1.row_number
2.rank
3.dense_rank
4.ntile
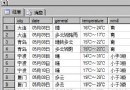
下面分別介紹一下這四個排名函數的功能及用法。在介紹之前假設有一個t_table表,表結構與表中的數據如圖1所示:
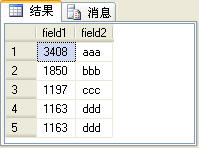
圖1
其中field1字段的類型是int,field2字段的類型是varchar
一、row_number
row_number函數的用途是非常廣泛,這個函數的功能是為查詢出來的每一行記錄生成一個序號。row_number函數的用法如下面的SQL語句所示:
select row_number() over(order by field1) as row_number,* fromt_table
上面的SQL語句的查詢結果如圖2所示。
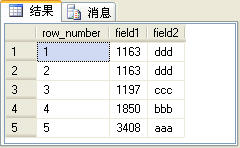
圖2
其中row_number列是由row_number函數生成的序號列。在使用row_number函數是要使用over子句選擇對某一列進行排序,然後才能生成序號。
實際上,row_number函數生成序號的基本原理是先使用over子句中的排序語句對記錄進行排序,然後按著這個順序生成序號。over子句中的order by子句與SQL語句中的order by子句沒有任何關系,這兩處的order by 可以完全不同,如下面的SQL語句所示
select row_number() over(order by field2 desc) as row_number,*from t_table order by field1 desc
上面的SQL語句的查詢結果如圖3所示。
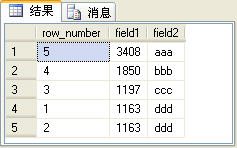
圖3
我們可以使用row_number函數來實現查詢表中指定范圍的記錄,一般將其應用到Web應用程序的分頁功能上。下面的SQL語句可以查詢t_table表中第2條和第3條記錄:
with t_rowtable
as
(
select row_number() over(order by field1) as row_number,*from t_table
)
select * from t_rowtable where row_number>1 and row_number<4 order by field1
上面的SQL語句的查詢結果如圖4所示。
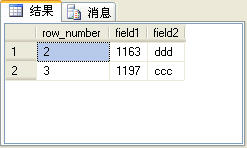
圖4
上面的SQL語句使用了CTE,關於CTE的介紹將讀者參閱《SQL Server2005雜談(1):使用公用表表達式(CTE)簡化嵌套SQL》。
另外要注意的是,如果將row_number函數用於分頁處理,over子句中的order by 與排序記錄的order by 應相同,否則生成的序號可能不是有續的。
當然,不使用row_number函數也可以實現查詢指定范圍的記錄,就是比較麻煩。一般的方法是使用顛倒Top來實現,例如,查詢t_table表中第2條和第3條記錄,可以先查出前3條記錄,然後將查詢出來的這三條記錄按倒序排序,再取前2條記錄,最後再將查出來的這2條記錄再按倒序排序,就是最終結果。SQL語句如下:
select * from(select top2 * from(select top3 * from t_table order by field1)a
order by field1 desc) b order by field1
上面的SQL語句查詢出來的結果如圖5所示。
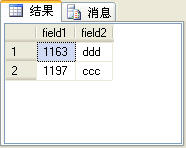
圖5
這個查詢結果除了沒有序號列row_number,其他的與圖4所示的查詢結果完全一樣。
二、rank
rank函數考慮到了over子句中排序字段值相同的情況,為了更容易說明問題,在t_table表中再加一條記錄,如圖6所示。
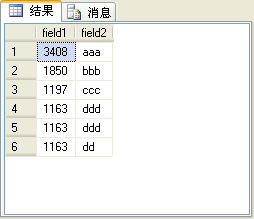
圖6
在圖6所示的記錄中後三條記錄的field1字段值是相同的。如果使用rank函數來生成序號,這3條記錄的序號是相同的,而第4條記錄會根據當前的記錄數生成序號,後面的記錄依此類推,也就是說,在這個例子中,第4條記錄的序號是4,而不是2。rank函數的使用方法與row_number函數完全相同,SQL語句如下:
select rank() over(order by field1),* from t_table order by field1
上面的SQL語句的查詢結果如圖7所示。
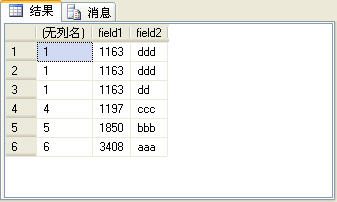
圖7
三、dense_rank
dense_rank函數的功能與rank函數類似,只是在生成序號時是連續的,而rank函數生成的序號有可能不連續。如上面的例子中如果使用dense_rank函數,第4條記錄的序號應該是2,而不是4。如下面的SQL語句所示:
select dense_rank() over(order by field1),* from t_table order by field1
上面的SQL語句的查詢結果如圖8所示。
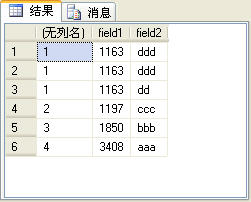
圖8
讀者可以比較圖7和圖8所示的查詢結果有什麼不同
四、ntile
ntile函數可以對序號進行分組處理。這就相當於將查詢出來的記錄集放到指定長度的數組中,每一個數組元素存放一定數量的記錄。ntile函數為每條記錄生成的序號就是這條記錄所有的數組元素的索引(從1開始)。也可以將每一個分配記錄的數組元素稱為“桶”。ntile函數有一個參數,用來指定桶數。下面的SQL語句使用ntile函數對t_table表進行了裝桶處理:
select ntile(4) over(order by field1)as bucket,* from t_table
上面的SQL語句的查詢結果如圖9所示。
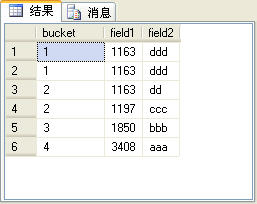
圖9
由於t_table表的記錄總數是6,而上面的SQL語句中的ntile函數指定了桶數為4。
也許有的讀者會問這麼一個問題,SQL Server2005怎麼來決定某一桶應該放多少記錄呢?可能t_table表中的記錄數有些少,那麼我們假設t_table表中有59條記錄,而桶數是5,那麼每一桶應放多少記錄呢?
實際上通過兩個約定就可以產生一個算法來決定哪一個桶應放多少記錄,這兩個約定如下:
1.編號小的桶放的記錄不能小於編號大的桶。也就是說,第1捅中的記錄數只能大於等於第2桶及以後的各桶中的記錄。
2.所有桶中的記錄要麼都相同,要麼從某一個記錄較少的桶開始後面所有捅的記錄數都與該桶的記錄數相同。也就是說,如果有個桶,前三桶的記錄數都是10,而第4捅的記錄數是6,那麼第5桶和第6桶的記錄數也必須是6。
根據上面的兩個約定,可以得出如下的算法:
//mod表示取余,div表示取整
if(記錄總數mod桶數==0)
{
recordCount=記錄總數div桶數;
將每桶的記錄數都設為recordCount
}
else
{
recordCount1=記錄總數div桶數+1;
intn=1; // n表示桶中記錄數為recordCount1的最大桶數
m=recordCount1*n;
while(((記錄總數-m) mod (桶數- n)) !=0)
{
n++;
m=recordCount1*n;
}
recordCount2=(記錄總數-m)div (桶數-n);
將前n個桶的記錄數設為recordCount1
將n+1個至後面所有桶的記錄數設為recordCount2
}
根據上面的算法,如果記錄總數為59,桶數為5,則前4個桶的記錄數都是12,最後一個桶的記錄數是11。
如果記錄總數為53,桶數為5,則前3個桶的記錄數為11,後2個桶的記錄數為10。
就拿本例來說,記錄總數為6,桶數為4,則會算出recordCount1的值為2,在結束while循環後,會算出recordCount2的值是1,因此,前2個桶的記錄是2,後2個桶的記錄是1。
ROW_NUMBER、RANK、DENSE_RANK 和 NTILE,這些新函數使您可以有效地分析數據以及向查詢的結果行提供排序值。您可能發現這些新函數有用的典型方案包括:將連續整數分配給結果行,以便進行表示、分頁、計分和繪制直方圖。
Speaker Statistics 方案
下面的 Speaker Statistics 方案將用來討論和演示不同的函數和它們的子句。大型計算會議包括三個議題:數據庫、開發和系統管理。十一位演講者在會議中發表演講,並且為他們的講話獲得 范圍為 1 到 9 的分數。結果被總結並存儲在下面的 SpeakerStats 表中:
CREATE TABLE SpeakerStats(
speaker VARCHAR(10) NOT NULL PRIMARY KEY
, track VARCHAR(10) NOT NULL
, score INT NOT NULL
, pctfilledevals INT NOT NULL
, numsessions INT NOT NULL)
SET NOCOUNT ON
INSERT INTO SpeakerStats VALUES('Dan', 'Sys', 3, 22, 4)
INSERT INTO SpeakerStats VALUES('Ron', 'Dev', 9, 30, 3)
INSERT INTO SpeakerStats VALUES('Kathy', 'Sys', 8, 27, 2)
INSERT INTO SpeakerStats VALUES('Suzanne', 'DB', 9, 30, 3)
INSERT INTO SpeakerStats VALUES('Joe', 'Dev', 6, 20, 2)
INSERT INTO SpeakerStats VALUES('Robert', 'Dev', 6, 28, 2)
INSERT INTO SpeakerStats VALUES('Mike', 'DB', 8, 20, 3)
INSERT INTO SpeakerStats VALUES('Michele', 'Sys', 8, 31, 4)
INSERT INTO SpeakerStats VALUES('Jessica', 'Dev', 9, 19, 1)
INSERT INTO SpeakerStats VALUES('Brian', 'Sys', 7, 22, 3)
INSERT INTO SpeakerStats VALUES('Kevin', 'DB', 7, 25, 4)
每個演講者都在該表中具有一個行,其中含有該演講者的名字、議題、平均得分、填寫評價的與會者相對於參加會議的與會者數量的百分比以及該演講者發表演講的次數。本節演示如何使用新的排序函數分析演講者統計數據以生成有用的信息。
ROW_NUMBER
ROW_NUMBER 函數使您可以向查詢的結果行提供連續的整數值。例如,假設您要返回所有演講者的 speaker、track 和 score,同時按照 score 降序向結果行分配從 1 開始的連續值。以下查詢通過使用 ROW_NUMBER 函數並指定 OVER (ORDER BY score DESC) 生成所需的結果:
SELECT ROW_NUMBER() OVER(ORDER BY score DESC) AS rownum, speaker, track, scoreFROM SpeakerStatsORDER BY score DESC以下為結果集:
rownum speaker track score
------ ---------- ---------- -----------
1 Jessica Dev 9
2 Ron Dev 9
3 Suzanne DB 9
4 Kathy Sys 8
5 Michele Sys 8
6 Mike DB 8
7 Kevin DB 7
8 Brian Sys 7
9 Joe Dev 6
10 Robert Dev 6
11 Dan Sys 3
得 分最高的演講者獲得行號 1,得分最低的演講者獲得行號 11。ROW_NUMBER 總是按照請求的排序為不同的行生成不同的行號。請注意,如果在 OVER() 選項中指定的 ORDER BY 列表不唯一,則結果是不確定的。這意味著該查詢具有一個以上正確的結果;在該查詢的不同調用中,可能獲得不同的結果。例如,在我們的示例中,有三個不同的 演講者獲得相同的最高得分 (9):Jessica、Ron 和 Suzanne。由於 SQL Server 必須為不同的演講者分配不同的行號,因此您應當假設分別分配給 Jessica、Ron 和 Suzanne 的值 1、2 和 3 是按任意順序分配給這些演講者的。如果值 1、2 和 3 被分別分配給 Ron、Suzanne 和 Jessica,則結果應該同樣正確。
如 果您指定一個唯一的 ORDER BY 列表,則結果總是確定的。例如,假設在演講者之間出現得分相同的情況時,您希望使用最高的 pctfilledevals 值來分出先後。如果值仍然相同,則使用最高的 numsessions 值來分出先後。最後,如果值仍然相同,則使用最低詞典順序 speaker 名字來分出先後。由於 ORDER BY 列表 — score、pctfilledevals、numsessions 和 speaker — 是唯一的,因此結果是確定的:
SELECT ROW_NUMBER() OVER(ORDER BY score DESC, pctfilledevals DESC, numsessions DESC, speaker) AS rownum, speaker, track, score, pctfilledevals, numsessionsFROM SpeakerStatsORDER BY score DESC, pctfilledevals DESC, numsessions DESC, speaker以下為結果集:
rownum speaker track score pctfilledevals numsessions
------ ---------- ---------- ----------- -------------- -----------
1 Ron Dev 9 30 3
2 Suzanne DB 9 30 3
3 Jessica Dev 9 19 1
4 Michele Sys 8 31 4
5 Kathy Sys 8 27 2
6 Mike DB 8 20 3
7 Kevin DB 7 25 4
8 Brian Sys 7 22 3
9 Robert Dev 6 28 2
10 Joe Dev 6 20 2
11 Dan Sys 3 22 4
新的排序函數的重要好處之一是它們的效率。SQL Server 的優化程序只需要掃描數據一次,以便計算值。它完成該工作的方法是:使用在排序列上放置的索引的有序掃描,或者,如果未創建適當的索引,則掃描數據一次並對其進行排序。
另一個好處是語法的簡單性。為了讓您感受一下通過使用在 SQL Server 的較低版本中采用的基於集的方法來計算排序值是多麼困難和低效,請考慮下面的 SQL Server 2000 查詢,它返回與上一個查詢相同的結果:
SELECT (SELECT COUNT(*) FROM SpeakerStats AS S2
WHERE S2.score > S1.score
OR (S2.score = S1.score AND S2.pctfilledevals > S1.pctfilledevals)
OR (S2.score = S1.score AND S2.pctfilledevals = S1.pctfilledevals AND S2.numsessions > S1.numsessions)
OR (S2.score = S1.score AND S2.pctfilledevals = S1.pctfilledevals AND S2.numsessions = S1.numsessions AND S2.speaker < S1.speaker)
) + 1 AS rownum
, speaker, track, score, pctfilledevals, numsessions
FROM SpeakerStats AS S1
ORDER BY score DESC, pctfilledevals DESC, numsessions DESC, speaker
該查詢顯然比 SQL Server 2005 查詢復雜得多。此外,對於 SpeakerStats 表中的每個基礎行,SQL Server 都必須掃描該表的另一個實例中的所有匹配行。對於基礎表中的每個行,平均大約需要掃描該表的一半(最少)行。SQL Server 2005 查詢的性能惡化是線性的,而 SQL Server 2000 查詢的性能惡化是指數性的。即使是在相當小的表中,性能差異也是顯著的。
行號的一個典型應用是通過查詢結果分頁。給定頁大小(以行數為單位)和頁號,需要返回屬於給定頁的行。例如,假設您希望按照“score DESC, speaker”順序從 SpeakerStats 表中返回第二頁的行,並且假定頁大小為三行。下面的查詢首先按照指定的排序計算派生表 D 中的行數,然後只篩選行號為 4 到 6 的行(它們屬於第二頁):
SELECT *
FROM (SELECT ROW_NUMBER() OVER(ORDER BY score DESC, speaker) AS rownum,
speaker, track, score
FROM SpeakerStats) AS D
WHERE rownum BETWEEN 4 AND 6
ORDER BY score DESC, speaker
以下為結果集:
rownum speaker track score
------ ---------- ---------- -----------
4 Kathy Sys 8
5 Michele Sys 8
6 Mike DB 8
用更一般的術語表達就是,給定 @pagenum 變量中的頁號和 @pagesize 變量中的頁大小,以下查詢返回屬於預期頁的行:
DECLARE @pagenum AS INT, @pagesize AS INT
SET @pagenum = 2
SET @pagesize = 3
SELECT * FROM (SELECT ROW_NUMBER() OVER(ORDER BY score DESC, speaker) AS rownum
,speaker
, track
, score
FROM SpeakerStats)
AS DWHERE rownum BETWEEN (@pagenum-1)*@pagesize+1 AND @pagenum*@pagesize
ORDER BY score DESC, speaker
上述方法對於您只對行的一個特定頁感興趣的特定請求而言已經足夠了。但是,當用戶發出多個請求時,該方法就不能滿足需要了,因為該查詢的每個調用都 需要您對表進行完整掃描,以便計算行號。當用戶可能反復請求不同的頁時,為了更有效地進行分頁,請首先用所有基礎表行(包括計算得到的行號)填充一個臨時 表,並且對包含這些行號的列進行索引:
SELECT ROW_NUMBER() OVER(ORDER BY score DESC, speaker) AS rownum, *
INTO #SpeakerStatsRN
FROM SpeakerStats
CREATE UNIQUE CLUSTERED INDEX idx_uc_rownum ON #SpeakerStatsRN(rownum)
然後,對於所請求的每個頁,發出以下查詢:
SELECT rownum, speaker, track, score
FROM #SpeakerStatsRN
WHERE rownum BETWEEN (@pagenum-1)*@pagesize+1 AND @pagenum*@pagesize
ORDER BY score DESC, speaker
只有屬於預期頁的行才會被掃描。
分段
可以在行組內部獨立地計算排序值,而不是為作為一個組的所有表行計算排序值。為此,請使用 PARTITION BY 子句,並且指定一個表達式列表,以標識應該為其獨立計算排序值的行組。例如,以下查詢按照“score DESC, speaker”順序單獨分配每個 track 內部的行號:
SELECT track,
ROW_NUMBER() OVER(
PARTITION BY track
ORDER BY score DESC, speaker) AS pos,
speaker, score
FROM SpeakerStats
ORDER BY track, score DESC, speaker
以下為結果集:
track pos speaker score
---------- --- ---------- -----------
DB 1 Suzanne 9
DB 2 Mike 8
DB 3 Kevin 7
Dev 1 Jessica 9
Dev 2 Ron 9
Dev 3 Joe 6
Dev 4 Robert 6
Sys 1 Kathy 8
Sys 2 Michele 8
Sys 3 Brian 7
Sys 4 Dan 3
在 PARTITION BY 子句中指定 track 列會使得為具有相同 track 的每個行組單獨計算行號。
RANK, DENSE_RANK
RANK 和 DENSE_RANK 函數非常類似於 ROW_NUMBER 函數,因為它們也按照指定的排序提供排序值,而且可以根據需要在行組(分段)內部提供。但是,與 ROW_NUMBER 不同的是,RANK 和 DENSE_RANK 向在排序列中具有相同值的行分配相同的排序。當 ORDER BY 列表不唯一,並且您不希望為在 ORDER BY 列表中具有相同值的行分配不同的排序時,RANK 和 DENSE_RANK 很有用。RANK 和 DENSE_RANK 的用途以及兩者之間的差異可以用示例進行最好的解釋。以下查詢按照 score DESC 順序計算不同演講者的行號、排序和緊密排序值:
SELECT speaker, track, score,
ROW_NUMBER() OVER(ORDER BY score DESC) AS rownum,
RANK() OVER(ORDER BY score DESC) AS rnk,
DENSE_RANK() OVER(ORDER BY score DESC) AS drnk
FROM SpeakerStats
ORDER BY score DESC
以下為結果集:
speaker track score rownum rnk drnk
---------- ---------- ----------- ------ --- ----
Jessica Dev 9 1 1 1
Ron Dev 9 2 1 1
Suzanne DB 9 3 1 1
Kathy Sys 8 4 4 2
Michele Sys 8 5 4 2
Mike DB 8 6 4 2
Kevin DB 7 7 7 3
Brian Sys 7 8 7 3
Joe Dev 6 9 9 4
Robert Dev 6 10 9 4
Dan Sys 3 11 11 5
正 如前面討論的那樣,score 列不唯一,因此不同的演講者可能具有相同的得分。行號確實代表下降的 score 順序,但是具有相同得分的演講者仍然獲得不同的行號。但是請注意,在結果中,所有具有相同得分的演講者都獲得相同的排序和緊密排序值。換句話說,當 ORDER BY 列表不唯一時,ROW_NUMBER 是不確定的,而 RANK 和 DENSE_RANK 總是確定的。排序值和緊密排序值之間的差異在於,排序代表:具有較高得分的行號加 1,而緊密排序代表:具有明顯較高得分的行號加 1。從您迄今為止已經了解的內容中,您可以推導出當 ORDER BY 列表唯一時,ROW_NUMBER、RANK 和 DENSE_RANK 產生完全相同的值。
NTILE
NTILE 使您可以按照指定的順序,將查詢的結果行分散到指定數量的組 (tile) 中。每個行組都獲得不同的號碼:第一組為 1,第二組為 2,等等。您可以在函數名稱後面的括號中指定所請求的組號,在 OVER 選項的 ORDER BY 子句中指定所請求的排序。組中的行數被計算為 total_num_rows / num_groups。如果有余數 n,則前面 n 個組獲得一個附加行。因此,可能不會所有組都獲得相等數量的行,但是組大小最大只可能相差一行。例如,以下查詢按照 score 降序將三個組號分配給不同的 speaker 行:
SELECT speaker, track, score,
ROW_NUMBER() OVER(ORDER BY score DESC) AS rownum,
NTILE(3) OVER(ORDER BY score DESC) AS tile
FROM SpeakerStats
ORDER BY score DESC
以下為結果集:
speaker track score rownum tile
---------- ---------- ----------- ------ ----
Jessica Dev 9 1 1
Ron Dev 9 2 1
Suzanne DB 9 3 1
Kathy Sys 8 4 1
Michele Sys 8 5 2
Mike DB 8 6 2
Kevin DB 7 7 2
Brian Sys 7 8 2
Joe Dev 6 9 3
Robert Dev 6 10 3
Dan Sys 3 11 3
在 SpeakerStats 表中有 11 位演講者。將 11 除以 3 得到組大小 3 和余數 2,這意味著前面 2 個組將獲得一個附加行(每個組中有 4 行),而第三個組則不會得到附加行(該組中有 3 行)。組號(tile 號)1 被分配給行 1 到 4,組號 2 被分配給行 5 到 8,組號 3 被分配給行 9 到 11。通過該信息可以生成直方圖,並且將項目均勻分布到每個梯級。在我們的示例中,第一個梯級表示具有最高得分的演講者,第二個梯級表示具有中等得分的演 講者,第三個梯級表示具有最低得分的演講者。可以使用 CASE 表達式為組號提供說明性的有意義的備選含義:
SELECT speaker, track, score,
CASE NTILE(3) OVER(ORDER BY score DESC)
WHEN 1 THEN 'High'
WHEN 2 THEN 'Medium'
WHEN 3 THEN 'Low'
END AS scorecategory
FROM SpeakerStats
ORDER BY track, speaker
以下為結果集:
speaker track score scorecategory
---------- ---------- ----------- -------------
Kevin DB 7 Medium
Mike DB 8 Medium
Suzanne DB 9 High
Jessica Dev 9 High
Joe Dev 6 Low
Robert Dev 6 Low
Ron Dev 9 High
Brian Sys 7 Medium
Dan Sys 3 Low
Kathy Sys 8 High
Michele Sys 8 Medium