首先我們先安裝這個數據庫,你可以使用windows或者linux,但推薦使用的是linux,我使用的是ubuntu12.04.在下方的網址中共可以下載,基本都是64位的系統。如果位linux系統也可以使用命令行安裝,我就是使用sudo apt-get install mongodb。
https://www.mongodb.org/downloads
MongoDB 由 databases 組成,databases 由 collections 組成,collections 由documents(相當於行)組成,而 documents 有 fields(相當於列)組成。
help
最開始應該介紹的就是help函數,學習一個東西最好的文檔就是官方文檔,下面我會給出幾個指令的執行過程。最基本的形式就是db.help(),也可以在中間加上數據庫的名稱如db.douban.help()。
> db.help()
DB methods:
db.addUser(username, password[, readOnly=false])
db.auth(username, password)
db.cloneDatabase(fromhost)
db.commandHelp(name) returns the help for the command
db.copyDatabase(fromdb, todb, fromhost)
db.createCollection(name, { size : ..., capped : ..., max : ... } )
db.currentOp() displays the current operation in the db
db.dropDatabase()
db.eval(func, args) run code server-side
db.getCollection(cname) same as db['cname'] or db.cname
db.getCollectionNames()
db.getLastError() - just returns the err msg string
db.getLastErrorObj() - return full status object
db.getMongo() get the server connection object
db.getMongo().setSlaveOk() allow this connection to read from the nonmaster member of a replica pair
db.getName()
db.getPrevError()
db.getProfilingLevel() - deprecated
db.getProfilingStatus() - returns if profiling is on and slow threshold
db.getReplicationInfo()
db.getSiblingDB(name) get the db at the same server as this one
db.isMaster() check replica primary status
db.killOp(opid) kills the current operation in the db
db.listCommands() lists all the db commands
db.logout()
db.printCollectionStats()
db.printReplicationInfo()
db.printSlaveReplicationInfo()
db.printShardingStatus()
db.removeUser(username)
db.repairDatabase()
db.resetError()
db.runCommand(cmdObj) run a database command. if cmdObj is a string, turns it into { cmdObj : 1 }
db.serverStatus()
db.setProfilingLevel(level,) 0=off 1=slow 2=all
db.shutdownServer()
db.stats()
db.version() current version of the server
db.getMongo().setSlaveOk() allow queries on a replication slave server
db.fsyncLock() flush data to disk and lock server for backups
db.fsyncUnock() unlocks server following a db.fsyncLock()
> db.douban.help()
DBCollection help
db.douban.find().help() - show DBCursor help
db.douban.count()
db.douban.dataSize()
db.douban.distinct( key ) - eg. db.douban.distinct( 'x' )
db.douban.drop() drop the collection
db.douban.dropIndex(name)
db.douban.dropIndexes()
db.douban.ensureIndex(keypattern[,options]) - options is an object with these possible fields: name, unique, dropDups
db.douban.reIndex()
db.douban.find([query],[fields]) - query is an optional query filter. fields is optional set of fields to return.
e.g. db.douban.find( {x:77} , {name:1, x:1} )
db.douban.find(...).count()
db.douban.find(...).limit(n)
db.douban.find(...).skip(n)
db.douban.find(...).sort(...)
db.douban.findOne([query])
db.douban.findAndModify( { update : ... , remove : bool [, query: {}, sort: {}, 'new': false] } )
db.douban.getDB() get DB object associated with collection
db.douban.getIndexes()
db.douban.group( { key : ..., initial: ..., reduce : ...[, cond: ...] } )
db.douban.mapReduce( mapFunction , reduceFunction , )
db.douban.remove(query)
db.douban.renameCollection( newName , ) renames the collection.
db.douban.runCommand( name , ) runs a db command with the given name where the first param is the collection name
db.douban.save(obj)
db.douban.stats()
db.douban.storageSize() - includes free space allocated to this collection
db.douban.totalIndexSize() - size in bytes of all the indexes
db.douban.totalSize() - storage allocated for all data and indexes
db.douban.update(query, object[, upsert_bool, multi_bool])
db.douban.validate( ) - SLOW
db.douban.getShardVersion() - only for use with sharding
db.douban.getShardDistribution() - prints statistics about data distribution in the cluster
use
use deng可以用來創建 deng,不用擔心 deng 不會創建,當創建第一個 collection 時,deng會自動創建。
insert
db.unicorns.insert({name: 'demo', sex: 'm', weight: 70}),插入一個數據 collection 為 unicorns,使 用 db.getCollectionNames() , 會 得 到 unicorns 和 system.indexes 。system.indexes 對每個 DB 都會有,用於記錄 index。可以通過find函數查看是否插入成功。
find
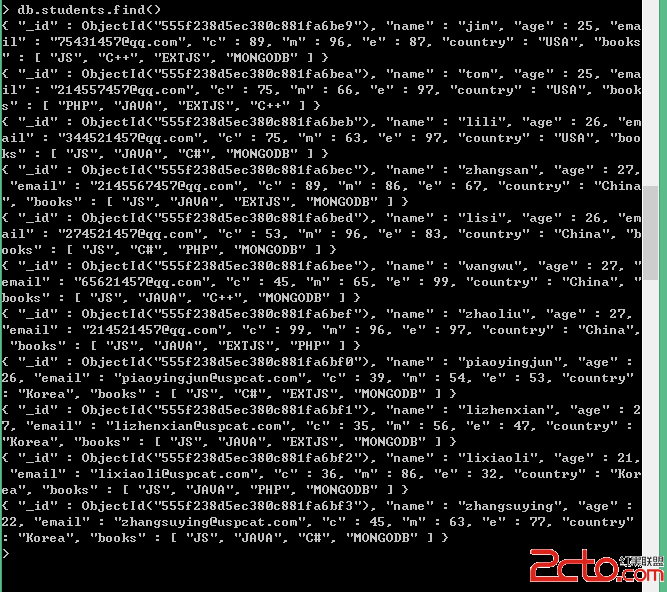
db.unicorns.find()會看到 document。就相當於mysql中的select * from table; 查看集合中的所有內容。
使用查詢
db.unicorns.find({name: 'Dunx'})
其他說明:
$lt, $lte, $gt, $gte and $ne 分別表示小於、小於等於、大於、大於等於、不等於
db.unicorns.find({gender: {$ne: 'f'}, weight: {$gte: 701}})
$exists 用於表示 field 是否存在
db.unicorns.find({vampires: {$exists: false}})
or 和 and
db.unicorns.find({gender: 'f', $or: [{loves: 'apple'}, {loves: 'orange'}, {weight: {$lt: 500}}]})
db.unicorns.find(null, {name: 1})
只返回 name 這個 field,具體如下所示:
> db.unicorns.find(null, {name: 1})
{ "_id" : ObjectId("4da6f22da8d5cd3b72081cf7"), "name" : "Aurora" }
{ "_id" : ObjectId("4da6f22da8d5cd3b72081cf6"), "name" : "Horny" }
{ "_id" : ObjectId("4da6f22da8d5cd3b72081cf8"), "name" : "Unicrom" }
{ "_id" : ObjectId("4da6f22da8d5cd3b72081cf9"), "name" : "Roooooodles" }
{ "_id" : ObjectId("4da6f22da8d5cd3b72081cfa"), "name" : "Solnara" }
{ "_id" : ObjectId("4da6f22da8d5cd3b72081cfb"), "name" : "Ayna" }
{ "_id" : ObjectId("4da6f22da8d5cd3b72081cfc"), "name" : "Kenny" }
{ "_id" : ObjectId("4da6f22da8d5cd3b72081cfd"), "name" : "Raleigh" }
{ "_id" : ObjectId("4da6f22da8d5cd3b72081cfe"), "name" : "Leia" }
{ "_id" : ObjectId("4da6f22da8d5cd3b72081cff"), "name" : "Pilot" }
{ "_id" : ObjectId("4da6f22da8d5cd3b72081d00"), "name" : "Nimue" }
{ "_id" : ObjectId("4da6f231a8d5cd3b72081d01"), "name" : "Dunx" }
> db.unicorns.find(null, {name: 1,_id:0})
{ "name" : "Aurora" }
{ "name" : "Horny" }
{ "name" : "Unicrom" }
{ "name" : "Roooooodles" }
{ "name" : "Solnara" }
{ "name" : "Ayna" }
{ "name" : "Kenny" }
{ "name" : "Raleigh" }
{ "name" : "Leia" }
{ "name" : "Pilot" }
{ "name" : "Nimue" }
{ "name" : "Dunx" }
db.unicorns.find().sort({weight: -1})
db.unicorns.find().sort({name: 1, vampires: -1})
#1 表示升序,-1 表示降序
db.unicorns.find().sort({weight: -1}).limit(2).skip(1) #得到第二個和第三個,limit 規定查詢個數,skip 規定忽略幾個。
db.unicorns.count({vampires: {$gt: 50}})
#or
db.unicorns.find({vampires: {$gt: 50}}).count()
remove
db.unicorns.remove() 如下面所示。 > db.unicorns.remove() > db.unicorns.find() >
update
db.unicorns.update({name: 'jingdong'}, {weight: 590})
注意:此語句執行後,先查詢 name 是'jingdong'的所有數據,然後將 name是'jingdong'的整個 document 都替換為{weight: 590}。
即 db.unicorns.insert({name: 'jingdong', dob: new Date(1979, 7, 18, 18, 44),loves:['apple'], weight: 575, gender: 'm', vampires: 99});整個替換為{weight: 590},最後只剩一個{weight: 590}。
執行$set,不會替換原有數據,因此正確的更新方式如下:
db.unicorns.update({name: 'jingdong'}, {$set: {weight: 590}})
db.unicorns.update({name: 'Pilot'}, {$inc: {weight: 500}})
$inc 增加或減少數字 如果原來為500之後會變為1000,因為500+500 = 1000
db.unicorns.update({name: 'Aurora'}, {$push: {loves: 'sugar'}})
$push 增加數組元素
$pop 減少數組元素
若存在則更新,否則添加
db.hits.update({page: 'unicorns'}, {$inc: {hits: 1}}, true);
db.hits.find();
使用第三個參數設置是否 true(upset)
,默認是 false
#批量更新
db.unicorns.update({}, {$set: {vaccinated: true }});
db.unicorns.find({vaccinated: true});
不會將所有的數據的 vaccinated 都更新為 true
若將所有的數據的 vaccinated 都更新為 true,則如下:
db.unicorns.update({}, {$set: {vaccinated: true }}, false, true);
db.unicorns.find({vaccinated: true});
ensureIndex
創建索引的方式
db.unicorns.ensureIndex({name: 1})
刪除索引的方式
db.unicorns.dropIndex({name: 1})
創建獨立索引
db.unicorns.ensureIndex({name: 1}, {unique: true})
創建聯合索引
db.unicorns.dropIndex({name: 1, vampires: -1})
使用 web 獲得 mongoDB 的信息
使用 http://localhost:28017/ 獲得 MongoDB 的信息。
數據備份和恢復
使用 mongodump備份數據庫
mongodump
使用 mongorestore恢復數據庫
mongorestore