1,概念: 數據庫索引是對數據表中一個或多個列的值進行排序的結構,就像一本書的目錄一樣,索引提供了在行中快速查詢特定行的能力.
2,優缺點:
2.1優點: 1,大大加快搜索數據的速度,這是引入索引的主要原因.
2,創建唯一性索引,保證數據庫表中每一行數據的唯一性.
3,加速表與表之間的連接,特別是在實現數據的參考完整性方面特別有意義.
4,在使用分組和排序子句進行數據檢索時,同樣可以減少其使用時間.
2,2缺點: 1,索引需要占用物理空間,聚集索引占的空間更大.
2,創建索引和維護索引需要耗費時間,這種時間會隨著數據量的增加而增加.
3,當向一個包含索引的列的數據表中添加或者修改記錄時,SQL server 會修改和維護相應的索引,這樣增加系統的額外開銷,降低處理速度。
3,索引的分類:
1,按存儲結構可分為:
a,聚集索引:指物理存儲順序與索引順序完全相同,它由上下兩層組成,上層為索引頁,下層為數據頁,只有一種排序方式,因此每個表中只能創建一個聚集索引。
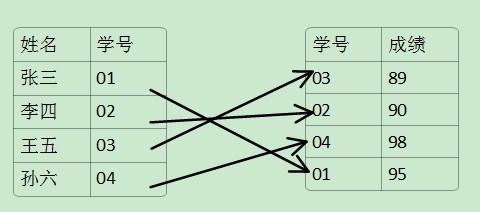
b,非聚集索引:指存儲的數據順序一般和表的物理數據的存儲結構不同。通過下表我們可以分析出:(其中在學號上建立非聚集索引)
1,創建:(1),原則:a,只有表的所有者可以在同一個表中創建索引;
b,每個表中只可以創建一個聚集索引;
c,每個表中最多可以創建249個非聚集索引;
d,在經常查詢的字段上建立索引;
e,定義text,image和bit數據類型的裂傷不能創建索引;
f,在外鍵列上可以創建索引,主鍵上一定要有索引;
g,在那些重復值比較多的,查詢較少的列上不要建立索引。
(2),方法:a,使用SQL server Management Studio創建索引。
b,使用T-SQL語句中的create Index語句創建索引
c,使用Create table或者alter Table語句為表列定義主鍵約束或者唯一性約束時,會自動創建主鍵索引和惟一索引。
這裡說說T-sql語句創建索引:
語法:
復制代碼 代碼如下:create relational index create[unique][clustered|nonclustered] index index_name on<object>(cloumn[asc|desc][,……n]) [include (column_name[,……n])] [with(<relational_index_option>[,……n])] [onfilegroup_name]說明:1,include (column_name[,……n])指定要添加到非聚集索引的葉級別的非鍵列。
2,on filegroup_name,為指定文件組創建指定索引。
例如:在course表中,對“課程代號”列創建聚集索引zindex.
復制代碼 代碼如下:use db_student create clustered index zindex on course(課程代號)2,查看索引:(1),使用SQL ServerManagement Studio查看索引信息
(2),使用系統存儲過程查詢索引信息,用SP_helpindex可以返回表中的所有索引信息
例如:查看course表的索引信息
use db_student execsp_helpindex course[/code]
3,修改索引:(1),在SQL Server Management Studio 中修改索引
(2),使用Alter Index語句修改索引
在這裡為大家舉一個例子:
在course數據表中,修改所有的索引,並指定選項
復制代碼 代碼如下:use db_student alterindex all on course rebuild with (fillfactor=80,sort_in_tempdb=on,statistics_norecompute=on)
4,刪除索引:(1),使用SQL Server Management Studio 刪除索引
(2),使用Drop index語句刪除索引
例如:在course表中,刪除zindex索引
復制代碼 代碼如下:use db_student drop index course.zindex三,索引的分析和維護:
分析:1,使用showplan 語句
語法:set showplan_all{on|off},set showplan_next{on|off}
例子:顯示表course的課程代號,課程類型,課程內容,並顯示查詢過程
復制代碼 代碼如下:use db_student set showplan_all on select 課程代號,課程類型 課程內容 from course where 課程內容='loving'
2,使用statistics io語句語法:statistics io{on|off} on和off分別為顯示和不顯示,使用方法和上一樣。
維護: 1,使用dbcc showcontig語句,顯示指定表的數據和索引的碎片信息。當對表中進行大量修改或添加數據後,應該執行此語句查看有無碎片。
語法:dbcc showcontig[{table_name|table_id|view_name|view_id},index_name|index_id] with fast
2,使用dbcc dbreindex語句,意思是重建數據庫中表的一個或多個索引。
語法:
復制代碼 代碼如下:dbcc dbreindex (['database.owner.table_name'[,index_name[,fillfactor]]]) [withno_infomsgs]說明: database.owner.table_name,重新建立索引的表名
index_name,是要重建的索引名
fillfactor,要創建索引時每個索引頁上要用於存儲數據的空間百分比。
with no_infomsgs,禁止顯示所有信息性消息
3,使用dbcc indexdefrag,整理指定的表或視圖的聚集索引和輔助索引碎片。
語法:
復制代碼 代碼如下:dbcc indexdefrag ({database_name|database_id|0},{table_name|table_id|'view_name'|view_id},{index_name|index_id}) with no_infomsgs
總結,只有我們對索引有了充分了熟悉;我們掌握了索引的增刪改查四項基本操作,學會利用SQL Server ManagerSdudio去實現這些功能,和學會利用T-SQL語句去實現(自我感覺利用SQL Server Manager Sdudio 簡單一些);當然還要懂得學會分析和維護索引,這樣才會更好的讓它為咱們服務!