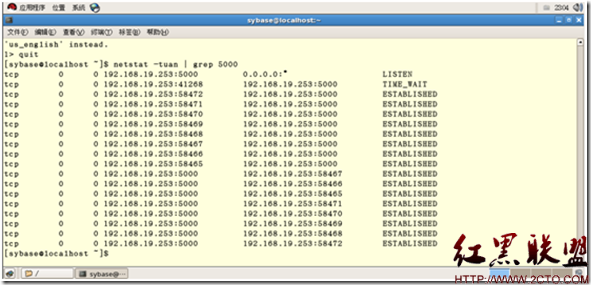
接上一節,我們有了demo數據庫,可惜裡邊的數據集相對都比較小。如果你沒有合適的測試數據集,也沒有可用的生產環境為你提供數據集,怎麼辦?
可以自己去造一張大表,生成隨機數據。這是許多DBA或者開發人員尤其是研究系統性能的開發人員常用的辦法。
建一張表,字段足夠多,如,表名為BIG,有43個字段:
定義如下:
CREATE TABLE "BIG" (
"H0" VARchar(1),
"ID" VARchar(18),
"H02" VARchar(1),
"H031" VARchar(2),
"H032" VARchar(2),
"H041" VARchar(2),
"H042" VARchar(2),
"H051" VARchar(2),
"H052" VARchar(2),
"H061" VARchar(2),
"H062" VARchar(2),
"H071" VARchar(1),
"H072" VARchar(1),
"H081" VARchar(1),
"H082" VARchar(1),
"H09" VARchar(2),
"H10" VARchar(3),
"H11" VARchar(1),
"H12" VARchar(1),
"H13" VARchar(4),
"H14" VARchar(1),
"H15" VARchar(1),
"H16" VARchar(1),
"H17" VARchar(1),
"H18" VARchar(1),
"H19" VARchar(1),
"H20" VARchar(1),
"H21" VARchar(1),
"H22" VARchar(1),
"H23" VARchar(1),
"HA0" VARchar(1),
"HA1" VARchar(2),
"HA2" VARchar(2),
"HA3" VARchar(1),
"HA4" VARchar(1),
"HA5" VARchar(1),
"HA6" VARchar(1),
"HA7" VARchar(1),
"HA8" VARchar(1),
"HA9" VARchar(1),
"HA10" VARchar(3),
"HA11" VARchar(1),
"HA20" VARchar(2)
);
我們使用比較直接而且笨的辦法,插入隨機數據,但是經過實測,發現性能極其低下,最後我已經無法忍受了。其腳本如下:
BEGIN
DECLARE i INT;
SET i = 1;
WHILE i<=1000000 LOOP
INSERT INTO "BIG" VALUES (
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48),
char( cast (rand() * 10 as int) + 48)
);
SET i = i + 1;
if ( i % 2000 = 0) then
COMMIT;
END IF;
END LOOP;
END;
1000000條數據,幾個小時能弄完。
有沒有快捷的方式呢?
可以寫一小段程序,生成一個數據文件,再後再用INPUT或者LOAD來加載
這一小段程序如下, 用C實現:
#include "stdafx.h"
#include <stdio.h>
#include <time.h>
int getN()
{
return rand() % 10;
}
static void gen_data(FILE* f, int n, int colCount)
{
// file : d:\work\demo\BIG.txt, default colCount is 43
for (int i=0; i<n; i++)
{
for (int j=0; j<colCount-1; j++)
{
fprintf(f, "%ld,", getN());
}
fprintf(f, "%ld\n", getN());
}
}
int main(int argc,char** argv)
{
srand( (unsigned)time( NULL ) );
printf("rand = %ld\n", getN());
long begin = (long) time(NULL);
FILE * f = fopen("d:\\asa120\\BIG.txt", "wt");
gen_data(f, 1000000, 43);
fclose(f);
printf("generate finished...\n");
printf("time consumed: %ld \n", (long)time(NULL) - begin);
return 0;
}
The LOAD TABLE statement adds rows into a table; it doesn't replace them.
Loading data using the LOAD TABLE statement (without the WITH ROW LOGGING and WITH CONTENT LOGGING options) is considerably faster than using the INPUT statement.
看來,INPUT操作比LOAD操作,多了些LOGGING的操作,所以費時間。
痛苦的LOAD TABLE命令開始了,
試了好幾個用法:
最後,下述命令通過, 大概花了10來秒鐘完成100萬條數據的加載,速度非常快。
LOAD TABLE BIG (H0',', ID',', H02',', H031',', H032',', H041',', H042',', H051',', H052',', H061',', H062',', H071',', H072',', H081',', H082',', H09',', H10',', H11',', H12',', H13',', H14',', H15',', H16',', H17',', H18',', H19',', H20',', H21',', H22',', H23',', HA0',', HA1',', HA2',', HA3',', HA4',', HA5',', HA6',', HA7',', HA8',', HA9',', HA10',', HA11',', HA20'\X0A') from 'd:\\asa120\\BIG.txt' ESCAPES OFF QUOTES OFF NOTIFY 100000 WITH CHECKPOINT ON
我估計load table命令在這個版本裡可能功能不是很完善。
比如,一個簡單的數據文件內容如下:
'123','456'
'222','111'
使用INPUT命令,很容易就載入表abc成功。
input into abc from 'd:\\asa120\\abc.txt' format ascii escapes on escape character '\\' delimited by ',' encoding 'GBK';
可是用load table就失敗,默認值也出錯。
truncate table abc; load table abc(col1 ',', col2 '0x0A') from 'd:\\asa120\\abc.txt' escapes off;結果報錯:Non-space text found after ending quote character for an enclosed field ......
select ID, sum(case when ID<>'0' then cnt end) c1, sum(case when ha3='1' then cnt end) c2, sum(case when ha3='2' then cnt end) c4, sum(case when ha3='3' then cnt end) c6, sum(case when ha3='4' then cnt end) c8 from ( select substr(ID,1,6) ID,count(*)cnt,ha3 from BIG group by id,ha3 ) A group by ID order by ID