MongoDB中的索引和其他數據庫索引類似,也是使用B-Tree結構。MongoDB的索引是在collection級別上的,並且支持在任何列或者集合內的文檔的子列中創建索引。
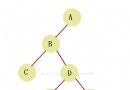
下面是官方給出的一個使用索引查詢和排序的一個結構圖。
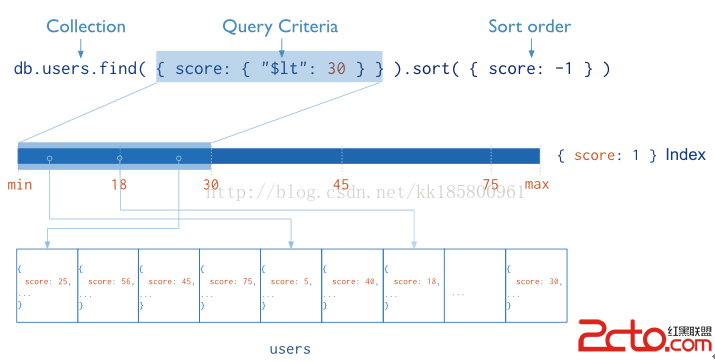
所有的MongoDB集合默認都有一個唯一索引在字段“_id”上,如果應用程序沒有為 “_id”列定義一個值,MongoDB將創建一個帶有ObjectId值的列。(ObjectId是基於 時間、計算機ID、進程ID、本地進程計數器 生成的)

MongoDB 同樣支持在一列或多列上創建升序或降序索引。
MongoDB還可以創建 多鍵索引、數組索引、空間索引、text索引、哈希索引,其屬性可以是唯一性索引、稀疏性索引、TTL(time to live)索引。
索引的限制:
索引名稱不能超過128個字符
每個集合不能超過64個索引
復合索引不能超過31列
MongoDB 索引語法
db.collection.createIndex({
db.collection.ensureIndex({
db.collection.createIndex( { "filed": sort } )
db.collection.createIndex( { "filed": sort , "filed2": sort } )
db.tab.ensureIndex({"id":1})
db.tab.ensureIndex({"id":1} ,{ name:"id_ind"})
db.tab.ensureIndex({"id":1,"name":1},{background:1,unique:1})
db.tab.ensureIndex( { "id" : "hashed" })
創建索引(兩種方法)
filed :為鍵列
sort :為排序。1 為升序;-1為降序。
創建單列索引
創建索引並給定索引名稱
後台創建唯一的復合索引
創建哈希索引
(更多參數 看文章底部)
db.tab.indexStats( { index: "id_ind" } )
db.runCommand( { indexStats: "tab", index: "id_ind" } )
db.tab.getIndexes()
db.system.indexes.find()
(前2個似乎不能用,官方文檔解釋)
(not intended for production deployments)
查看索引
db.tab.totalIndexSize();
查看索引大小
db.tab.reIndex()
db.runCommand({reIndex:"tab"})
重建索引
db.tab.dropIndex(
db.tab.dropIndex("id_1")
db.tab.dropIndexes()
刪除索引
刪除所有索引(注意!)
索引性能測試:
查看索引是否生效,分析查詢性能有沒有提高。先插入10萬數據到集合tab
for(var i=0;1<=100000;i++){
var value=parseInt(i*Math.random());
db.tab.insert({"id":i,"name":"kk"+i,"value":value});
}
不知道是不是虛擬機的原因,插入了10分鐘都未完成!~
自己又打開文件夾查看,一直進不去文件夾。結果客戶端連接斷開了!~查看服務竟然停了!
重啟服務,進去查看行數:96萬!(過後再查看吧!就用這數據測試了!)
db.tab.find().count()
AnalyzeQuery Performance :http://docs.mongodb.org/manual/tutorial/analyze-query-plan/
分析函數
db.tab.find({"name":"kk50000"}).explain()
查詢name=”kk50000”的執行分析
db.tab.find({"name":"kk50000"}).explain("queryPlanner")
db.tab.find({"name":"kk50000"}).explain("Verbosity")
db.tab.find({"name":"kk50000"}).explain("executionStats")
db.tab.find({"name":"kk50000"}).explain("allPlansExecution")
這3種方法執行結果完全包括上面這種的結果
db.tab.find({"name":"kk50000"}).explain() 結果做分析:
"cursor" : "BasicCursor",
"isMultiKey" : false,
"n" : 1,
"nscannedObjects" : 966423,
"nscanned" : 966423,
"nscannedObjectsAllPlans" : 966423,
"nscannedAllPlans" : 966423,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 7555,
"nChunkSkips" : 0,
"millis" : 4677,
"server" : "kk-ad:27017",
"filterSet" : false
游標類型。BasicCurso(掃描), BtreeCursor(索引)
是否多鍵(組合)索引
返回行數
掃描行數
掃描行數
所有計劃掃描的次數
所有計劃掃描的次數
是否在內存中排序
耗時(毫秒)
服務器
現在創建索引:
db.tab.createIndex({"name":1})
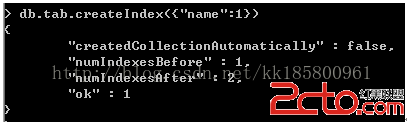
db.tab.find({"name":"kk50000"}).explain() 使用索引的結果
"cursor" : "BtreeCursor name_1",
"isMultiKey" : false,
"n" : 1,
"nscannedObjects" : 1,
"nscanned" : 1,
"nscannedObjectsAllPlans" : 1,
"nscannedAllPlans" : 1,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 1,
"indexBounds" : {
"name" : [
[
"kk50000",
"kk50000"
]
]
},
"server" : "kk-ad:27017",
"filterSet" : false
游標使用索引BtreeCursor = name_1
耗時:1毫秒
上面可以看到,沒使用索引時,耗時4677毫秒,使用索引後,1毫秒!~並且不用全文檔掃描。
索引提示(hint),當前collection創建的索引:
db.tab.ensureIndex({"id":1} ,{name:"id_ind"})
db.tab.ensureIndex({"id":1,"name":1},{background:1,unique:1})
db.tab.ensureIndex( { "name" :"hashed" })
現在查詢 id=5000 的行(結果集為1行)
db.tab.find({"id": 5000}).explain()
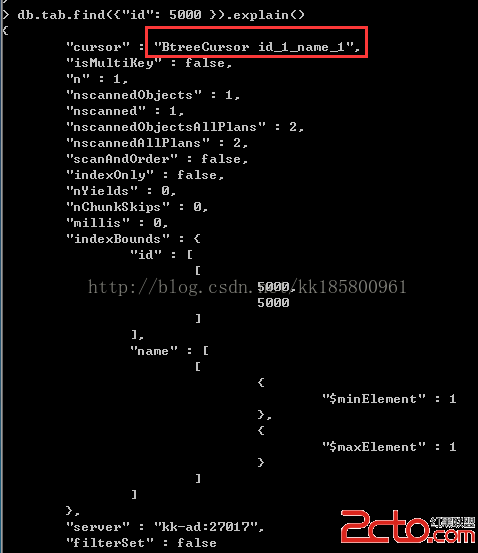
查詢使用的是id和name的復合索引。
"nscannedObjectsAllPlans" : 2,
"nscannedAllPlans" : 2,
現在加上索引提示,強制使用索引:
db.tab.find({"id": 5000}).hint({"id":1}).explain()
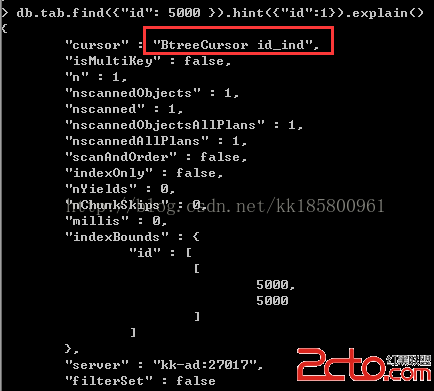
這時使用的是單個鍵列為id的索引。
"nscannedObjectsAllPlans" : 1,
"nscannedAllPlans" : 1,
上面還可以看到,索引有個邊界值“indexBounds”

這個邊界值在復合索引查詢的時候,會導致掃描更多的數據。這是一個bug :wrong index ranges when using compound index on a list
當然我們也可以自己限制邊界值。
db.tab.find().min({"id":5000}).max({ "id":5005})

從上面看,實際只查詢這個邊界的內的數值。再查看執行計劃:
db.tab.find().min({"id":5000}).max({ "id":5005}).explain()
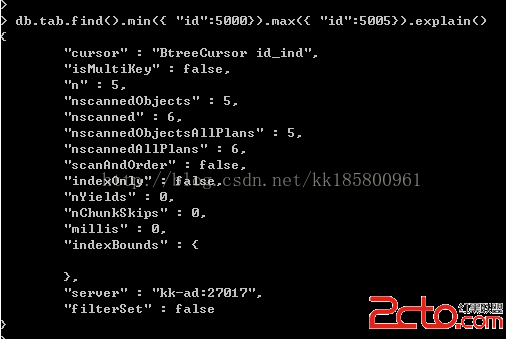
只是5行數據。如果查詢id=5000的,但是索引邊界又有問題,這時可以限制邊界,如:
db.tab.find({"id": 5000 }).min({"id":5000}).max({ "id":5005})
在索引方法中,還有一個方法為cursor.snapshot(),它會確保查詢不會多次返回相同的文檔,即使是寫操作在一個因為文檔大小增長而移動的文檔。但是,snapshot()不能保證插入或者刪除的隔離性。snapshot()是使用在_id鍵列上的索引,因此snapshot()不能使用sort() 或 hint()。
分快照函數析snapshot()的查詢結果:
db.tab.find({"id": 5000}).snapshot().explain()
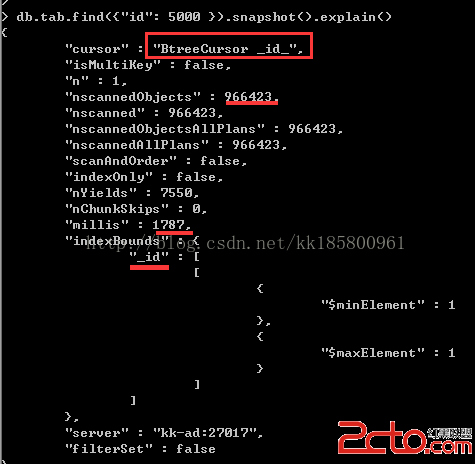
雖然使用了索引“_id”,但是把整個集合都搜索了!~
加索引提示看看,應該是報錯的:
db.tab.find({"id": 5000}).snapshot().hint({"id":1})

果然是出錯:snapshot 不能使用提示。
下面總結索引查詢的一些方法:
Indexing Query Modifiers
db.tab.find({"id": 5000 }).hint({"id":1})
db.tab.find({"id": 5000 })._addSpecial("$hint",{"id":1})
db.tab.find({ $query: {"id": 5000 }, $hint: { "id":1 }})
使用鍵列id的索引查詢id=5000的結果
db.tab.find({"id": 5000 }).snapshot()
db.tab.find({"id": 5000 })._addSpecial( "$snapshot", true )
db.tab.find({ $query: {"id": 5000 }, $snapshot: true })
使用快照的查詢id=5000的結果
db.tab.find({"id": 5000 }).hint({"id":1}).explain()
db.tab.find({"id": 5000})._addSpecial("$explain",1)
db.tab.find({ $query: {"id": 5000 }, $hint: { "id":1 }, $explain: 1})
查看執行計劃信息
索引邊界設置
db.tab.find({"id": 5000 }).max({ "id":5005})
db.tab.find({ $query:{"id": 5000 },$max:{ "id": 5005}})
db.tab.find({"id": 5000 })._addSpecial("$max",{"id": 5005})
db.tab.find({"id": 5000 }).min({ "id":5000}).max({ "id":5005}).explain()
db.tab.find({ $query:{"id": 5000 },$max:{ "id": 5005},$min:{ "id": 5000}})
db.tab.find({"id": 5000 })._addSpecial("$min",{"id": 5000})._addSpecial("$max",{"id": 5005})
摘取了這了的一個總結:http://www.w3cschool.cc/mongodb/mongodb-indexing.html