接著,Sybase公司全球市場運營部高級副總裁兼首席市場官Raj Nathan演講中提到Sybase公司專注創新,擁有105項專利,還有166項專利處於待批准的狀態,如果按平均人數來算,Sybase技術人員很可能比IBM每個人平均的專利數還要高。讓記者明顯的感到Sybase公司對自有研究力量的看重。
Sybase能夠最根本解決的就三塊,一個是數據的管理,一個是數據的分析,一個是數據的移動。我們在下圖就企業的IT架構需求和Sybase能夠提供的軟件和服務進行對照說明:
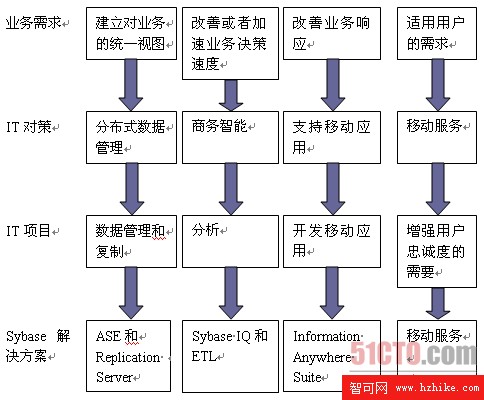 Sybase為不同用戶需求提供的對應解決方案
Sybase為不同用戶需求提供的對應解決方案
我們從這裡看到了Sybase公司為中國用戶提供的軟件和服務的大框架,祝福這家公司越走越好!
Sybase公司簡介
Sybase成立於1984年,總部設在美國加州,是一家信息管理和信息移動技術的企業級軟件與服務公司,其技術及解決方案將數據從數據中心傳遞到任何所需的地方。Sybase提供了在任何時間、任何地點均可以進行信息安全傳遞的、開放的、跨平台的解決方案。
備注:解讀Sybase IQ的核心技術
山東省農業銀行使用Sybase IQ產品的客戶對Sybase IQ如何實現它的高效查詢(利用列式存儲實現查詢速度提供10到100倍)和超強存儲(可以壓縮1PB的數據到155TB,實現85%的壓縮比,壓縮比例達30%到70%)的原理提出了疑問。
記者就這一Sybase IQ的核心技術為大家進行解讀,幫您了解它能夠實現這樣的高效率的秘密所在。
Sybase IQ分析型數據倉庫引擎,以列存儲、數據壓縮和豐富的索引等創新技術,將數據結果壓縮至傳統RDBMS方式的1/3至1/7,獲得10-100倍的響應速度。尤其是,Sybase IQ通常能夠在所要求的硬件資源減少的情況下,仍能提供查詢性能方面的巨大改進(尤其是對復雜查詢或者需要大表掃描的查詢)。那麼,Sybase IQ是如何以大量不同的方式充分利用每個列的特性呢?
首先,Sybase IQ發布了多種專門的索引以提升查詢性能。這些包括為低基數數據、聯合列、文本分析、Web應用的實時比較以及實時的數據與時間序列分析所設立的索引。
2、聯合使用列存儲與Sybase IQ的Bit-Wise索引(另一選擇)的結果就是,聚合可以隨時進行。如果說事務的預先聚合是抽取、轉換、加載(ETL)功能的重要一部分,那麼在此可能並不需要一個完整的ETL層。另外,這種方法比預先聚合的數據具有更大的靈活性(由於你並不總是事先了解你所要進行聚合的內容)。
3、列存儲方法使數據壓縮比使用傳統方法下更容易實現,而且,壓縮效果也更加顯著。事實上,Sybase IQ即使使用了索引,其存儲也從未超過原始數據的大小。這點與傳統數據庫相比,取得了數倍的改進效果。Sybase IQ在實際應用中已被證實,數據壓縮比例多至原始數據集的50%到70%。而在傳統的數據庫中,由於數據的預先聚合、物化視圖以及傳統的基於行的索引等等,數據膨脹至原始數據的3到6倍並不鮮見。
4、使用Sybase IQ,向表中增加或加載一列數據如同傳統關系型數據庫中增加一行數據一樣容易。
5、基於列的方法比起傳統的數據倉庫,更容易維護以及需要更少的的調優。
6、Sybase IQ擁有多線程與24 x 7的高可用性特征。特別是,獨立的讀節點與寫節點意味著可以並行處理這些進程,而互不影響。
7、同傳統方法相比,Sybase IQ提供了顯著的性能優勢。除了上述提到的特性外,它也支持Rcubes(Relational Datacube)平面模型,比傳統的星型模型擁有更多優勢。尤其是,Rcubes可以顯著地加速執行速度,同時提高運行中的性能以及增強靈活性。
8、Sybase IQ支持幾乎無限的並發查詢,而不是僅僅對一些特定的查詢使用並行機制以提高其性能。這不再是一種尋求平衡的方式,因為Sybase IQ的列存儲方式與傳統方法相比提供了根本性的性能提高(常常要快幾百倍)。
9、雖然列存儲不同於基於行的進程,但是從管理的角度來看,它們卻幾乎沒什麼不同。例如,對數據庫的訪問同樣是基於標准SQLANSI99)。類似的,Sybase IQ支持OLAP Cubes,其方式與傳統關系型基本相同。
Sybase IQ的秘密在於其索引。隨著Sybase客戶發現了新的分析需求,Sybase可以簡捷地建立新的索引以滿足這些需求。這種方法的奇妙之處在於為數據倉庫增加新的索引幾乎不會(即使有也是微乎其微)影響數據倉庫的架構或使用倉庫的分析型應用。在實時企業與閉環應用領域,Sybase將索引視為在TB數量級(將來)甚至PB數量級數據倉庫中獲得更高查詢性能的關鍵。它已有的7種索引機制是:
◆Low Fast 索引
低基數索引,它使用一個被稱之為“代號化”的進程。使用該進程,數據被轉換為代號,然後存儲這些代號而不是數據。這對於減少冗余數據的數量尤其有用。例如,在整個英國擁有大量客戶群的公司,將需要存儲客戶的地址。這將意味著巨大數量的重復的郡的名稱。因此,不是保存大量的“班夫郡”的實例,例如,Sybase將會用一個數字代替每個郡的名稱。因此,由於班夫郡按照拼音排列在英國是第5個郡(排在Aberdeen,Armagh,Avon與Ayrshire之後)因此,它可能就會被設值為5。如果一個列包含一個數字值,該值自身可以一用於代號化的基礎。一旦建立了代號(這是一個自動進行的進程),一個位圖索引將被建立以表示這些代號。代號化典型地應用於列數據存在有限數量的可能取值。這也是為什麼Sybase稱之為低基數索引的原因,典型的,它僅用於不同的取值個數在1500以內的域。
◆Bit-Wise索引
對於高基數的域,那些取值個數超過1500個(如金額值),Sybase使用其專利的被稱之為Bit-Wise索引的技術。這在你希望在范圍搜索的時候,同時進行計算的情況下,尤為有用,例如,查找銷售價格低於50歐元的貨品數量及總收入。如同位圖的其他變量,該方法的優勢之一就是計數(count)查詢可以直接通過讀取索引獲得答案,而無需讀取數據。
◆High Group索引
實際上,它是B-樹索引。然而,此處的原則是,用戶僅僅在幾個列有可能作為一個組來使用的情況下,尤其是高基數與低基數的聯合搜索時,才定義這些索引。比如可能有這樣的例子,按照商店(低基數)查詢產品銷售清單與價格(高基數)。
◆Fast Projection索引
該索引類型(缺省的)就是列存儲本身。如果用戶總是打算檢索整個列的數據,則列存儲事實上意味著列可以直接映射到表或查詢中,而無需顯式的定義任何索引。這非常有用,例如在“Where”從句中。
◆Word索引
這是一個文本索引。它基於關鍵詞或短語字符串搜索。這種類型的索引,歷史上一直沒有用於數據倉庫中。然而,它有著大量重要的市場,在這些市場上,能夠聯合定量與定性的分析非常重要。例如,在醫療行業,醫生的診斷通常就是:筆記。為了獲取信息,例如發病率,因此可能必須訪問這種非結構化的數據。
◆Compare索引
這個索引技術允許數據列的比較,從效果上講,類似於“if…then…else”表達式。例如,“if支出大於收入,then…”。該類型的索引對於在Web應用中實時比較尤其有用。
◆Join 索引
正如索引的名稱所示,它是為消除表連接的需要而設計的。正象大多支持索引的情況,它可能在預先已知的查詢需求下更為有用。
◆Time Analytic 索引
這為基於日期、時間、日期與時間建立索引提供了選項。需要注意的是,對於傳統的關系型數據庫,處理基於時間的查詢尤為困難。
對於Sybase IQ 數據壓縮實現的超強存儲的原因是:由於數據按列存儲,相鄰接的字段值具有相同的數據類型,其二進制值的范圍通常也要小得多,所以壓縮更容易,壓縮比更高。Sybase IQ 對按列存儲的數據通常能得到大於50%的壓縮。更大的壓縮比例,加上大頁面I/O,使得Sybase IQ在獲得查詢的優良性能的同時,減少了對於存儲空間的需求。
在傳統的數據庫中,為提高查詢性能所建的索引占用的磁盤空間往往需要比數據本身需要的磁盤空間多出3-10倍。而Sybase IQ 存儲數據所占用的磁盤空間通常只是原數據文件的40%-60%,是傳統數據庫所占用空間的幾分之一。
智能壓縮技術,與精巧的索引結構和列存儲結合,給了IQ 比其他數據庫引擎高得多的存儲效果。這將獲得更低的存儲成本與更高的性能(因為系統僅需很少的磁盤I/O讀取或寫入任何給定的數據庫塊)。