一、 ASE15概述
1、 Sybase ASE 包括的服務
Adaptive server:是整個Sybase的核心數據庫,用於管理整個數據庫資源
Backup server:用於備份與恢復數據用的服務
XP server:用於執行擴展存儲過程的服務(擴展存儲過程,它們是以C語言等編寫的外部程序,以動態鏈接庫(Dll)形式存儲在服務器上,SQL Server可以動態裝載並執行它們。編寫好擴展存儲過程後,固定服務器角色(sysadamin)成員即可在SQL Server服務器上注冊該擴展存儲過程,並將它們的執行權限授權其他用戶。擴展存儲過程只能添加到Master數據庫。)
Monitor server:用於性能調優采集數據的服務
Historical server:用於保存monitor server的數據,用於將來分析用
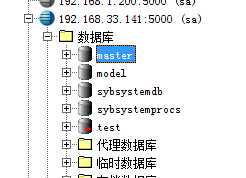
2、 Sybase ASE包括的數據庫
Master、tempdb、model、sybsystemdb、sybsystemprocs、sybsecurity、sybsyntax、dbccdb、pubs1..等
必備數據庫:
Master:包含主要的系統表,用來管理adaptive server服務,不需要太大,一般在180M左右就可以了
Tempdb:主要處理臨時操作
Model:數據庫模板,用來創建新的數據庫
Sybsystemprocs:存放系統存儲過程
Sybsystemdb:主要處理分布式事務管理功能
附加功能數據庫:
Sybsyntax:包括SQL關鍵詞的語法幫助,可用sp_syntax創建
Sybsecurity:審計用數據庫
Dbccdb:檢查數據庫的一致性
例子數據庫:
Pubs1、pubs2:主要做測試用
應用數據庫:客戶自己根據需要創建的數據庫
3、 系統表與系統存儲過程
系統表:如sysdatabases、sysobjects
系統存儲過程
當用戶執行存儲過程時,系統按以下順序進行查找:
首先在當前數據庫查找
如果不在,到sybsystemprocs數據庫查找
如果不在,到master數據庫查找
如果不在,返回錯誤信息
4、 客戶端與運用程序
客戶端工具有以下幾種:
Isql
Interactive sql
Sybase central
Jisql
Sql advantage
5、 接口文件
存放於%Sybase%/sql.ini目錄下,主要記錄客戶端與服務器的連接信息。
6、 系統全局變量
請參考Sybase快速參考手冊
7、 啟動與停止Sybase服務
啟動Sybase服務:
UNIX語法:Startserver [[-f runserver_file][-m]]
NT語法:net start sybsql_servername
停止Sybase服務:
Shutdown [server_name] [with {wait|nowait}]
Wait:讓正在執行的事務完成後再shutdown
No wait:立即shutdown,會造成下次啟動比較慢
關閉數據庫服務器前,先關閉備份服務器
可以利用SET dsquery=servername 設置缺省服務名,下次用ISQL登錄時就可以不用指定服務名了
二、 常用參數配置
1、 Server級參數設置
常用的SERVER參數:
? Max memory:最大內存,一般為系統內存的60-70%
? Max .line engines:引擎數,一般為CPU個數減1,1個CPU配1個,2個CPU可為1或2,考濾雙核的情況。
? Number of engines of startup:
? Number of user connections:用戶連接數
? Number of lock:鎖的數量,小型企業一般為5-10萬,中型企業一般為20-30萬
? Number of devices:允許最多設備數
? Number of open database:同一時間打開數據庫最大數
? Number of open indexes:同一時間打開索引最大數
? Number of open objects:同一時間打開對象最大數
? Procedure cache size:存儲過程緩存,一般為100M-200M
? Default data cache:默認數據緩存,一般為max memory的一半
? Default network packet size:默認網絡包大小,一般為512的倍數
? Max network packet size:最大網絡包大小
? Stack size:為每個進程使用的執行堆棧的大小
目前我們系統裡也用到了部分參數設置,如下圖:
以上參數都存放在配置文件 $Sybase/servername.cfg 中,記錄服務器參數的所有信息。分為動態參數與靜態參數兩種:
動態參數為修改後立即起作用的參數
靜態參數為修改後需要重新啟動服務才起作用的參數
Sybase啟動adaptive server時,首先會按照配置文件的設置分配資源,然後備份配置文件為servername.bak,將上次備份的文件復蓋掉
2、 Database級參數設置
常用數據庫選項如下:
? Allow nulls by default:可以將數據庫中表的列的缺省值由NOT NULL改為NULL
? Auto identity:指定該參數後,可以表中未指定主鍵、唯一索引、identity列的情況下,自動為表創建一個identity列。
? Dbo use .ly:選中後,只有數據庫所有者可以操作數據庫,其它用戶為只讀
? Ddl in tran:可指定用戶在事務中執行數據操作語言(DDL)
? Indentity in nouninque index:可以使在邏輯上表中非唯一的索引在內部唯一,前提是表中必須有identity列,可與auto identity選項結合使用。
? Read .ly:數據庫只讀選項
? Signle user:設置只能單用戶訪問,tempdb數據庫除外。
? Unique auto_indentity index:向表中添加一個具有唯一非聚集索引的identity列
? Abort tran . log full:超出阈值時,如何處理正在運行的事務,如果選中,寫入日志事務的查詢將被注銷,直到日志中的空間被釋放,如果不選,則只能等到日志空間釋放。
? No chkpt . recovery:保留數據庫最新副本
? No free space acctg:禁止對非日志段執行可用空間計數與阈值操作
? Select into/bulkcopy/pllsort:是否允許此操作。
? Trunk log . chkpt:控制事務日志在執行checkpoint操作時,是否截斷日志。
3、 內存管理
內存管理中的幾個概念:
? 數據緩存:屬於adaptive server 內存的一部分,用於存放正在執行的數據頁、索引、日志頁
? 過程緩存:屬於adaptive server 內存的一部分,用於存放正在使用的查詢計劃
? MRU-LRU鏈:緩存中的頁橫穿MRU-LRU鏈,從最近最多被使用的頁(MRU)到最近最少被使用的頁(LRU)轉儲
? 自旋鎖競爭:當adaptive server配置多個引擎時,自旋鎖對緩存散列表的同步訪問,對於高吞吐量的OLTP操作,會嚴重影響性能
可通過自定義命名緩存提升系統性能,好處如下:
? 使用命名緩存,可以綁定熱點對象到專用的內存區,可降低物料I/0和使對象駐留在內存中,不太頻繁使用的對象可保存在缺省的數據緩存中,因為裡面已經不包含熱點表了
? 使用命名緩存,可減少對缺省數據緩存的自旋鎖競爭,因為每個命名緩存都有自己的緩存散列表,
創建命名緩存:
Sp_cacheconfig cachename ,20M
檢查命名緩存的配置與綁定:
Sp_helpcache
修改命名緩存為只適用於日志的緩存:
Sp_cacheconfig cacehname,logonly
綁定和解綁對象到命名緩存:
Sp_bindcache “cachename”,”dbname”,”tbname”
Sp_unbindcache “dbname”,”tbname”
Sp_unbindcache_all “cachename”
刪除命名緩存:
Sp_cacheconfig “cachename”,”0”
Log io 的設置可以提高吞吐量
Sp_logiOSize
創建緩沖池:
Sp_poolconfig cachename,”4M”,”4K”
修改緩沖池:
Sp_poolconfig cachename,”5M”,”4K”,”16K”
刪除緩沖池:
Sp_poolconfig cachename,”0”,”16K”
三、 數據庫管理
1、 設備與數據庫管理
創建一個設備:
Disk init name = “dev02”,physname = “e:dev02.dat”,dsync=false,size = “50M”
創建一個數據庫:
Create database mydb . dev02=”10M” log . logo2=”2M”
擴充數據庫空間:
Alter database mydb . dev02=10
護充日志空間:
Alter database mydb log . log02 = 10M
將日志與數據分別放在不同的物料設備上,有以下幾點好處:
? 做日志備份時節省時間和資源
? 建立固定日志大小,以防止其它數據庫活動競爭空間
? 提高性能
? 降低數據庫和日志同時損壞的可能性
2、 數據庫的備份與恢復
? 數據庫備份:
Dump database 數據庫名(mydb) to “e:mydb.dump”
? 數據庫恢復:
Load database數據庫名(testdb) from “e:mydb.dump” with headeronly
? 日志滿後需要截日志解決:
dump tran mydb with truncate_only
dump tran mydb with no_log
truncate_only 與 no_log的區別詳見數據庫備份與恢復
當日志滿或者別的原因導致有事務掛起的時候,with truncate_only是不管用的,因為它也會被掛起,用with no_log是沒問題的,只要數據庫的狀態是online,不過可能會導致數據庫不一致,尤其是在此之前做過alter database擴數據庫空間的話。
? 為什麼有些時候無法截斷日志
有兩種情況,可能出現這個問題。一是應用系統給SQL Server發送了一個用戶自定義事務,一直未提交,這個最早活躍事務阻礙系統截斷日志。二是客戶端向SQL Server發送了一個修改數量大的事務,清日志時,該事務還正在執行之中,此事務所涉及的日志只能等到事務結束後,才能被截掉。
對於第一種情況,只要督促用戶退出應用或者提交事務,系統管理員便可清掉日志。因為給SQL Server發送Dump transaction with no-log或者with truncate-only,它截掉事務日志的非活躍部分。所謂非活躍部分是指服務器檢查點之間的所有已提交或回退的事務。而從最早的未提交的事務到最近的日志記錄之間的事務日志記錄被稱為活躍的。從此可以看明,打開的事務能致使日志上漲,因為在最早活躍事務之後的日志不能被截除。
對於第二種情況,道理也同上。只是在處理它時,需慎重從事。如果這個大事務已運行較長時間,應盡量想法擴大數據庫日志空間,保證該事務正常結束。若該事務被強行回滾,SQL Server需要做大量的處理工作,往往是正向執行時間的幾倍,系統恢復時間長,可能會影響正常使用的時間
3、 數據庫表管理
表在用過一段時間後會出現性能下降,插入、刪除、更新數據非常慢等問題,可用optdiag命令查看當前表的統計信息,查看聚簇率是否降低,是否有頁碎片等信息,可用以下幾種方法消除頁碎片:
對於APL表
可刪除索引重建
用BCP命令將數據導一遍
用SELECT INTO 命令重新建表
對於DOL表,除用以上方式外,還可以用reorg rebuild tablename命令完成
備份表操作:
bcp [數據庫名]..[表名] out e:aa.txt CC CU[用戶] CP[密碼] CS[服務名]
4、 Tempdb 庫的管理
以下幾種操作會對tempdb 有影響
? order by
利用聚集索引可以避免利用tempdb資源,因為聚集索引本身可以排序
? group by
盡可能少的使用group by
? where 關聯
set sort_merge . 可以提高關聯速度,不過可能會占用系統資源
? 在tempdb中創建表
create table #name 會話級
create table name shutdown級
? 建索引也可以利用
使用sp_helpdb命令可查看tempdb的情況
為tempdb指定命名緩存,首先創建命名緩存,前面已經介紹創建語法,再綁定
使用tempdb的三大問題:
1)、數據庫大小的問題
擴數據庫大小或可以自己建一個數據庫放裡面
2)、性能問題
將tempdb放到速度較快的設備上,或將tempdb放到命名緩存裡,考慮將tempdb放到多個設備上
3)、鎖的競爭
系統表的鎖競爭,Sybase12.3.0中支持多個臨時數據庫,可以將用戶綁定到其它臨時數據庫上。
四、 性能優化
1、 Adaptive server 優化器:
優化器統計值存儲在兩個系統表中:
Systabstats:存儲表和索級級的統計,如頁數、行數、索引頁數、聚集率等
Sysstatistics:存儲列級已知的統計,如密度值、直方圖值等
將統計值存放在表中的好處:
統計值的空間受數據庫尺寸的限制
基於表的統計值有很高的精確度
基於表的方法提供了一個全局倉庫,使排錯和收集信息簡單化
基於表的方法有可擴展性,對以後加強功能的處理比較簡單、容易
2、 使用optdiag查看優化器統計
Optdiag是顯示、修改、模擬統計值的命令行工具
查看表的統計值命令:
Optdiag statistics dbname..tbname CU CP
管理優化器統計值:
Create index 創建索引
Upate statistics 更新統計值
Delete statistics 刪除統計值
Sp_flushstats 從內存中刷新統計值
使用sp_sysmon 監控數據頁聚集率
3、 數據庫調優
數據庫系統參數配置的調優:
修改內存參數
合理的分配存儲過程緩沖區與數據緩沖區的大小
合理分配網絡包的大小
設置鎖的個數
設置鎖的機制
建立索引與表分區
數據庫服務器可用CPU的個數
擴充TEMPDB的大小
增加use log cache size
4、 應用程序的調優:
盡量將事務最小化
索引的建立與SQL的寫法要匹配
盡量減少網絡流量
並發數多時,可讓客戶端承擔部分工作量
掃描慢的時候加 set sort_merge . 合並連接會快很多,缺點是會在執行期間占用很多資源。會話結束後自動結束
五、 鎖的管理
鎖的粒度:表鎖、頁鎖、行鎖等
鎖的基本類型:共享鎖(S)、更新鎖(U)、排它鎖(X)
死鎖:兩個任務或進程在自己的表或頁上加鎖,並請求對訪的資源,就會造成死鎖
死鎖查檢周期:sp_configure ”deadlock checking period”,”600ms”,如果值為0,則在發生死鎖時就檢查,不過在沒有死鎖的情況下會浪費資源
打印死鎖日志:Sp_configure “print deadlock information”,1
鎖方案:
全頁鎖(APL):插入數據時自動聚集索引
數據頁鎖(DPL):插入數據時不自動聚集索引
數據行鎖(DRL):插入數據時不自動聚集索引
可配置服務器級別鎖方案:
Sp_configure “lock scheme”,0,”allpages|datapages|datarows”
可在創建表時配置鎖方案:
Create table(….) lock datarows
可用select into 配置鎖方案:
Select col into talbe lock datarows
可用alter table 配置鎖方案:
Alter table tbname lock datarows
配置鎖的數量命令:
Sp_configure “number of lock”,25000
Sp_who:查詢活動的進程與相關的阻塞信息
Sp_lock:查詢當前系統相關鎖的信息
Sp_familylock:查詢正在工作族的鎖
Sp_sysmon “00:00:10”:監控10秒
Sp_object_stats “00:00:10”,5:(監控排名前5位的表,10秒,發生了什麼樣的鎖等等)
減少鎖競爭的方法:
增加索引
縮短事務
減少尾頁競爭
鎖的升級:
鎖升級一般都是從頁級鎖或行級鎖直接升級到表鎖,行級鎖不能升級到頁級鎖。
修改鎖的升級阈值:
Sp_configure
Sp_setpglockpremote
Sp_setrowlockpremote
High water mark(HWM):上限
Lower water mark(LWM):下限
Percentage (PCT):百分比
大於上限值就升,小於下限值就不升,在兩者之間看百分比