您正在看的sybase教程是:Sybase數據庫技術(71
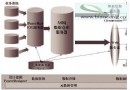
概述隨著電信市場的逐步開放,新興的運營商不斷產生,電信市場
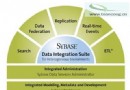
如今,企業迫切希望 DBA(數據庫管理員)和開發人員能夠集
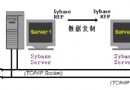
SYBASE復制服務器(Sybase Replicatio