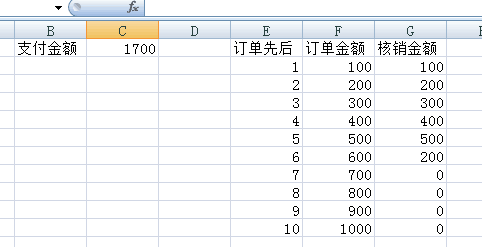
行列互轉
復制代碼 代碼如下:
create table test(id int,name varchar(20),quarter int,profile int)
insert into test values(1,'a',1,1000)
insert into test values(1,'a',2,2000)
insert into test values(1,'a',3,4000)
insert into test values(1,'a',4,5000)
insert into test values(2,'b',1,3000)
insert into test values(2,'b',2,3500)
insert into test values(2,'b',3,4200)
insert into test values(2,'b',4,5500)
select * from test
--行轉列
select id,name,
[1] as "一季度",
[2] as "二季度",
[3] as "三季度",
[4] as "四季度",
[5] as "5"
from
test
pivot
(
sum(profile)
for quarter in
([1],[2],[3],[4],[5])
)
as pvt
create table test2(id int,name varchar(20), Q1 int, Q2 int, Q3 int, Q4 int)
insert into test2 values(1,'a',1000,2000,4000,5000)
insert into test2 values(2,'b',3000,3500,4200,5500)
select * from test2
--列轉行
select id,name,quarter,profile
from
test2
unpivot
(
profile
for quarter in
([Q1],[Q2],[Q3],[Q4])
)
as unpvt
sql替換字符串 substring replace
復制代碼 代碼如下:
--例子1:
update tbPersonalInfo set TrueName = replace(TrueName,substring(TrueName,2,4),'**') where ID = 1
--例子2:
update tbPersonalInfo set Mobile = replace(Mobile,substring(Mobile,4,11),'********') where ID = 1
--例子3:
update tbPersonalInfo set Email = replace(Email,'chinamobile','******') where ID = 1
SQL查詢一個表內相同紀錄 having
如果一個ID可以區分的話,可以這麼寫
復制代碼 代碼如下:
select * from 表 where ID in (
select ID from 表 group by ID having sum(1)>1))
如果幾個ID才能區分的話,可以這麼寫
復制代碼 代碼如下:
select * from 表 where ID1+ID2+ID3 in
(select ID1+ID2+ID3 from 表 group by ID1,ID2,ID3 having sum(1)>1))
其他回答:數據表是zy_bho,想找出ZYH字段名相同的記錄
復制代碼 代碼如下:
--方法1:
SELECT *FROM zy_bho a WHERE EXISTS
(SELECT 1 FROM zy_bho WHERE [PK] <> a.[PK] AND ZYH = a.ZYH)
--方法2:
select a.* from zy_bho a join zy_bho b
on (a.[pk]<>b.[pk] and a.zyh=b.zyh)
--方法3:
select * from zy_bbo where zyh in
(select zyh from zy_bbo group by zyh having count(zyh)>1)
--其中pk是主鍵或是 unique的字段。
把多行SQL數據變成一條多列數據,即新增列
復制代碼 代碼如下:
Select
DeptName=O.OUName,
'9G'=Sum(Case When PersonalGrade=9 Then 1 Else 0 End),
'8G'=Sum(Case When PersonalGrade=8 Then 1 Else 0 End),
'7G4'=Sum(Case When PersonalGrade=7 AND JobGrade =4 Then 1 Else 0 End),
'7G3'=Sum(Case When PersonalGrade=7 AND JobGrade =3 Then 1 Else 0 End),
'6G'=Sum(Case When PersonalGrade=6 Then 1 Else 0 End),
'5G3'=Sum(Case When PersonalGrade=5 AND JobGrade =3 Then 1 Else 0 End),
'5G2'=Sum(Case When PersonalGrade=5 AND JobGrade =2 Then 1 Else 0 End),
'4G'=Sum(Case When PersonalGrade=4 Then 1 Else 0 End),
'3G2'=Sum(Case When PersonalGrade=3 AND JobGrade =2 Then 1 Else 0 End),
'3G1'=Sum(Case When PersonalGrade=3 AND JobGrade =1 Then 1 Else 0 End),
'2G'=Sum(Case When PersonalGrade=2 Then 1 Else 0 End),
'1G'=Sum(Case When PersonalGrade=1 Then 1 Else 0 End),
--' 未定級'=Sum(Case When PersonalGrade=NULL Then 1 Else 0 End)
表復制
復制代碼 代碼如下:
insert into PhoneChange_Num ([IMSI],Num)
SELECT [IMSI]
,count([IMEI]) as num
FROM [Test].[dbo].[PhoneChange] group by [IMSI] order by num desc
語法1:Insert INTO table(field1,field2,...) values(value1,value2,...)
語法2:Insert into Table2(field1,field2,...) select value1,value2,... from Table1(要求目標表Table2必須存在,由於目標表Table2已經存在,所以我們除了插入源表Table1的字段外,還可以插入常量。)
語法3:SELECT vale1, value2 into Table2 from Table1(要求目標表Table2不存在,因為在插入時會自動創建表Table2,並將Table1中指定字段數據復制到Table2中。)
語法4:使用導入導出功能進行全表復制。如果是使用【編寫查詢以指定要傳輸的數據】,那麼在大數據表的復制就會有問題?因為復制到一定程度就不再動了,內存爆了?它也沒有寫入到表中。而使用上面3種語法直接執行是會馬上刷新到數據庫表中的,你刷新一下mdf文件就知道了。
利用帶關聯子查詢Update語句更新數據
復制代碼 代碼如下:
--方法1:
Update Table1 set c = (select c from Table2 where a = Table1.a) where c is null
--方法2:
update A
set newqiantity=B.qiantity
from A,B
where A.bnum=B.bnum
--方法3:
update
(select A.bnum ,A.newqiantity,B.qiantity from A left join B on A.bnum=B.bnum) AS C
set C.newqiantity = C.qiantity
where C.bnum =XX
連接遠程服務器
復制代碼 代碼如下:
--方法1:
select * from openrowset('SQLOLEDB','server=192.168.0.67;uid=sa;pwd=password','SELECT * FROM BCM2.dbo.tbAppl')
--方法2:
select * from openrowset('SQLOLEDB','192.168.0.67';'sa';'password','SELECT * FROM BCM2.dbo.tbAppl')
TRUNCATE TABLE [Table Name]
下面是對Truncate語句在MSSQLServer2000中用法和原理的說明:
Truncate是SQL中的一個刪除數據表內容的語句,用法是:
Truncate table 表名 速度快,而且效率高,因為:
TRUNCATE TABLE 在功能上與不帶 WHERE 子句的 DELETE 語句相同:二者均刪除表中的全部行。但 TRUNCATE TABLE 比 DELETE 速度快,且使用的系統和事務日志資源少。
DELETE 語句每次刪除一行,並在事務日志中為所刪除的每行記錄一項。TRUNCATE TABLE 通過釋放存儲表數據所用的數據頁來刪除數據,並且只在事務日志中記錄頁的釋放。
TRUNCATE TABLE 刪除表中的所有行,但表結構及其列、約束、索引等保持不變。新行標識所用的計數值重置為該列的種子。如果想保留標識計數值,請改用 DELETE。如果要刪除表定義及其數據,請使用 DROP TABLE 語句。
對於由 FOREIGN KEY 約束引用的表,不能使用 TRUNCATE TABLE,而應使用不帶 WHERE 子句的 DELETE 語句。由於 TRUNCATE TABLE 不記錄在日志中,所以它不能激活觸發器。
TRUNCATE TABLE 不能用於參與了索引視圖的表。
參考文獻
數據庫表行轉列,列轉行終極方案
行列互轉(動態腳本)
SELECT INTO 和 INSERT INTO SELECT 兩種表復制語句
非常有用的sql腳本
作者:聽風吹雨