Redis 是一個高性能的key-value數據庫, 支持主從同步, 完全實現了發布/訂閱機制, 因此可以用於聊天室等場景. 主要表現於多個浏覽器之間的信息同步和實時更新.
和Memcached類似,它支持存儲的value類型相對更多,包括string(字符串)、list(鏈表)、set(集合)、zset(sorted set –有序集合)和hash(哈希類型)。這些數據類型都支持push/pop、add/remove及取交集並集和差集及更豐富的操作,而且這些操作都是原子性的。在此基礎上,redis支持各種不同方式的排序。與memcached一樣,為了保證效率,數據都是緩存在內存中。區別的是redis會周期性的把更新的數據寫入磁盤或者把修改操作寫入追加的記錄文件,並且在此基礎上實現了master-slave(主從)同步。數據可以從master向任意數量的slave上同步,slave可以是關聯其他slave的master。這使得Redis可執行單層樹復制。存盤可以有意無意的對數據進行寫操作。由於完全實現了發布/訂閱機制,使得slave在任何地方同步樹時,可訂閱一個頻道並接收master完整的消息發布記錄。同步對讀取操作的可擴展性和數據冗余很有幫助.
本文的內容參考博文超強、超詳細Redis數據庫入門教程.
可以從Redis官網下載最新的redis, 然後安裝即可.
make install
cd utils && sudo ./install_server.sh
安裝過程中, 會有一些端口, 配置文件路徑等的設置, 這裡選擇默認端口6379. 然後執行redis-server即可在默認端口上啟動成功.
42068:M 16 May 09:57:11.403 # Server started, Redis version 3.0.1
42068:M 16 May 09:57:11.404 * The server is now ready to accept connections on port 6379
redis-cli執行redis-cli即可啟動命令行工具, 也可自行指定host及port.
redis-cli -h localhost -p 6379
提供了非常豐富的命令對redis的數據進行操作, 數據都是以key-value的形式存儲的, 因此get/set操作是使用最常見的.
使用help+命令即可查看命令幫助.
對string的操作
127.0.0.1:6379> exists hello // 查看key是否存在
(integer) 1
127.0.0.1:6379> set hello world // 設置hello-world
OK
127.0.0.1:6379> get hello // 獲取hello的值
"world"
127.0.0.1:6379> type hello // 值類型
string
127.0.0.1:6379[2]> substr hello 1 2 // 獲取substring
"or"
127.0.0.1:6379[2]> append hello ! // 字符串連接
(integer) 6
127.0.0.1:6379[2]> get hello
"world!"
127.0.0.1:6379> set haha heihei
OK
127.0.0.1:6379> keys h* // 返回滿足條件的所有key
1) "hello"
3) "haha"
127.0.0.1:6379> randomkey // 隨機返回一個key
"haha"
127.0.0.1:6379> randomkey
"hello"
127.0.0.1:6379> rename hello hehe // 重命名key
OK
127.0.0.1:6379> get haha
"heihei"
127.0.0.1:6379> expire haha 10
(integer) 1 // 設置haha的活動時間(s)
127.0.0.1:6379> ttl haha
(integer) 7 // 獲取haha的活動時間
127.0.0.1:6379> get haha
(nil) // expire 時間到期後,該haha-heihei會刪除
127.0.0.1:6379[2]> del hello
(integer) 0
對list的操作redis中的list在底層實現上是鏈表. 因此, 無論list的空間復雜度是多少, 其時間復雜度是常數級別的. 即使用lpush在10個元素的list頭部插入新元素, 和在上萬個元素的lists頭部插入新元素的速度相當. 但lists中的元素定位會比較慢.
常見操作有lpush, rpush, lrange等.
127.0.0.1:6379[2]> lpush list1 1 // 頭部插入數據
(integer) 1
127.0.0.1:6379[2]> lpush list1 2
(integer) 2
127.0.0.1:6379[2]> rpush list1 0 // 尾部插入數據
(integer) 3
127.0.0.1:6379[2]> lrange list1 0 1 // 列出編號0~1的元素
1) "2"
2) "1"
127.0.0.1:6379[2]> lrange list1 0 -1 // 列出編號0到倒數第一個的元素
1) "2"
2) "1"
3) "0"
127.0.0.1:6379[2]> llen list1 // lists長度
127.0.0.1:6379[2]> lindex list1 1 // 根據index獲取元素
"1"
127.0.0.1:6379[2]> ltrim list1 1 2 // 截取,僅保留編號1~2之間的元素
OK
127.0.0.1:6379[2]> lrange list1 0 10
1) "1"
2) "0"
(integer) 3
127.0.0.1:6379[2]> lset list1 1 haha // 給1位置的元素賦值為haha
OK
127.0.0.1:6379[2]> lset list1 2 haha // 賦值,不能超出lists范圍
(error) ERR index out of range
127.0.0.1:6379[2]> lrange list1 0 10
1) "1"
2) "haha"
127.0.0.1:6379[2]> rpush list1 haha
(integer) 3
127.0.0.1:6379[2]> rpush list1 haha
(integer) 4
127.0.0.1:6379[2]> lrange list1 0 10
1) "1"
2) "haha"
3) "haha"
4) "haha"
127.0.0.1:6379[2]> lrem list1 2 haha 刪除2個值為haha的元素
(integer) 2
127.0.0.1:6379[2]> lrange list1 0 10
1) "1"
2) "haha"
127.0.0.1:6379[2]> lpop list1
"1"
127.0.0.1:6379[2]> lrange list1 0 10
1) "haha"
可以使用list來實現一個消息隊列(如博客的評論內容), 確保先後順序, 而不必像mysql那樣使用order by來排序.
使用lrange還可以很方便地實現分頁功能.
對set的操作redis的set是無序的集合, 其中的元素沒有先後順序.
常見操作如下:
127.0.0.1:6379[2]> sadd set1 0 // 像set1中添加元素0
(integer) 1
127.0.0.1:6379[2]> sadd set1 1
(integer) 1
127.0.0.1:6379[2]> smembers set1 // 返回set1中的所有元素
1) "0"
2) "1"
127.0.0.1:6379[2]> scard set1 // 返回set的基數
(integer) 2
127.0.0.1:6379[2]> sismember set1 0 // 測試set1中是否包含元素0
(integer) 1
127.0.0.1:6379[2]> srandmember set1 // 隨機返回一個元素
"0"
127.0.0.1:6379[2]> sadd set2 0
(integer) 1
127.0.0.1:6379[2]> sadd set2 2
(integer) 1
127.0.0.1:6379[2]> sinter set1 set2 // 求交集
1) "0"
127.0.0.1:6379[2]> sinterstore set3 set1 set2 // 保存交集到set3
(integer) 1
127.0.0.1:6379[2]> smembers set3
1) "0"
127.0.0.1:6379[2]> sunion set1 set2 // 求並集
1) "0"
2) "1"
3) "2"
127.0.0.1:6379[2]> sdiff set1 set2 // 求差集
1) "1"
127.0.0.1:6379[2]> sdiff set2 set1
1) "2"
對zset的操作zset是一種有序集合(sorted set), 其中每個元素都關聯一個序號score.
常見操作有zrange, zadd, zrevrange等
127.0.0.1:6379[2]> zadd zset1 1 dianping.com // 添加元素, score為1
(integer) 1
127.0.0.1:6379[2]> zadd zset1 2 baidu.com
(integer) 1
127.0.0.1:6379[2]> zadd zset1 3 qq.com
(integer) 1
127.0.0.1:6379[2]> zcard zset1 // 返回zset的基數
(integer) 3
127.0.0.1:6379[2]> zscore zset1 dianping.com // 返回元素的score
"1"
127.0.0.1:6379[2]> zrank zset1 dianping.com // 返回元素的rank
(integer) 0
127.0.0.1:6379[2]> zrange zset1 0 1 // 選取元素, score
從小到大
1) "dianping.com"
2) "baidu.com"
127.0.0.1:6379[2]> zrevrange zset1 0 1 // score從大到小
1) "qq.com"
2) "baidu.com"
127.0.0.1:6379[2]> zrem zset1 qq.com // 刪除元素
(integer) 0
127.0.0.1:6379[2]> zincrby zset1 5 taobao.com // 如果元素不存在, 則添加該元素, 設置score為5
"5"
127.0.0.1:6379[2]> zcard zset1
(integer) 3
127.0.0.1:6379[2]> zincrby zset1 10 dianping.com // 如果元素存在, 則其score增加10
"11"
127.0.0.1:6379[2]> zrange zset1 0 10 withscores
1) "taobao.com"
2) "5"
3) "dianping.com"
4) "11"
此外, 還有zrevrank, zrevrange, zrangebyscore, zremrangebyrank, zramrangebyscore, zinterstore/zunionstore等操作.
對hash的操作hash也是一種非常常見的結構.
127.0.0.1:6379[2]> hset hash1 key1 value1 // 添加元素
(integer) 1
127.0.0.1:6379[2]> hget hash1 key1 // 獲取元素的value
"value1"
127.0.0.1:6379[2]> hexists hash1 key1
(integer) 1
127.0.0.1:6379[2]> hset hash1 key2 value2
(integer) 1
127.0.0.1:6379[2]> hlen hash1
(integer) 2
127.0.0.1:6379[2]> hkeys hash1 // 獲取hash1的所有key
1) "key1"
2) "key2"
127.0.0.1:6379[2]> hvals hash1 // 獲取hash1的所有value
1) "value1"
2) "value2"
127.0.0.1:6379[2]> hmget hash1 key1 key2 // 獲取元素
1) "value1"
2) "value2"
127.0.0.1:6379[2]> hgetall hash1 // 獲取key/value
1) "key1"
2) "value1"
3) "key2"
4) "value2"
127.0.0.1:6379[2]> hset hash1 key3 10
(integer) 1
127.0.0.1:6379[2]> hincrby hash1 key3 5 // 將key3的value增加15(僅限整數)
(integer) 15
127.0.0.1:6379[2]> hmset hash1 key4 value4 key5 value5 // 批量添加元素
OK
其他操作dbsize 查看所有key的數目
flushdb 刪除當前選擇數據庫中的所有key
flushall 刪除所有數據庫中的所有key
save: 將數據同步保存到磁盤
bgsave: 異步保存
lastsave: 上次成功保存到磁盤的Unix時間戳
info: 查詢server信息
config: 配置server
slaveof: 改變復制策略設置
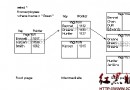
publish-subscriberedis的發布/訂閱機制使用非常簡便, 如下圖:

subscribe chatchannel 訂閱該chatchannel頻道, 則會實時接收到該頻道的消息;
publish chatchannel ‘hello’ 向chatchannel頻道發布消息, 所有訂閱者都能收到.
這種機制, 可以非常方便地使用在類似於聊天室的場景中.
redis持久化redis提供了兩種持久化的方式,分別是RDB(Redis DataBase)和AOF(Append Only File)。
RDB,簡而言之,就是在不同的時間點,將redis存儲的數據生成快照並存儲到磁盤等介質上;
AOF,則是換了一個角度來實現持久化,那就是將redis執行過的所有寫指令記錄下來,在下次redis重新啟動時,只要把這些寫指令從前到後再重復執行一遍,就可以實現數據恢復了。
其實RDB和AOF兩種方式也可以同時使用,在這種情況下,如果redis重啟的話,則會優先采用AOF方式來進行數據恢復,這是因為AOF方式的數據恢復完整度更高。
如果你沒有數據持久化的需求,也完全可以關閉RDB和AOF方式,這樣的話,redis將變成一個純內存數據庫,就像memcache一樣。
RDBRDB方式,是將redis某一時刻的數據持久化到磁盤中,是一種快照式的持久化方法。
redis在進行數據持久化的過程中,會先將數據寫入到一個臨時文件中,待持久化過程都結束了,才會用這個臨時文件替換上次持久化好的文件。正是這種特性,讓我們可以隨時來進行備份,因為快照文件總是完整可用的。
對於RDB方式,redis會單獨創建(fork)一個子進程來進行持久化,而主進程是不會進行任何IO操作的,這樣就確保了redis極高的性能。
如果需要進行大規模數據的恢復,且對於數據恢復的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。
雖然RDB有不少優點,但它的缺點也是不容忽視的。如果你對數據的完整性非常敏感,那麼RDB方式就不太適合你,因為即使你每5分鐘都持久化一次,當redis故障時,仍然會有近5分鐘的數據丟失。所以,redis還提供了另一種持久化方式,那就是AOF。
AOFAOF,英文是Append Only File,即只允許追加不允許改寫的文件。
如前面介紹的,AOF方式是將執行過的寫指令記錄下來,在數據恢復時按照從前到後的順序再將指令都執行一遍,就這麼簡單。
我們通過配置redis.conf中的appendonly yes就可以打開AOF功能。如果有寫操作(如SET等),redis就會被追加到AOF文件的末尾。
默認的AOF持久化策略是每秒鐘fsync一次(fsync是指把緩存中的寫指令記錄到磁盤中),因為在這種情況下,redis仍然可以保持很好的處理性能,即使redis故障,也只會丟失最近1秒鐘的數據。
如果在追加日志時,恰好遇到磁盤空間滿、inode滿或斷電等情況導致日志寫入不完整,也沒有關系,redis提供了redis-check-aof工具,可以用來進行日志修復。
因為采用了追加方式,如果不做任何處理的話,AOF文件會變得越來越大,為此,redis提供了AOF文件重寫(rewrite)機制,即當AOF文件的大小超過所設定的阈值時,redis就會啟動AOF文件的內容壓縮,只保留可以恢復數據的最小指令集。舉個例子或許更形象,假如我們調用了100次INCR指令,在AOF文件中就要存儲100條指令,但這明顯是很低效的,完全可以把這100條指令合並成一條SET指令,這就是重寫機制的原理。
在進行AOF重寫時,仍然是采用先寫臨時文件,全部完成後再替換的流程,所以斷電、磁盤滿等問題都不會影響AOF文件的可用性,這點大家可以放心。
AOF方式的另一個好處,我們通過一個“場景再現”來說明。某同學在操作redis時,不小心執行了FLUSHALL,導致redis內存中的數據全部被清空了,這是很悲劇的事情。不過這也不是世界末日,只要redis配置了AOF持久化方式,且AOF文件還沒有被重寫(rewrite),我們就可以用最快的速度暫停redis並編輯AOF文件,將最後一行的FLUSHALL命令刪除,然後重啟redis,就可以恢復redis的所有數據到FLUSHALL之前的狀態了。是不是很神奇,這就是AOF持久化方式的好處之一。但是如果AOF文件已經被重寫了,那就無法通過這種方法來恢復數據了。
雖然優點多多,但AOF方式也同樣存在缺陷,比如在同樣數據規模的情況下,AOF文件要比RDB文件的體積大。而且,AOF方式的恢復速度也要慢於RDB方式。
如果你直接執行BGREWRITEAOF命令,那麼redis會生成一個全新的AOF文件,其中便包括了可以恢復現有數據的最少的命令集。
如果運氣比較差,AOF文件出現了被寫壞的情況,也不必過分擔憂,redis並不會貿然加載這個有問題的AOF文件,而是報錯退出。這時可以通過以下步驟來修復出錯的文件:
1. 備份被寫壞的AOF文件
2. 運行redis-check-aof –fix進行修復
3. 用diff -u來看下兩個文件的差異,確認問題點
4. 重啟redis,加載修復後的AOF文件
AOF重寫AOF重寫的內部運行原理,我們有必要了解一下。
在重寫即將開始之際,redis會創建(fork)一個“重寫子進程”,這個子進程會首先讀取現有的AOF文件,並將其包含的指令進行分析壓縮並寫入到一個臨時文件中。
與此同時,主工作進程會將新接收到的寫指令一邊累積到內存緩沖區中,一邊繼續寫入到原有的AOF文件中,這樣做是保證原有的AOF文件的可用性,避免在重寫過程中出現意外。
當“重寫子進程”完成重寫工作後,它會給父進程發一個信號,父進程收到信號後就會將內存中緩存的寫指令追加到新AOF文件中。
當追加結束後,redis就會用新AOF文件來代替舊AOF文件,之後再有新的寫指令,就都會追加到新的AOF文件中了。
主從(master-slave)像MySQL一樣,redis是支持主從同步的,而且也支持一主多從以及多級從結構。
主從結構,一是為了純粹的冗余備份,二是為了提升讀性能,比如很消耗性能的SORT就可以由從服務器來承擔。
redis的主從同步是異步進行的,這意味著主從同步不會影響主邏輯,也不會降低redis的處理性能。
主從架構中,可以考慮關閉主服務器的數據持久化功能,只讓從服務器進行持久化,這樣可以提高主服務器的處理性能。
在主從架構中,從服務器通常被設置為只讀模式,這樣可以避免從服務器的數據被誤修改。但是從服務器仍然可以接受CONFIG等指令,所以還是不應該將從服務器直接暴露到不安全的網絡環境中。如果必須如此,那可以考慮給重要指令進行重命名,來避免命令被外人誤執行。
同步原理從服務器會向主服務器發出SYNC指令,當主服務器接到此命令後,就會調用BGSAVE指令來創建一個子進程專門進行數據持久化工作,也就是將主服務器的數據寫入RDB文件中。在數據持久化期間,主服務器將執行的寫指令都緩存在內存中。
在BGSAVE指令執行完成後,主服務器會將持久化好的RDB文件發送給從服務器,從服務器接到此文件後會將其存儲到磁盤上,然後再將其讀取到內存中。這個動作完成後,主服務器會將這段時間緩存的寫指令再以redis協議的格式發送給從服務器。
另外,要說的一點是,即使有多個從服務器同時發來SYNC指令,主服務器也只會執行一次BGSAVE,然後把持久化好的RDB文件發給多個下游。在redis2.8版本之前,如果從服務器與主服務器因某些原因斷開連接的話,都會進行一次主從之間的全量的數據同步;而在2.8版本之後,redis支持了效率更高的增量同步策略,這大大降低了連接斷開的恢復成本。
主服務器會在內存中維護一個緩沖區,緩沖區中存儲著將要發給從服務器的內容。從服務器在與主服務器出現網絡瞬斷之後,從服務器會嘗試再次與主服務器連接,一旦連接成功,從服務器就會把“希望同步的主服務器ID”和“希望請求的數據的偏移位置(replication offset)”發送出去。主服務器接收到這樣的同步請求後,首先會驗證主服務器ID是否和自己的ID匹配,其次會檢查“請求的偏移位置”是否存在於自己的緩沖區中,如果兩者都滿足的話,主服務器就會向從服務器發送增量內容。
增量同步功能,需要服務器端支持全新的PSYNC指令。這個指令,只有在redis-2.8之後才具有。
其他部分事物處理, redis配置的部分, 請參考博文超強、超詳細Redis數據庫入門教程.