始學數據挖掘,雖然之前看過一本《數據挖掘原理與應用:SQL Server 2005數據庫》,但是只是大體上了解了一些數據挖掘的概念,並沒有深入去了
 sql server 2008手工修改表結構,表不能保存的問題與解決
sql server 2008手工修改表結構,表不能保存的問題與解決
今天晚上休息,寫一個小程序,用的是SQL Server 2008,手工建立了一些表,然後我回頭想到了表字段中有一些需要增加一列,回頭我就插入一列,結果我保
 SQL Server數據庫附加後只讀或失敗解決方法及代碼實現
SQL Server數據庫附加後只讀或失敗解決方法及代碼實現
相信用過SQL Server的朋友都會有這種經歷,當我們在附加SQL Server數據庫的時候,會出現附加失敗,或附加成功後數據庫是只讀的。 受此影響
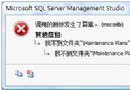 誤刪除SSIS中的Maintenance Plans文件夾的恢復收藏
誤刪除SSIS中的Maintenance Plans文件夾的恢復收藏
在SQL Server 2005/2008中,維護計劃的功能通過SSIS包來完成。如果不小心在SSIS管理中刪除了Maintenance Plans文件
甩掉數據字典,讓 Sql Server數據庫也來一個自描述
我們學、用 .Net的都知道,程序集 (Assembly)的一個很大的優點就是它有元數據,可以 “自描述 ”。在我們體驗這種優勢的同時,我們是否想過什麼時