基礎准備: 用隨機數生成表。 IF NULLIF(OBJECT_ID(measurements),0)>0 DROP TABLE measurement
有一表: col1 value running_tot 1 10 0 (10) 2 15 0 (25) 3 50 0 (75) …… 若要將value列累積
用於數據擦除的相關方法 CREATE TABLE #match_cols ( row_num int, col2 char(1), col3 char(1)
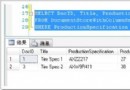
關於distinct id的取法 型如表:t_test -------------------------------------- id(int) cost
(1)、獲取表中記錄的總行數 SELECT COUNT(*) FROM seq_num --更快的方法,只能取得表的總行數 SELECT ROWS FROM
查找含匹配列的行 //--為col2與col3查找出重復的行 //match_cols表 row_no col2 col3 ------ ----------
@@CONNECTIONS 返回自上次啟動 Microsoft® SQL Server™ 以來連接或試圖連接的次數。 語法 @@CONN
Version: SQL Server 7.0/2000 Created by: Alexander Chigrik (SQL Server Articles
這是兩個新增的特性。 我的總結如下 1. 稀疏列主要是為了提供對可空字段的更好一個存儲機制,它可以節省空間(具體說它在真正空值的時候就不占空間),但也
Merge語法是對插入,更新,刪除這三個操作的合並。根據與源表聯接的結果,對目標表執行插入、更新或刪除操作。例如,根據在另一個表中找到的差異在一個表中插
在創建表或索引或當在改變一個索引或表時可以激活行壓縮。 壓縮可以是在行級別、頁面級別和備份級別。在這篇文章中,我們將介紹怎樣創建一個使用行壓縮的表,並
一、SQLServer與Analysis Services排序規則的差異。 通常情況下數據庫管理員可以分別為數據庫引擎和Analysis Servi
前言 類似的軟件很多年前寫過,不過現在在新國家,新環境,印度佬(我囧)資深系統分析員要求我:給現有的數據庫的所有存儲過程分別列舉所有依賴的對象。
/*本次修改增加了unicode的支持,但是加密後依然顯示為16進制數據,因為進行RSA加密後所得到的unicode編碼是無法顯示的,所以密文依然采用1
BuildQuery類是能快速,容易地構建一個復雜的INSERT或者UPDATE 的SQL查詢語句。這個類將接收的一些參數,輸出有效的SQL語句。它有一個
復合索引(where A And B)如果沒有對A和B做單一索引,查詢的時間為a;如果對A做單一索引,查詢時間為b;如果對B做單一索引,查詢時間為c;如
將本文收藏到: | 收藏到本地 | 復制本文地址 查詢的時候應該盡量按照復合索引中的順序來做條件查詢;(比如IXC中spInterActiveInstanc
游標 盡量少用游標,如果不得不用,那就要看是否可以對邏輯進行整合,分出不同的情況,讓在一部分情況是使用insert select的方式來一次性插入;(
如果某表經常出現死鎖,那就要做對象職責分離,就是把插入、更新、刪除等分離; 在設計或創建表的時候,我們往往會把 Id字段設置為聚集索引,但是我們這樣的
性能調優 測試基線 測試用例,測試場景 聚集索引、非聚集索引 索引覆蓋 復合索引、組合索引、單一索引、哈希索引 高選擇性 計
 SQL Server 2008 T-SQL之Merge語法
合理設置SQL Server 2008服務器安裝向導
SQL Server 2008 T-SQL之Merge語法
合理設置SQL Server 2008服務器安裝向導